คุณอาจคิดว่าชื่อบทนี้หมายความว่าถ้าคุณวัดอย่างแม่นยำ คุณก็จะได้ค่าที่แม่นยำ และถ้าไม่แม่นยำก็จะไม่ได้ค่าแม่นยำ แต่มันหมายถึงสิ่งที่ละเอียดอ่อนกว่านั้นมาก—วิธีการที่คุณเลือกใช้วัดสิ่งต่างๆ มีผลควบคุมอย่างมากว่าอะไรจะเกิดขึ้น ผมขอย้อนเล่าเรื่อง ที่ Eddington เล่าเกี่ยวกับชาวประมงที่ออกไปจับปลาด้วยแห พวกเขาตรวจสอบขนาดของปลาที่จับได้และ สรุปว่าปลาในทะเลมีขนาดต่ำสุดตามที่กำหนด เครื่องมือที่คุณใช้ย่อมส่งผลต่อสิ่งที่คุณเห็นอย่างชัดเจน
ตัวอย่างที่เห็นได้ชัดในปัจจุบันของผลกระทบนี้คือการใช้ตัวเลขกำไรขาดทุนในงบการเงินรายไตรมาสเพื่อประเมินว่าบริษัทดำเนินงานได้ดีแค่ไหน ซึ่งส่งผลให้บริษัทสนใจแต่ผลกำไรระยะสั้นเป็นหลัก และไม่ค่อยใส่ใจกับผลกำไรระยะยาวเลย
ถ้าในระบบการให้คะแนนทุกคนเริ่มต้นที่ 95% แน่นอนว่ามีอะไรที่พนักงานจะทำเพื่อเพิ่มคะแนนได้น้อยมาก แต่มีหลายอย่างที่จะทำให้คะแนนลดลง ดังนั้นกลยุทธ์ที่ชัดเจนของพนักงานก็คือการเล่นอย่างปลอดภัย และค่อยๆ ไต่ขึ้นไปสู่ระดับสูง สุดท้ายพอถึงระดับสูง แม้ว่าคุณอาจอยากจะเลื่อนขั้นคนที่กล้าเสี่ยง แต่กลุ่มคนที่คุณมีให้เลือกนั้นส่วนใหญ่กลับเป็นพวกหัวอนุรักษ์นิยม!
ระบบการให้คะแนนในช่วงแรกอาจกำจัดคนที่คุณต้องการในระยะหลังออกไปอย่างพอดี
ถ้าคุณเริ่มต้นด้วยระบบการให้คะแนนที่คนทั่วไปได้คะแนนเฉลี่ยประมาณ 50% มันก็จะสมดุลมากขึ้น และถ้าคุณต้องการเน้นการกล้าเสี่ยง คุณอาจเริ่มต้นที่คะแนนเริ่มต้น 20% หรือน้อยกว่านั้น เพื่อกระตุ้นให้คนพยายามเพิ่มคะแนนด้วยการกล้าเสี่ยง เนื่องจากถ้าพวกเขาล้มเหลวก็เสียอะไรไม่มาก แต่ถ้าสำเร็จก็ได้กำไรมหาศาล สำหรับการส่งเสริมการกล้าเสี่ยงในองค์กร คุณต้องสนับสนุนให้มีการเสี่ยงในระดับที่เหมาะสมในช่วงแรก ควบคู่ไปกับการเลื่อนขั้น เพื่อให้คนกล้าเสี่ยงบางคนสามารถขึ้นมาอยู่ในระดับสูงได้ในที่สุด
ในบรรดาสิ่งที่คุณเลือกวัดได้นั้น บางอย่างเป็นการวัดแบบแข็ง คือวัดได้แน่นอน เช่น ความสูงและน้ำหนัก ในขณะที่บางอย่างเป็นการวัดแบบอ่อน เช่น ทัศนคติทางสังคม มักจะมีแนวโน้มที่เราจะหยิบการวัดแบบแข็งที่วัดได้แน่นอนมาใช้ ถึงแม้ว่ามันอาจจะไม่เกี่ยวข้องเลยเมื่อเทียบกับการวัดแบบอ่อน ซึ่งในระยะยาวอาจจะเกี่ยวข้องกับเป้าหมายของคุณมากกว่ามาก ความแม่นยำ ของการวัดมักถูกสับสนกับ ความเกี่ยวข้อง ของการวัด มากกว่าที่คนส่วนใหญ่จะเชื่อเสียอีก การที่การวัดหนึ่งมีความแม่นยำ ทำซ้ำได้ และทำได้ง่าย ไม่ได้หมายความว่าควรทำการวัดนั้น ในทางกลับกัน การวัดที่ด้อยกว่าแต่เกี่ยวข้องกับเป้าหมายของคุณมากกว่าอาจจะดีกว่ามาก ตัวอย่างเช่น ในโรงเรียน การวัดการฝึกฝน (training) ทำได้ง่าย แต่การวัดการศึกษา (education) ทำได้ยาก ดังนั้นคุณจึงมักเห็นข้อสอบปลายภาคที่เน้นส่วนของการฝึกฝนและละเลยส่วนของการศึกษาอย่างมาก
ขอให้ผมหันมาพูดถึงผลกระทบอีกอย่างของระบบการวัด โดยจะอธิบายผ่านการนิยามและการใช้ iq สิ่งที่ทำคือสร้างชุดคำถามที่ดูสมเหตุสมผล—สมเหตุสมผลจากประสบการณ์ที่ผ่านมา—แล้วนำไปทดสอบกับกลุ่มตัวอย่างเล็กๆ คำถามไหนที่มีความสัมพันธ์ภายในกับข้ออื่นๆ ก็จะถูกเก็บไว้ ส่วนคำถามที่ไม่ค่อยสัมพันธ์กันก็จะถูกตัดทิ้ง จากนั้น แบบทดสอบที่ปรับปรุงแล้วจะถูกปรับเทียบ (calibrate) โดยใช้กับกลุ่มตัวอย่างที่ใหญ่ขึ้นมาก อย่างไร? ก็แค่เอาคะแนนสะสม (จำนวนคนที่ได้คะแนนต่ำกว่าค่าที่กำหนด) มาพล็อตบนกระดาษความน่าจะเป็น ซึ่งแกนนอนคือความน่าจะเป็นสะสมของการแจกแจงแบบปกติ (normal distribution) จากนั้น จุดที่คะแนนจริงสะสมตกที่เปอร์เซ็นต์ต่างๆ จะถูกโยงผ่านตารางเทียบค่า ไปยังจุดที่สอดคล้องกันบนเส้นโค้งความน่าจะเป็นปกติสะสม ผลลัพธ์ที่ได้คือเราพบว่าความฉลาด (intelligence) มีการแจกแจงแบบปกติในประชากร! แน่นอนว่ามันต้องเป็นแบบนั้นอยู่แล้ว เพราะมันถูกทำให้เป็นแบบนั้น! ยิ่งไปกว่านั้น พวกเขายังนิยามว่าความฉลาดคือสิ่งที่ถูกวัดโดยข้อสอบที่ปรับเทียบแล้ว และถ้านั่นคือนิยามของความฉลาด แล้วความฉลาดก็ต้องมีการแจกแจงแบบปกติโดยธรรมชาติ แต่ถ้าคุณคิดว่าความฉลาดอาจจะไม่ใช่สิ่งที่ข้อสอบที่ปรับเทียบแล้ววัดได้พอดี คุณก็มีสิทธิ์ที่จะสงสัยว่าความฉลาดจะมีการแจกแจงแบบปกติในประชากรหรือไม่ ย้ำอีกครั้ง คุณได้สิ่งที่คุณวัด และการประกาศว่ามันเป็นการแจกแจงแบบปกตินั้นเป็นเพียงสิ่งประดิษฐ์ (artifact) ของวิธีการวัด และแทบไม่มีความสัมพันธ์กับความเป็นจริงเลย
ในการออกข้อสอบปลายภาคของวิชาหนึ่ง สมมติว่าวิชาแคลคูลัส ผมสามารถทำให้ได้การกระจายของเกรดแทบจะเท่าไหร่ก็ได้ตามที่ต้องการ ถ้าผมสามารถสร้างข้อสอบที่ยากเท่ากันทุกข้อ นักเรียนแต่ละคนก็มักจะตอบถูกหมดทุกข้อหรือผิดหมดทุกข้อ ดังนั้นผมจะได้การกระจายของเกรดที่พุ่งสูงที่ปลายทั้งสองข้าง Figure 29.1 ในทางตรงกันข้าม ถ้าผมถามข้อข้อง่ายๆ สองสามข้อ ปานกลางหลายข้อ และยากมากสองสามข้อ ผมก็จะได้ การกระจายแบบปกติทั่วๆ ไป สองสามคนที่ปลายแต่ละด้าน และเกรดส่วนใหญ่อยู่ตรงกลาง Figure 29.2 เห็นได้ชัดว่าถ้าผมรู้จักชั้นเรียน ผมก็สามารถสร้างการกระจายแบบที่ต้องการได้เกือบทุกแบบ โดยปกติตอนปลายภาค ผมจะกังวลมากที่สุดเกี่ยวกับจุดแบ่งระหว่างผ่านกับตก และจะออกข้อสอบเพื่อให้มั่นใจว่าผมรู้ว่าต้องตัดสินใจอย่างไร รวมถึงมีหลักฐานหนักแน่นไว้ในกรณีที่มีการร้องเรียน
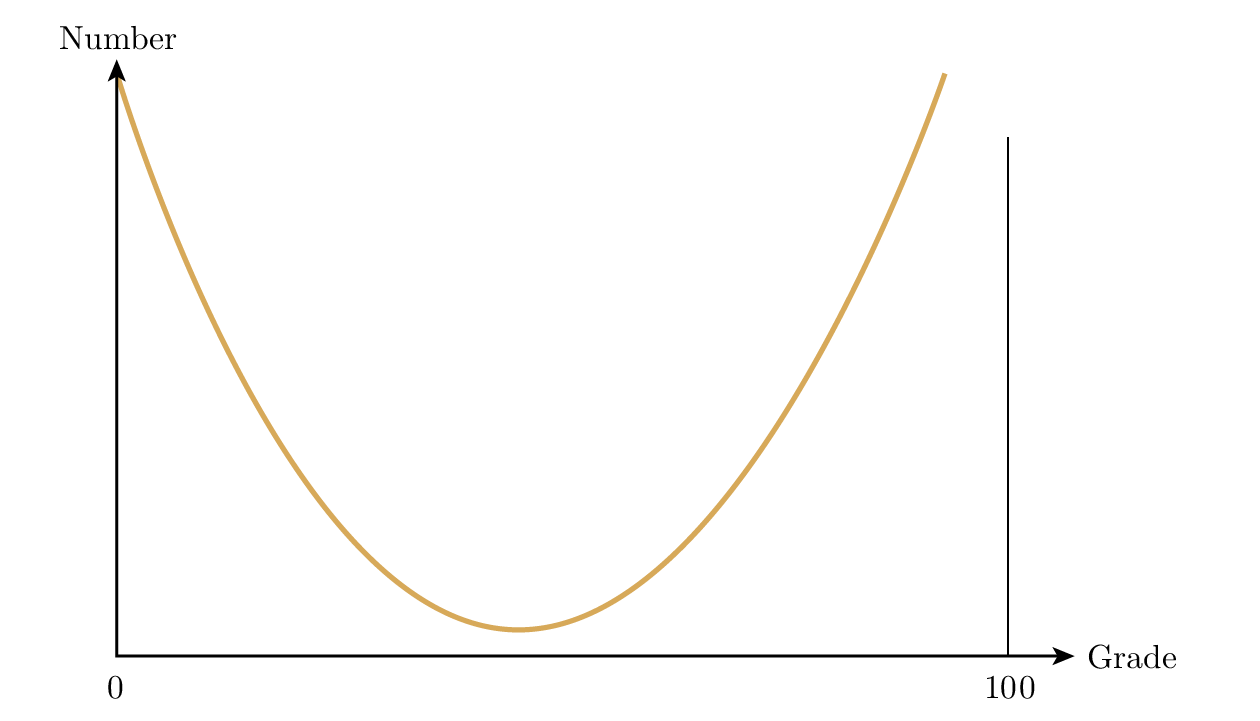
Figure 29.1—ผลลัพธ์ของข้อสอบที่ยากเท่ากันทุกข้อ
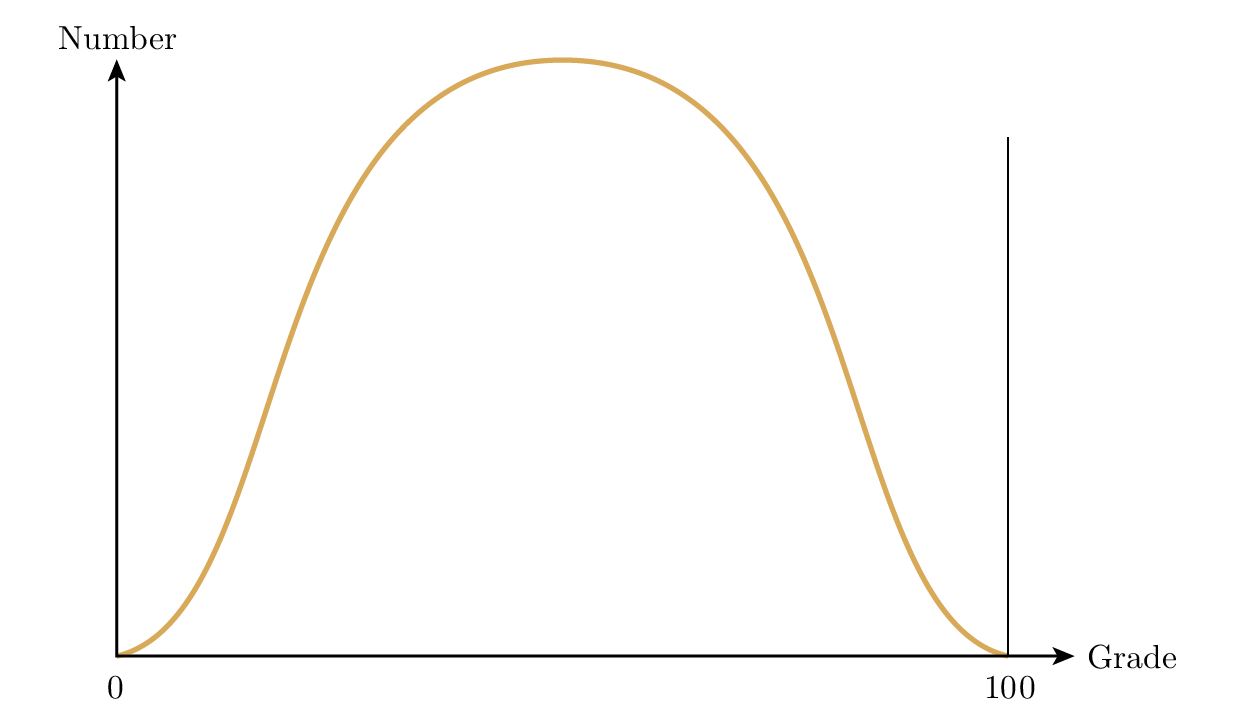
Figure 29.2—ผลลัพธ์ของข้อสอบที่สมดุลมากขึ้น
อีกแง่มุมหนึ่งของระบบการให้คะแนนคือช่วงไดนามิก (dynamic range) สมมติว่าคุณมีสเกล 1 ถึง 10 โดยที่ 5 คือค่าเฉลี่ย คนส่วนใหญ่จะให้คะแนนแค่ 4, 5 และ 6 และแทบจะไม่กล้าไปถึงปลายสุดอย่าง 1 หรือ 9 เลย ถ้าคุณให้ 6 กับสิ่งที่คุณชอบ แต่ผมใช้ ช่วงไดนามิก ทั้งหมดและให้ 2 กับสิ่งที่ผมไม่ชอบ ผลที่เกิดขึ้นคือถึงแม้เราจะมีความคิดเห็นที่แตกต่างกันพอๆ กัน ผลรวมของคะแนนจะกลายเป็น 6 + 2 = 8 และค่าเฉลี่ยจะเป็น 4 —ความคิดเห็นของผมลบล้างของคุณจนหมด! ในการใช้ระบบการให้คะแนน คุณควรพยายามใช้ช่วงไดนามิกทั้งหมด และถ้าคุณทำเช่นนั้น คุณจะมีผลต่อค่าเฉลี่ยสุดท้ายมากขึ้นมาก—ภายใต้เงื่อนไขที่ว่ามันทำโดยการหาค่าเฉลี่ยแบบตาบอด อย่างที่มักเป็นในกรณีส่วนใหญ่ จำไว้ว่า ทฤษฎีการเข้ารหัส (coding theory) บอกว่า เอนโทรปี (entropy หรือค่าเฉลี่ยของความประหลาดใจ) จะมีค่าสูงสุดเมื่อการกระจายเป็นแบบสม่ำเสมอ (uniform) คุณจะมีข้อมูลมากที่สุดเมื่อมีการใช้เกรดทุกตัวอย่างเท่าเทียมกัน อย่างที่คุณอาจจำได้จากบทที่ 13 เรื่องทฤษฎีสารสนเทศ
ถ้าคุณมองการให้เกรดในวิชาเรียนเป็น ช่องทางการสื่อสาร (communication channel) อย่างที่เพิ่งกล่าวไป การใช้ ทุก เกรดอย่างเท่าเทียมกันจะสื่อสารข้อมูลได้มากที่สุด—ในขณะที่การใช้เกรดสูงสุดเพียงสองเกรดอย่าง A และ B ในบัณฑิตวิทยาลัยส่วนใหญ่ จะลดปริมาณข้อมูลที่ส่งลงอย่างมาก ผมเข้าใจว่าโรงเรียนนายเรือสหรัฐฯ ใช้การจัดอันดับในชั้นเรียน และในแง่หนึ่งนี่คือการป้องกันอย่างเดียวจาก "ภาวะเงินเฟ้อของเกรด" (grade inflation) และการไม่ใช้ช่วงไดนามิกทั้งหมดของสเกลอย่างเท่าเทียมกัน ซึ่งจะช่วยสื่อสารข้อมูลได้มากที่สุด ด้วยตัวอักษรเกรดที่กำหนดไว้ ข้อเสียหลักของการใช้อันดับเป็นเกรดคือ โดยบังเอิญอาจมีคนเก่งทุกคนอยู่ในชั้นเรียนเดียวกัน แต่ก็ต้องมีใครสักคนที่อยู่ท้ายสุด!
นอกจากนี้ยังมีเรื่องของการดึงดูดคนเข้าสู่สาขาในช่วงแรก เห็นได้ชัดในทางจิตวิทยาว่าคนที่เข้าสู่สาขานี้ มีความคิดที่ยุ่งเหยิงมากกว่าศาสตราจารย์ทั่วไปและนักศึกษาทั่วไปในมหาวิทยาลัย—ไม่ใช่ว่าตัววิชาทำให้เป็นอย่างนั้น แม้ผมจะสงสัยว่ามันช่วยทำให้นักศึกษายุ่งเหยิงยิ่งขึ้น แต่มันเป็นการคัดเลือกตั้งแต่แรกที่ทำให้เกิดสิ่งนี้ ในทำนองเดียวกัน วิทยาศาสตร์แบบแข็งและแบบอ่อนก็มีแรงดึงดูดและแรงผลักที่ขึ้นอยู่กับ ลักษณะที่รับรู้ได้ในตอนแรก ของสาขานั้นๆ และไม่จำเป็นต้องขึ้นอยู่กับลักษณะที่แท้จริงของสาขา ดังนั้นคนจึงมักจะเข้าสู่สาขาที่จะเอื้อต่อลักษณะเฉพาะของพวกเขา ตามที่พวกเขารับรู้ได้ และเมื่ออยู่ในสาขานั้นแล้ว ลักษณะเหล่านี้ก็มักจะถูกเสริมให้แข็งแกร่งยิ่งขึ้นไปอีก ผลลัพธ์: คนที่เชี่ยวชาญเฉพาะทางสูงแต่ขาดความสมดุล—ซึ่งมักจำเป็นต่อการประสบความสำเร็จในสถานการณ์ปัจจุบัน
ในคณิตศาสตร์และวิทยาการคอมพิวเตอร์ ก็เกิดผลกระทบจากการคัดเลือกในช่วงแรกเช่นเดียวกัน ในช่วงแรกของคณิตศาสตร์จนถึงแคลคูลัส รวมถึงวิทยาการคอมพิวเตอร์ เกรดมีความสัมพันธ์อย่างใกล้ชิดกับความสามารถในการจัดการรายละเอียดจำนวนมากด้วยความน่าเชื่อถือสูง แต่ในระยะหลัง โดยเฉพาะในคณิตศาสตร์ คุณสมบัติที่จำเป็นต่อความสำเร็จเปลี่ยนไป มันกลายเป็นการพิสูจน์ทฤษฎีบท รูปแบบของการให้เหตุผล และความสามารถในการคาดเดาผลลัพธ์ใหม่ ทฤษฎีบทใหม่ และนิยามใหม่ที่สำคัญ และต่อมาก็คือความสามารถในการมองเห็นภาพรวมทั้งหมดของสาขา ไม่ใช่แค่เป็นส่วนย่อยๆ แต่กระบวนการให้เกรดในช่วงแรกได้กำจัดคนที่คุณอาจต้องการออกไปเป็นอย่างมาก ซึ่งเป็นคนที่จำเป็นในระยะหลัง! มันคล้ายกันมากในวิทยาการคอมพิวเตอร์ ที่ความสามารถในการรับมือกับรายละเอียดการเขียนโปรแกรมจำนวนมากเอื้อต่อสมองแบบหนึ่ง ซึ่งมักมีความสัมพันธ์เชิงลบกับการมองเห็นภาพใหญ่
แผนกทรัพยากรบุคคลก็มีผลต่อว่าใครจะถูกดึงเข้ามาในระบบ ถ้ามีการรับสมัครงานวิจัย พนักงานแผนกบุคคลทั่วไปในองค์กรใหญ่ก็มักจะไม่ต้องการคนที่ใช่ นักวิจัยที่ดี เนื่องจากเกณฑ์คือพวกเขามี ความคิดสร้างสรรค์ (originality) ในวิทยาศาสตร์และวิศวกรรม ซึ่งมักหมายความว่าพวกเขาก็มีความคิดสร้างสรรค์ในแง่อื่นๆ ของพฤติกรรมและการแต่งตัวเช่นกัน—ซึ่งหมายความว่าพวกเขาไม่ถูกใจผู้รับสมัครงานทั่วไปจากแผนกบุคคล ดังนั้น เช่นที่ Bell Telephone Laboratories ปกตินักวิจัยจะออกไปทำการรับสมัครงานสำหรับสายงานวิจัยด้วยตัวเอง และแผนกบุคคลก็แค่สะดุ้ง! นี่ไม่ใช่ประเด็นเล็กๆ น้อยๆ การรับสมัครงานในรุ่นหนึ่งเป็นตัวกำหนดรุ่นต่อไปขององค์กร
นอกจากนี้ยังมีลักษณะที่เป็นอันตรายของการเลื่อนขั้นในระบบส่วนใหญ่ ในระดับสูง สมาชิกปัจจุบันจะเป็นผู้เลือกรุ่นต่อไป—และพวกเขา มักจะมีแนวโน้มอย่างมาก ที่จะเลือกคนที่เหมือนกับตัวเอง คนที่พวกเขาจะรู้สึกสบายใจด้วย คณะกรรมการบริหารของบริษัทมีอำนาจควบคุมอย่างมากต่อผู้บริหารและกรรมการคนต่อไปที่ถูกเสนอชื่อเข้าชิงตำแหน่ง (ซึ่งผลลัพธ์มักจะเกิดขึ้นโดยอัตโนมัติไม่มากก็น้อย) คุณมักจะได้การแต่งงานในหมู่ญาติ (inbreeding)—แต่คุณก็มักจะได้บุคลิกภาพขององค์กรเช่นกัน ดังนั้น วิธีการเลื่อนขั้นที่พบบ่อยเกินไปคือการเลือกโดยคนที่อยู่ภายในในระดับสูงขององค์กร ซึ่งมีทั้งข้อดีและข้อเสีย นี่ยังคงอยู่ในหัวข้อ "คุณได้สิ่งที่คุณวัด" เพราะมันเกี่ยวข้องกับเรื่องของการประเมินอย่างแน่นอน และเกณฑ์ที่ใช้ แม้จะไม่รู้ตัว ก็ยังคงมีอยู่
ในอดีตอันไกล เพื่อต่อสู้กับการแต่งงานในหมู่ญาตินี้ ภาควิชาคณิตศาสตร์ส่วนใหญ่ (หัวข้อที่ผมคุ้นเคยมากกว่าภาควิชาอื่นๆ) มีกฎทั่วไปว่าพวกเขาจะไม่จ้างบัณฑิตของตัวเอง ปัจจุบันกฎนี้ไม่ค่อยถูกนำมาใช้เท่าที่ผมเห็น—ค่อนข้างตรงกันข้าม ดูเหมือนจะมีแนวโน้มที่จะจ้างบัณฑิตของตัวเองมากกว่าคนนอก มีหลายครั้งที่ภาควิชาเศรษฐศาสตร์มีการแต่งงานในหมู่ญาติกันมากจนผู้บริหารระดับสูงของมหาวิทยาลัยต้องเข้ามาแทรกแซง และดำเนินการจ้างงานเหนือศพของศาสตราจารย์ อย่างที่ว่า เพื่อให้ได้ความสมดุลที่สมเหตุสมผลของความคิดเห็นที่แตกต่างในมหาวิทยาลัย เหตุการณ์เดียวกันนี้ก็เกิดขึ้นในภาควิชาจิตวิทยา นิติศาสตร์ และไม่ต้องสงสัยในภาควิชาอื่นๆ ด้วย
ดังที่เพิ่งกล่าวไป ระบบการให้คะแนนที่ให้คนที่อยู่ "ข้างใน" เป็นผู้เลือกรุ่นต่อไปมีทั้งข้อดีและข้อเสีย และจำเป็นต้องถูกจับตามองอย่างใกล้ชิดเพื่อป้องกันการแต่งงานในหมู่ญาติที่มากเกินไป การแต่งงานในหมู่ญาติบางส่วนหมายถึงมุมมองร่วมกัน และการดำเนินงานที่ราบรื่นมากขึ้นในแต่ละวัน แต่ก็อาจจะไม่มีการเปลี่ยนแปลงที่ยิ่งใหญ่ในอนาคต ผมสงสัยว่าในอนาคต ที่ผมเชื่อว่าการเปลี่ยนแปลงจะเป็นสภาวะปกติของสิ่งต่างๆ สิ่งนี้จะกลายเป็นปัญหาที่ร้ายแรงกว่าที่เคยเป็นมาในอดีต—และมันก็เป็นปัญหาในอดีตอย่างแน่นอน!
ผมหวังว่าคุณคงเข้าใจว่าผมไม่ได้พยายามจะพูดจาตำหนิติเตียนอะไรจนเกินไป แต่กำลังพยายามอธิบายหัวข้อของบทนี้—คุณได้สิ่งที่คุณวัด สิ่งนี้แทบจะไม่เคยถูกคิดโดยคนที่ตั้งระบบการให้คะแนน การวัด หรือการบันทึกสิ่งต่างๆ เลย และในระยะยาวมันกลับมีผลกระทบมหาศาลต่อทั้งระบบ—โดยปกติจะไปในทิศทางที่พวกเขาไม่เคยคิดมาก่อน!
แม้ว่าการวัดจะแย่อย่างชัดเจนเมื่อทำได้ไม่ดี แต่เราก็หนีไม่พ้นที่จะต้องทำการวัด การให้คะแนนสิ่งต่างๆ คน ฯลฯ ในเวลาใดเวลาหนึ่งจะมีคนเพียงคนเดียวที่เป็นหัวหน้าองค์กรได้ และในการคัดเลือกก็ต้องมีการลดทอนลงมาเป็นสเกลการให้คะแนนอย่างง่ายเพื่อให้สามารถเปรียบเทียบกันได้ ไม่สำคัญว่ามนุษย์จะซับซ้อนอย่างน้อยเท่ากับเวกเตอร์ และอาจจะซับซ้อนยิ่งกว่าเมทริกซ์หรือเทนเซอร์ของตัวเลขเสียอีก มนุษย์ที่ซับซ้อน บวกกับผลกระทบของสภาพแวดล้อมที่พวกเขาทำงานอยู่ จะต้องถูกลดทอนลงมาเป็นการวัดอย่างง่ายที่ทำให้เกิดลำดับของตัวเลือก สิ่งนี้อาจเกิดขึ้นภายในจิตใจ โดยไม่ต้องอาศัยการคิดอย่างมีสติ แต่มันต้องเกิดขึ้นไม่ว่าคุณจะเชื่อในการให้คะแนนคนหรือไม่ก็ตาม—ไม่มีทางหนีรอดในสังคมใดๆ ที่มีความแตกต่างในด้านยศถาบรรดาศักดิ์ อำนาจในการจัดการ หรือคุณลักษณะอื่นใดที่คุณต้องการ แม้แต่ในรายการบันเทิง ก็จะต้องมีผู้แสดงคนแรกและคนสุดท้าย—ทุกคนไม่สามารถถูกจัดให้เท่าเทียมกันได้ คุณอาจเกลียดการให้คะแนนคน อย่างที่ผมเกลียด แต่มันต้องเกิดขึ้นเป็นประจำในสังคมของเรา และในสังคมใดๆ ที่ไม่เท่าเทียมกันในทุกจุด สิ่งนี้ก็ต้องเกิดขึ้นบ่อยมาก คุณควรตระหนักถึงเรื่องนี้และเรียนรู้ที่จะทำงานนี้ให้มีประสิทธิภาพมากกว่าที่คนส่วนใหญ่ทำ—พวกเขาเพียงแค่เลือกแล้วไปต่อ แทนที่จะให้ความสนใจอย่างรอบคอบต่อกระบวนการทั้งหมด รวมถึงการสังเกตคนอื่นที่ทำสิ่งนี้และเรียนรู้จากพวกเขา
ถึงตอนนี้ ผมหวังว่าคุณคงเห็นแล้วว่าระดับการวัด (scales of measurement) แบบต่างๆ ส่งผลต่อสิ่งที่เกิดขึ้นอย่างไร สิ่งเหล่านี้เป็นพื้นฐาน แต่มักจะได้รับความสนใจน้อยมาก เพื่อเสริมสิ่งที่ผมได้พูดไป ผมจะเล่าตัวอย่างเพิ่มเติมว่าระดับการวัดส่งผลต่อระบบอย่างไร
แผ่นดินไหวมักถูกวัดด้วยมาตราริกเตอร์ (Richter scale) ซึ่งใช้ log ของปริมาณพลังงานโดยประมาณในแผ่นดินไหว ผมไม่ได้บอกว่านี่เป็นสเกลการวัดที่ผิด แต่ผลของมันคือคุณจะมีแผ่นดินไหวขนาดใหญ่จริงๆ ไม่กี่ครั้ง คือ 7 และ 8 และแผ่นดินไหวเล็กๆ จำนวนมาก คือ 1 และ 2 ลองคิดดูสิ ผมไม่รู้ว่าการกระจายตามสเกลของธรรมชาติ (Mother Nature) นั้นเป็นอย่างไร แต่ผมสงสัยว่าธรรมชาติจะใช้มาตราริกเตอร์ การแปลงเชิงเส้น อย่างเช่นจากฟุตเป็นเมตร ไม่ใช่เรื่องร้ายแรง แต่การแปลงสเกลแบบไม่เชิงเส้น (nonlinear scale transformation) เป็นอีกเรื่องหนึ่ง ส่วนใหญ่แล้วเราวัดสิ่งที่มากระตุ้นมนุษย์ด้วยสเกลแบบ log แต่สำหรับน้ำหนักและส่วนสูงเราใช้สเกลเชิงเส้น สเกลเชิงเส้นทำให้บวกกันได้ง่าย แต่สเกลไม่เชิงเส้นไม่ได้ให้คุณสมบัตินี้ ตัวอย่างเช่น ในการวัดขนาดของฝูงสัตว์ คุณมักจะนับจำนวนตัวในฝูง ทำให้คุณมีสมบัติการบวกได้—การนำฝูงสองฝูงมารวมกันจะได้ปริมาณที่ถูกต้องของฝูงรวม ถ้าคุณมีฝูง 3 ตัวแล้วเพิ่มอีก 3 ตัวก็เป็นเรื่องหนึ่ง แต่ถ้าคุณมีฝูง 1,000 ตัวแล้วเพิ่มอีก 3 ตัวก็เป็นอีกเรื่องหนึ่ง—ดังนั้นสมบัติการบวกของจำนวนสัตว์ในฝูงจึงไม่ใช่การวัดที่เหมาะสมเสมอไป ในกรณีนี้ เปอร์เซ็นต์การเปลี่ยนแปลง (percentage change) อาจมีข้อมูลมากกว่า
แล้วคุณจะตัดสินใจเลือกสเกลไหนมาใช้วัดสิ่งต่างๆ? ผมไม่มีคำตอบง่ายๆ จริงๆ แล้วผมมีข้อสังเกตที่แย่ๆ ว่า ในขณะที่สเกลการวัดหนึ่งเหมาะกับข้อสรุปแบบหนึ่งในสาขาหนึ่ง แต่สเกลการวัดอีกแบบอาจจะเหมาะสมกว่าสำหรับการตัดสินใจอีกแบบในสาขาเดียวกันนั้น! แต่เรื่องนี้กลับไม่ค่อยได้รับการยอมรับและนำมาใช้สักเท่าไหร่! แน่นอน คุณอาจสังเกตว่าบางครั้งเราเปลี่ยนสเกลเงียบๆ เมื่อเราใช้สูตรที่กำหนด แต่จะใช้สเกลการวัดแบบไหนเป็นเรื่องที่ตัดสินใจได้ยากในแต่ละกรณี ขึ้นอยู่กับสาขาและทฤษฎีที่มีอยู่ รวมถึงทฤษฎีใหม่ที่คุณหวังว่าจะค้นพบ! ทั้งหมดนี้อาจไม่ช่วยคุณมากนักในสถานการณ์ใดสถานการณ์หนึ่ง
ยังมีอีกเรื่องที่ผมพูดถึงในบทก่อนหน้าและต้องกลับมาพูดอีกครั้ง นั่นคือความรวดเร็วในการตอบสนองของผู้คนต่อการเปลี่ยนแปลงในระบบการให้คะแนน ผมเล่าให้คุณฟังแล้วว่ามีการต่อสู้อย่างต่อเนื่องระหว่างผมกับผู้ใช้คอมพิวเตอร์ ผมพยายามปรับประสิทธิภาพให้เหมาะสมสำหรับระบบ โดยรวม ส่วนพวกเขาพยายามปรับให้เหมาะสมสำหรับ การใช้งานของตัวเอง การเปลี่ยนแปลงใดๆ ในระบบการให้คะแนนที่คุณคิดว่าจะปรับปรุงประสิทธิภาพโดยรวมของระบบ มักจะไม่เวิร์ค นอกจากคุณจะคิดถึงการตอบสนองของแต่ละคนต่อการเปลี่ยนแปลงนั้นอย่างละเอียด—พวกเขาจะเปลี่ยนพฤติกรรมอย่างแน่นอน ลองคิดถึงการปรับเส้นทางอาชีพของคุณเองสิ ว่าระบบการให้คะแนนที่เปลี่ยนไปในอดีตได้เปลี่ยนแปลงแผนและกลยุทธ์ของคุณบ้าง
ระบบการวัดบางอย่างมีข้อเสียชัดเจน แต่ประเพณีและความสะดวกอื่นๆ ก็ยังคงทำให้มันดำเนินต่อไป ตัวอย่างคือสถานะความพร้อมรบของเหล่าทหาร ในกองทัพเรือ เรือจะถูกตรวจสอบเป็นประจำตามตาราง ทีละเรื่อง และกัปตันเรือก็จะเตรียมเรือและลูกเรือให้พร้อมสำหรับการตรวจแต่ละครั้ง โดยละเลยเรื่องอื่นๆ ไปจนกว่าจะถึงคิว กัปตันก็ได้คะแนนสูงแน่นอน แต่เมื่อเราต้องจำลองการฝึกจำลองศึก สถานะความพร้อมรบที่แท้จริงของกองเรือคืออะไร? แน่นอนว่าไม่ใช่สิ่งที่รายงานบอก—อย่างที่คุณพอจะนึกออก แล้วเราจะใช้อะไรล่ะ? แน่นอนว่าเราต้องใช้ตัวเลขที่รายงานมา—เราจะไม่ได้รับความเชื่อถือถ้าเราใช้ข้อมูลอื่น! ดังนั้นเราจึงฝึกคนในการจำลองศึกให้ใช้กองเรือในอุดมคติ ไม่ใช่กองเรือจริง! มันเหมือนกันในเกมธุรกิจ เราฝึกผู้บริหารให้ชนะในเกมจำลอง ไม่ใช่ในโลกจริง ผมให้คุณคิดเองว่าคุณจะทำอย่างไรเมื่อคุณเป็นผู้บริหารระดับสูงและต้องการรู้สถานะความพร้อมที่แท้จริงขององค์กร การตรวจสอบแบบไม่แจ้งล่วงหน้าจะแก้ปัญหาทุกอย่างได้ไหม? ไม่! แต่มันก็จะทำให้ดีขึ้นหน่อย
ทุกองค์กรมีปัญหานี้ ตอนนี้คุณอยู่ในระดับล่างขององค์กร และคุณสามารถเห็นได้ด้วยตัวเองว่ารายงานสิ่งต่างๆ อย่างไร และรายงานแตกต่างจากความเป็นจริงอย่างไร—มันก็จะยังเหมือนเดิมจนกว่าคุณ เมื่อคุณขึ้นเป็นผู้บริหารระดับสูง จะเปลี่ยนแปลงมันอย่างรุนแรง กองทัพอากาศสหรัฐฯ ใช้สิ่งที่ควรจะเป็นการตรวจสอบแบบสุ่ม แต่เพื่อนของผมที่เป็นอดีตกัปตันเรือเกษียณของกองทัพเรือเคยสังเกตกับผมว่า ผู้บัญชาการฐานทุกคนมีเรดาร์และรู้ว่ามีอะไรอยู่ในอากาศ และถ้าเขาถูกทีมตรวจสอบเซอร์ไพรส์ได้ เขาก็คงเป็นคนโง่ แต่เขาก็มีเวลาเตรียมตัวน้อยกว่าการตรวจสอบตามตาราง ดังนั้นจึงสันนิษฐานว่ารายงานการตรวจสอบน่าจะใกล้เคียงความจริงมากกว่าการตรวจสอบที่รู้ล่วงหน้านานๆ ใช่แล้ว การตรวจสอบคือการวัด และคุณได้สิ่งที่คุณวัด ในองค์กรอื่นๆ ก็มักจะไม่ต่างกันมาก—ข่าวเกี่ยวกับการวัด (การตรวจสอบ) ที่กำลังจะมาถึง ก็รั่วไหลออกไปตามสายข่าวลับ และผู้รับ ขณะที่แสร้งทำเป็นประหลาดใจ ก็มักจะเตรียมตัวมาตั้งแต่เช้าของวันนั้นแล้ว
อีกเรื่องที่เห็นได้ชัดแต่ดูเหมือนจำเป็นต้องพูดถึง: ความนิยมของรูปแบบการวัดแทบไม่มีความสัมพันธ์กับความแม่นยำหรือความเกี่ยวข้องกับองค์กรเลย
อีกเรื่องที่ควรพูดถึงคือ ทุกระดับขององค์กร แต่ละคนจะบิดเบือนสิ่งต่างๆ เพื่อให้ตัวเองดูดี—อย่างที่พวกเขาคิด! สิ่งเดียวที่ช่วยผู้บริหารระดับสูงได้คือ แต่ละระดับล่างสามารถบิดเบือนได้เพียงเล็กน้อย และบ่อยครั้งที่ระดับต่างๆ มีเป้าหมายที่แตกต่างกัน ดังนั้นการบิดเบือนความจริงหลายๆ ครั้งจึงมักจะหักล้างกันบางส่วน เนื่องจากกฎอ่อนของจำนวนมาก (weak law of large numbers) ถ้าทั้งองค์กรทำงานร่วมกันเพื่อหลอกผู้บริหารระดับสูง ผู้บริหารระดับสูงก็แทบจะทำอะไรไม่ได้ ตอนที่ผมอยู่ในคณะกรรมการบริหาร ผมตระหนักถึงเรื่องนี้มาก ผมจึงมักจะมาถึงก่อนเวลาหนึ่งวันหรืออยู่ต่ออีกหนึ่งวัน และแค่เดินไปเรื่อยๆ ถามคำถาม มองดู และถามตัวเองว่าสิ่งต่างๆ เป็นอย่างที่รายงานหรือไม่ ตัวอย่างเช่น ครั้งหนึ่งเมื่อสินค้าคงคลังสูงมากเนื่องจากการเปลี่ยนสายผลิตภัณฑ์คอมพิวเตอร์ที่เราผลิต ซึ่งบังคับให้เราต้องมีชิ้นส่วนของทั้งสองสายในมือพร้อมกัน ผมเดินไปมา ทันใดนั้นก็หันไปทางห้องเก็บของ และเดินเข้าไปเลย จากนั้นผมก็สังเกตสิ่งต่างๆ เพื่อตัดสินในใจของผมเองว่ามีความแตกต่างอย่างมากหรือไม่ หรือจำนวนที่รายงานนั้นมีความถูกต้องสมเหตุสมผล
อีกครั้งหนึ่ง เครื่องคอมพิวเตอร์ที่เราควรจะจัดส่งนั้นอยู่บนท่าเรือขนส่งจริงๆ หรือมันเป็นเพียงเครื่องในตำนาน—อย่างที่เกิดขึ้นในหลายบริษัท? การสืบเสาะทำให้ผมพบว่าในตอนสิ้นสุดแต่ละไตรมาส เครื่องจักรที่ต้องจัดส่งถูกจัดส่งจริง แต่มักจะผ่านกระบวนการดึงเครื่องจักรที่อยู่ถัดไปในสายการผลิตมาใช้แทน และในอีกสองสามสัปดาห์ต่อมาจึงต้องใช้เวลาในการนำเครื่องที่ถูกดึงมาใช้กลับไปสู่สถานะที่เหมาะสม ผมไม่เคยหยุดนิสัยแย่ๆ ของพนักงานนั้นได้เลย ถึงแม้ผมจะอยู่ในคณะกรรมการบริหาร! ถ้าคุณลองมองไปรอบๆ ในองค์กรของคุณ คุณจะพบสิ่งแปลกๆ มากมายที่ไม่ควรเกิดขึ้น แต่กลับถูกมองว่าเป็นแนวปฏิบัติปกติโดยพนักงาน
อีกเรื่องแปลกที่เกิดขึ้นคือ สิ่งที่ถูกมองอย่างหนึ่งในระดับหนึ่ง กลับถูกมองต่างออกไปในระดับที่สูงกว่า ตัวอย่างเช่น มันเกิดขึ้นบ่อยครั้งที่ การประเมินความสามารถ ขององค์กรในระดับหนึ่ง ถูกตีความเป็นความน่าจะเป็นในระดับที่สูงกว่า! ทำไมถึงเกิดเรื่องนี้ขึ้น? ก็เพียงเพราะว่าระดับล่างไม่สามารถส่งมอบสิ่งที่ระดับสูงต้องการได้ และจึงส่งมอบสิ่งที่ตนเองทำได้ และระดับสูงก็จงใจ เพราะต้องการตัวเลขของตัวเอง เลือกที่จะเปลี่ยนความหมายของรายงาน
ผมได้พูดถึงเรื่องการทดสอบอายุการใช้งาน (life tests) ไปแล้ว—สิ่งที่ทำได้กับสิ่งที่ต้องการไม่เหมือนกันเลย! ในตอนนี้เราไม่รู้วิธีที่จะส่งมอบสิ่งที่ต้องการ นั่นคือความน่าเชื่อถือสำหรับการทำงานหลายปีในระดับความเชื่อมั่นสูง สำหรับชิ้นส่วนที่เพิ่งส่งถึงมือเราเมื่อวานนี้ ปัญหานั้นจะไม่หายไป แต่เราสามารถทำอะไรได้มากมายในการออกแบบความน่าเชื่อถือที่ต้องการเข้าไปในสิ่งต่างๆ หนึ่งในปัญหาแรกๆ ของผมที่ Bell Telephone Laboratories คือการออกแบบชุดวงแหวนทองแดงและเซรามิกที่มีศูนย์กลางร่วมกัน เพื่อให้เมื่อเลือกขนาดรัศมี เมื่ออุณหภูมิเปลี่ยนแปลง เซรามิกจะถูกบีบอัดเสมอและไม่ถูกดึง ซึ่งเซรามิกจะมีความแข็งแรงน้อยในสภาวะนั้น การออกแบบนี้มีความน่าเชื่อถือในระดับหนึ่งที่ถูกสร้างขึ้นมาในตัว! ในความคิดของผม มีการทำในทิศทางนี้น้อยเกินไป แต่อย่างที่ผมเคยพูดไว้ก่อนหน้านี้ ตอนที่พวกเขาบอกว่าไม่มีเวลาจะทำ "ไม่มีเวลาให้ทำงานให้ถูกต้องตั้งแต่แรก แต่ก็มีเวลาให้แก้ไขทีหลังเสมอ"
มีระบบการให้คะแนนที่มีการตัดสินใจของมนุษย์ (human judgment) ถูกสร้างไว้ในระดับหนึ่ง—และนั่นฟังดูดี แต่ขอผมเล่าเรื่องหนึ่งที่สร้างความประทับใจให้ผมอย่างมาก ผมได้สร้างวิธีการใช้คอมพิวเตอร์ในการประเมิน การเลื่อนเฟส (phase shift) จากค่าเกน (gain) ที่วัดได้ที่ความถี่ต่างๆ ในสัญญาณ ซึ่งแทนที่วิธีการทำด้วยมือของมนุษย์ ผมไม่ได้อ้างว่ามันดีกว่า เพียงแต่ว่าวิธีการทำด้วยมือไม่สามารถทำงานใหม่นี้ได้เมื่อเราเปลี่ยนจากย่านความถี่เสียงพูดไปเป็นย่านความถี่ tv มีคนฉลาดคนหนึ่งพูดกับผมวันหนึ่งว่า "ก่อนหน้านี้ ตอนที่มนุษย์ทำสิ่งต่างๆ เราไม่สามารถปรับปรุงเพิ่มเติมได้ เพราะความแปรปรวนแบบสุ่มของมนุษย์ ตอนนี้คุณกำจัดองค์ประกอบสุ่มออกไปแล้ว เราจึงหวังว่าจะเรียนรู้สิ่งต่างๆ ที่ไม่ชัดเจนมาก่อนได้" วิธีการให้คะแนนที่ไม่มีการตัดสินใจของมนุษย์ก็มีข้อดีบางอย่าง—แต่อย่าคิดว่าผมต่อต้านการเพิ่มองค์ประกอบของการตัดสินใจของมนุษย์ วิธีการที่เป็นทางการส่วนใหญ่มีขอบเขตจำกัดโดยธรรมชาติ ในขณะที่ความซับซ้อนของความเป็นจริงนั้นไร้ขอบเขต ดังนั้นการตัดสินใจของมนุษย์ เมื่อใช้อย่างชาญฉลาด จึงมักเป็นสิ่งที่ดี—แม้ว่า ดังที่เพิ่งกล่าวไป มันก็เป็นอุปสรรคต่อความก้าวหน้าในทางหนึ่งด้วยแง่มุมที่เป็นอัตวิสัย (subjective)
จากทั้งหมดนี้ อย่าเพิ่งสรุปว่าการวัดไม่สามารถทำได้—มันสามารถทำได้แน่นอน—แต่คำถามเกี่ยวกับ ความเกี่ยวข้องและผลกระทบของรูปแบบการวัด ควรได้รับการคิดอย่างถี่ถ้วนเท่าที่คุณจะทำได้ ก่อน ที่คุณจะเริ่มใช้การวัดใหม่ในองค์กรของคุณ การเปลี่ยนแปลงที่หลีกเลี่ยงไม่ได้ที่จะเกิดขึ้นในอนาคต และพลังที่เพิ่มขึ้นของคอมพิวเตอร์ในการตรวจสอบสิ่งต่างๆ โดยอัตโนมัติ จะทำให้ระบบการวัดใหม่ๆ มากมายถูกนำมาใช้— ซึ่งคุณเองอาจต้องออกแบบ จัดระเบียบ และติดตั้งมัน ดังนั้นขอผมเล่าเรื่องอีกเรื่องเกี่ยวกับผลกระทบของการวัด
ในวงการคอมพิวเตอร์ ความพยายามในการเขียนโปรแกรมมักถูกวัดด้วยจำนวนบรรทัดของโค้ด (lines of code)—จะมีการวัดอะไรที่ง่ายกว่านี้อีกไหม? จากมุมมองของคนเขียนโค้ด ไม่มีเหตุผลใดเลยที่จะพยายามทำความสะอาดโค้ด ในทางตรงกันข้าม เพื่อให้ได้คะแนนสูงขึ้นในสเกลวัดผลผลิต มีเหตุผลทุกประการที่จะปล่อยให้คำสั่งส่วนเกินอยู่ตรงนั้น—จริงๆ แล้ว เพิ่ม "ลูกเล่นพิเศษ" เข้าไปอีกนิดถ้าเป็นไปได้ การวัดผลผลิตซอฟต์แวร์แบบนี้ ซึ่งถูกใช้อย่างแพร่หลาย เป็นหนึ่งในสาเหตุที่เรามีระบบซอฟต์แวร์ที่บวมโต (bloated) อย่างทุกวันนี้ มันเป็นแรงจูงใจที่ตรงกันข้าม กับการสร้างโค้ดที่สะอาด กระทัดรัด และเชื่อถือได้ที่เราทุกคนต้องการ ย้ำอีกครั้ง การวัดที่ใช้ส่งผลต่อผลลัพธ์ ในทางที่เป็นอันตรายต่อทั้งระบบ! มันยังสร้างนิสัยที่ยากจะกำจัดในภายหลังอีกด้วย
เมื่อถึงตาคุณที่จะติดตั้งระบบการวัด หรือแม้แต่จะวิจารณ์ระบบที่คนอื่นใช้อยู่ พยายามคิดให้รอบคอบ ถึงผลกระทบที่ซ่อนอยู่ทั้งหมดที่จะเกิดขึ้นกับองค์กร แน่นอนว่าในหลักการแล้ว การวัดเป็นสิ่งที่ดี แต่มันก็สามารถก่อให้เกิดโทษมากกว่าประโยชน์ได้บ่อยครั้ง ผมหวังว่าสารจะมาถึงคุณอย่างชัดเจน:
คุณได้สิ่งที่คุณวัด