หลังจากที่เราได้ศึกษาเกี่ยวกับคอมพิวเตอร์และวิธีการที่พวกมันใช้แทนข้อมูลแล้ว คราวนี้เรามาดูกันว่าคอมพิวเตอร์ประมวลผลข้อมูลอย่างไร แน่นอนว่าเราสามารถศึกษาได้เพียงส่วนเล็กๆ ของสิ่งที่พวกมันทำ และเราจะเน้นไปที่พื้นฐานตามปกติ
สิ่งที่คอมพิวเตอร์ประมวลผลส่วนใหญ่เป็นสัญญาณจากแหล่งต่างๆ และเราได้พูดคุยไปแล้วว่าทำไมพวกมันจึงมักอยู่ในรูปของกระแสตัวเลขจากระบบการสุ่มตัวอย่าง (sampling) ที่มีระยะห่างเท่ากัน การประมวลผลเชิงเส้น (linear processing) ซึ่งเป็นสิ่งเดียวที่ผมมีเวลาจะพูดถึงในหนังสือเล่มนี้ ก็คือ digital filters นั่นเอง เพื่อแสดงให้เห็น "สไตล์" และวิธีการที่สิ่งต่างๆ เกิดขึ้นจริงในชีวิต ผมจะเล่าให้คุณฟังก่อนว่าผมเริ่มเกี่ยวข้องกับมันได้อย่างไร จากนั้นจึงค่อยบอกว่าผมดำเนินการต่อไปอย่างไร
อย่างแรกเลยคือ ผมไม่เคยไปที่ออฟฟิศของรองประธานบริษัท W.O. Baker เลย เราพบกันแค่ตอนเดินผ่านไปมาในโถงทางเดิน และเรามักจะหยุดคุยกันสักสองสามนาที ครั้งหนึ่งประมาณปี ค.ศ. 1973–1974 ตอนที่ผมเจอเขาในโถงทางเดิน ผมบอกเขาว่าตอนที่ผมมาที่ Bell Telephone Laboratories ในปี 1946 ผมสังเกตว่า Labs ค่อยๆ เปลี่ยนจากระบบ relay ไปเป็น electronic central offices แต่คนจำนวนมากไม่ยอมเปลี่ยนไปใช้ oscilloscopes และเทคโนโลยีอิเล็กทรอนิกส์ที่ใหม่กว่า และพวกเขาก็ถูกย้ายไปที่อื่นเพื่อไม่ให้ขวางทาง สำหรับเขาแล้วพวกเขาคือความสูญเสียทางเศรษฐกิจครั้งใหญ่ แต่สำหรับผมพวกเขาคือความสูญเสียทางสังคม เพราะพวกเขาไม่พอใจอย่างที่สุดที่ถูกทิ้งไว้ข้างหลัง (ถึงแม้ว่ามันจะเป็นความผิดของพวกเขาเอง) ผมพูดต่อไปว่าผมเห็นสิ่งเดียวกันเกิดขึ้นตอนที่เราเปลี่ยนจาก analog computers รุ่นเก่า (ซึ่ง Bell Telephone Laboratories มีผู้เชี่ยวชาญมากมายเพราะพวกเขาได้พัฒนาเทคโนโลยีนี้เป็นส่วนใหญ่ในช่วง สงครามโลกครั้งที่สอง ) ไปเป็น digital computers ที่ทันสมัยกว่า—เราทิ้งวิศวกรจำนวนมากไว้ข้างหลังอีกครั้ง และพวกเขาก็กลายเป็นทั้งความสูญเสียทางเศรษฐกิจและสังคมเช่นกัน จากนั้นผมสังเกตว่าพวกเราทั้งคู่รู้ดีว่าบริษัทโทรศัพท์กำลังจะเปลี่ยนไปใช้ระบบดิจิทัลเต็มรูปแบบเร็วที่สุดเท่าที่จะทำได้ และคราวนี้เราจะทิ้งวิศวกรที่ไม่พอใจไว้ข้างหลังเป็นจำนวนมากกว่านั้นมาก ดังนั้นผมจึงสรุปว่าเราควรทำอะไรสักอย่าง ตอนนี้ เกี่ยวกับสถานการณ์นี้ เช่น หาหนังสือเบื้องต้นที่เหมาะสมและอุปกรณ์ฝึกอบรมอื่นๆ เพื่อช่วยให้พวกเขาก้าวไปสู่อนาคตได้ง่ายขึ้น และทิ้งคนไว้ข้างหลังให้น้อยลง เขามองตาผมแล้วพูดว่า "ใช่ Hamming คุณ ควรทำสิ" แล้วก็เดินจากไป! ยิ่งไปกว่านั้น เขายังคอยให้กำลังใจผมผ่านทาง John Tukey ซึ่งเขาคุยด้วยบ่อยๆ ดังนั้นผมจึงรู้ว่าเขากำลังจับตาดูความพยายามของผมอยู่
แล้วจะทำยังไงดี? อย่างแรกเลยคือผมคิดว่าผมรู้เรื่อง digital filters น้อยมาก และยิ่งไปกว่านั้นผมก็ไม่ได้สนใจมันจริงๆ ด้วย แต่คนเราจะเมินเฉยต่อ vp ของตัวเอง รวมถึงความมีน้ำหนักของสิ่งที่ตัวเองสังเกตเห็นได้อย่างชาญฉลาดหรือ? ไม่! ความสูญเสียทางสังคมที่แฝงอยู่นั้นมากเกินกว่าที่ผมจะนั่งมองเฉยๆ ได้อย่างสบายใจ
ผมจึงหันไปหาเพื่อนคนหนึ่งชื่อ Jim Kaiser (J.F. Kaiser) ซึ่งเป็นหนึ่งในผู้เชี่ยวชาญด้าน digital filters ระดับโลกในขณะนั้น และแนะนำว่าเขาควรหยุดงานวิจัยปัจจุบันของเขาและเขียนหนังสือเกี่ยวกับ digital filters—การเขียนหนังสือเพื่อสรุปผลงานของตัวเองนั้นเป็นขั้นตอนธรรมชาติในการพัฒนาของนักวิทยาศาสตร์ หลังจากกดดันอยู่พักหนึ่งเขาก็ตกลงจะเขียนหนังสือ ดังนั้นผมจึงรอดตัวไป—อย่างน้อยผมก็คิดแบบนั้น แต่เมื่อผมติดตามดูว่าเขาทำอะไรอยู่ก็พบว่าเขาไม่ได้เขียนอะไรเลย เพื่อช่วยแผนของผมไว้ ผมเสนอว่าถ้าเขาจะสอนผมในช่วงมื้อเที่ยงที่ร้านอาหาร (คุณมีเวลาคิดมากกว่าในโรงอาหาร) ผมจะช่วยเขียนหนังสือร่วมกัน (ส่วนใหญ่เป็นส่วนแรก) และเราจะเรียกมันว่า Kaiser และ Hamming เขาก็ตกลง!
เมื่อเวลาผ่านไป ผมได้รับความรู้ที่ดีจากเขา และผมก็เริ่มเขียนหนังสือส่วนแรกได้ แต่เขาก็ยังไม่เขียนอะไรเลย วันหนึ่งผมจึงพูดว่า "ถ้าคุณไม่เขียนเพิ่ม เราจะต้องเรียกมันว่า Hamming และ Kaiser แทน"—และเขาก็เห็นด้วย ต่อมาเมื่อผมเขียนเกือบหมดแล้วและเขาก็ยังไม่เขียนอะไรเลย ผมบอกว่าผมสามารถขอบคุณเขาในคำนำได้ แต่หนังสือควรเรียกว่า Hamming และเขาก็เห็นด้วย—และเราก็ยังเป็นเพื่อนที่ดีต่อกัน! นั่นคือที่มาของหนังสือเรื่อง digital filters ที่ผมเขียนขึ้น และท้ายที่สุดผมก็ดูแลมันถึงสามฉบับ โดยได้รับคำแนะนำที่ดีจาก Kaiser ตลอดมา
หนังสือเล่มนี้ยังพาผมไปยังสถานที่ที่น่าสนใจมากมาย เพราะผมได้สอนคอร์สระยะสั้นหนึ่งสัปดาห์เกี่ยวกับมันเป็นเวลาหลายปี คอร์สระยะสั้นเริ่มขึ้นตอนที่ผมยังเขียนหนังสืออยู่เพราะผมต้องการฟีดแบ็ก และได้แนะนำให้ UCLA Extension Division ว่าผมจะสอนเป็นคอร์สระยะสั้น ซึ่งพวกเขาก็ตกลง นั่นนำไปสู่การเป็นวิทยากรที่ UCLA หลายปี รวมถึงครั้งละครั้งในปารีส ลอนดอน และเคมบริดจ์ ประเทศอังกฤษ รวมถึงที่อื่นๆ อีกมากมายในสหรัฐฯ และอย่างน้อยสองครั้งในแคนาดา การทำในสิ่งที่จำเป็นต้องทำ ถึงแม้จะไม่อยากทำ แต่สุดท้ายก็ให้ผลตอบแทนที่คุ้มค่าในระยะยาว
ต่อไปเป็นส่วนที่สำคัญกว่า นั่นคือวิธีที่ผมเรียนรู้หัวข้อใหม่เกี่ยวกับ digital filters การเรียนรู้หัวข้อใหม่เป็นสิ่งที่คุณจะต้องทำหลายครั้งในอาชีพการงานของคุณ ถ้าคุณต้องการเป็นผู้นำและไม่ถูกทิ้งไว้ข้างหลังในฐานะผู้ตามเพราะความก้าวหน้าใหม่ๆ ในไม่ช้าผมก็เห็นชัดว่าทฤษฎี digital filter ถูกครอบงำโดย Fourier series ซึ่งในทางทฤษฎีผมได้เรียนรู้มาตั้งแต่สมัยเรียนมหาวิทยาลัย และจริงๆ แล้วผมก็ได้รับการศึกษาเพิ่มเติมอีกมากระหว่างการประมวลผลสัญญาณ (signal processing) ที่ผมทำเพื่อ John Tukey ซึ่งเป็นอาจารย์จาก Princeton อัจฉริยะ และเป็นพนักงานของ Bell Telephone Laboratories สัปดาห์ละหนึ่งหรือสองวัน เป็นเวลาประมาณสิบปีที่ผมทำหน้าที่เป็นแขนด้านการคำนวณให้เขาส่วนใหญ่
ในฐานะนักคณิตศาสตร์ ผมรู้เหมือนที่คุณทุกคนรู้ว่า เซตของฟังก์ชันที่สมบูรณ์ใดๆ สามารถใช้แทนฟังก์ชันต่างๆ ได้ดีพอๆ กัน แล้วทำไมถึงใช้แค่ Fourier series ล่ะ? ผมถามวิศวกรไฟฟ้าหลายคนแต่ไม่ได้คำตอบที่น่าพอใจ วิศวกรคนหนึ่งบอกว่ากระแสสลับเป็น sinusoidal ดังนั้นเราจึงใช้ sinusoids ซึ่งผมตอบว่ามันฟังดูไม่สมเหตุสมผลสำหรับผม นั่นแหละคือสิ่งที่เหลืออยู่ของการศึกษาของวิศวกรไฟฟ้าทั่วไปหลังจากที่พวกเขาจบการศึกษาไปแล้ว!
ดังนั้นผมจึงต้องคิดถึงพื้นฐาน เหมือนที่ผมบอกคุณว่าผมทำตอนใช้คอมพิวเตอร์ที่ตรวจจับข้อผิดพลาด อะไรกันแน่ที่เกิดขึ้น? ผมคิดว่าพวกคุณหลายคนรู้ว่าเราต้องการ การแทนสัญญาณที่ไม่ขึ้นกับเวลา (time-invariant) เพราะโดยทั่วไปแล้วไม่มีจุดกำเนิดของเวลาตามธรรมชาติ ดังนั้นเราจึงถูกนำไปสู่ฟังก์ชันตรีโกณมิติ (eigenfunctions ของการเลื่อนตำแหน่ง) ในรูปแบบของทั้ง Fourier series และ Fourier integrals ในฐานะเครื่องมือในการแทนสิ่งต่างๆ
ประการที่สอง ระบบเชิงเส้น (linear systems) ซึ่งเป็นสิ่งที่เราต้องการในขั้นตอนนี้ ก็มี eigenfunctions เดียวกันนั่นคือ complex exponentials ซึ่งเทียบเท่ากับฟังก์ชันตรีโกณมิติจริง ดังนั้นจึงมีกฎง่ายๆ คือ ถ้าคุณมีระบบที่ไม่ขึ้นกับเวลาหรือระบบเชิงเส้น คุณควรใช้ complex exponentials
เมื่อขุดลึกลงไปอีก ผมพบเหตุผลที่สามสำหรับการใช้它们在ในด้าน digital filters มีทฤษฎีบทที่มักเรียกว่า Nyquist's sampling theorem (ถึงแม้จะเป็นที่รู้จักมาก่อนหน้านั้นและตีพิมพ์โดย Whittaker ในรูปแบบที่คุณแทบจะไม่รู้ว่ามันกำลังพูดอะไร ถึงแม้คุณจะรู้จักทฤษฎีบทของ Nyquist ก็ตาม) ซึ่งกล่าวว่าถ้าคุณมีสัญญาณแบบ band-limited และสุ่มตัวอย่างที่ระยะห่างเท่ากันในอัตราอย่างน้อยสองเท่าของความถี่สูงสุด สัญญาณดั้งเดิมก็สามารถสร้างกลับคืนมาจากตัวอย่างได้ ดังนั้นกระบวนการสุ่มตัวอย่างจึงไม่สูญเสียข้อมูลเมื่อเราแทนที่สัญญาณต่อเนื่องด้วยตัวอย่างที่มีระยะห่างเท่ากัน โดยที่ตัวอย่างครอบคลุมเส้นจำนวนจริงทั้งหมด อัตราการสุ่มตัวอย่างนี้มักรู้จักกันในชื่อ Nyquist rate ตามชื่อของ Harry Nyquist ซึ่งมีชื่อเสียงด้านเสถียรภาพของ servo และเรื่องอื่นๆ เช่นกัน ถ้าคุณสุ่มตัวอย่างฟังก์ชันที่ไม่ใช่ band-limited ความถี่ที่สูงกว่าจะถูก "aliased" ไปเป็นความถี่ที่ต่ำกว่า ซึ่งเป็นคำที่ Tukey คิดขึ้นเพื่ออธิบายความจริงที่ว่า ความถี่สูงเดี่ยวๆ ความถี่หนึ่งจะปรากฏเป็น ความถี่ต่ำเดี่ยวๆ ใน Nyquist band ในภายหลัง สิ่งเดียวกันนี้ไม่เป็นจริงสำหรับเซตของฟังก์ชันอื่นๆ เช่น ยกกำลังของ t ภายใต้การสุ่มตัวอย่างและการสร้างกลับคืนที่ระยะห่างเท่ากัน ยกกำลังสูงเดี่ยวของ t จะกลายเป็นพหุนาม (หลายพจน์) ของยกกำลังต่ำของ t
ดังนั้นจึงมีเหตุผลที่ดีสามประการสำหรับฟังก์ชัน Fourier: (1) time invariance (ความเป็นอิสระจากเวลา) (2) linearity (ความเป็นเชิงเส้น) และ (3) การสร้างฟังก์ชันดั้งเดิมกลับคืนจากตัวอย่างที่มีระยะห่างเท่ากันนั้นง่ายและเข้าใจได้ไม่ยาก
ดังนั้นเราจะวิเคราะห์สัญญาณในรูปของฟังก์ชัน Fourier และผมไม่จำเป็นต้องถกเถียงกับวิศวกรไฟฟ้าว่าทำไมเราจึงมักใช้ complex exponents เป็นความถี่แทนฟังก์ชันตรีโกณมิติจริง เรามีการดำเนินการเชิงเส้น และเมื่อเราใส่สัญญาณ (กระแสของตัวเลข) เข้าไปใน filter แล้วมันก็จะส่งออกมากระแสของตัวเลขอีกชุดหนึ่ง เป็นเรื่องธรรมชาติ ถ้าไม่ใช่จากวิชา linear algebra ก็จากวิชาอื่นๆ เช่น differential equations ที่จะถามว่าฟังก์ชันอะไรที่เข้าไปและออกมาเหมือนเดิมทุกประการ ยกเว้น สเกลที่เปลี่ยนไป ดังที่ได้กล่าวไว้ข้างต้น พวกมันคือ complex exponentials พวกมันคือ eigenfunctions ของระบบเชิงเส้น ไม่ขึ้นกับเวลา และสุ่มตัวอย่างที่ระยะห่างเท่ากัน
แท้จริงแล้ว transfer function ที่มีชื่อเสียงนั้นก็คือ eigenvalues ของ eigenfunctions ที่สอดคล้องกันนั่นเอง! เมื่อถามวิศวกรไฟฟ้าหลายคนว่า transfer function คืออะไร ไม่มีใครเคยบอกผมแบบนั้นเลย! ใช่ เมื่อชี้ให้เห็นว่ามันเป็นแนวคิดเดียวกันพวกเขาก็ต้องยอมรับ แต่ความจริงที่ว่ามันเป็นแนวคิดเดียวกันนั้นดูเหมือนจะไม่เคยข้ามผ่านความคิดของพวกเขาเลย! แนวคิดเดียวกันง่ายๆ ในรูปแบบที่แตกต่างกันสองแบบหรือมากกว่าในความคิดของพวกเขา และพวกเขาไม่รู้ถึงความเชื่อมโยงระหว่างมันเลย! จงลงไปที่พื้นฐานทุกครั้ง!
เราจะเริ่มการสนทนาด้วย "สัญญาณคืออะไร?" ธรรมชาติส่งสัญญาณต่อเนื่องมากมาย ซึ่งเราจะสุ่มตัวอย่างที่ระยะห่างเท่ากันและแปลงเป็นดิจิทัล (quantize) ต่อไป โดยทั่วไปสัญญาณจะเป็นฟังก์ชันของเวลา แต่การทดลองใดๆ ในห้องปฏิบัติการที่ใช้แรงดันไฟฟ้าที่มีระยะห่างเท่ากัน และบันทึกการตอบสนองที่สอดคล้องกัน ก็ถือเป็นสัญญาณดิจิทัลเช่นกัน ดังนั้นสัญญาณดิจิทัลคือลำดับการวัดที่ระยะห่างเท่ากันในรูปของตัวเลข และเราจะได้ชุดตัวเลขที่มีระยะห่างเท่ากันอีกชุดหนึ่งออกมาจาก digital filter เราสามารถและบางครั้งก็จำเป็นต้องประมวลผลข้อมูลที่มีระยะห่างไม่เท่ากัน แต่ผมจะไม่พูดถึงมันที่นี่
การ quantization ของสัญญาณให้เป็นหนึ่งในหลายระดับของ output มักมีผลกระทบที่น้อยอย่างน่าประหลาดใจ คุณทุกคนเคยเห็นภาพที่ถูก quantize เป็น 2, 4, 8 และมากกว่าระดับ และแม้แต่ภาพสองระดับก็ยังคงจำได้ ผมจะไม่พูดถึง quantization ที่นี่เพราะโดยทั่วไปมันเป็นผลกระทบเล็กน้อย ถึงแม้บางครั้งมันจะสำคัญมากก็ตาม
ผลที่ตามมาของการสุ่มตัวอย่างที่ระยะห่างเท่ากันคือ aliasing ; ความถี่ที่สูงกว่า Nyquist frequency (ซึ่งมีสองตัวอย่างในหนึ่งรอบ) จะถูก aliased ไปเป็นความถี่ที่ต่ำกว่า นี่เป็นผลลัพธ์อย่างง่ายของเอกลักษณ์ตรีโกณมิติ
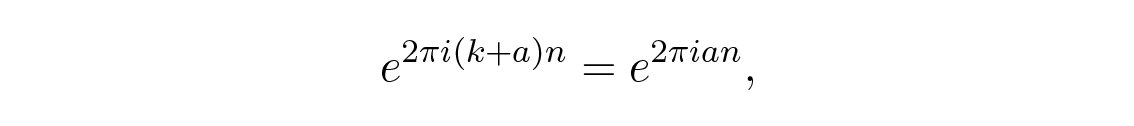
โดยที่ a คือเศษบวกหลังจากลบจำนวนรอบเต็ม k (เราใช้การหมุนรอบเมื่อพูดถึงผลลัพธ์ และใช้เรเดียนเมื่อใช้แคลคูลัส เหมือนกับที่เราใช้ log ฐาน-10 และ log ฐาน- e ) และ n คือหมายเลขขั้นตอน ถ้า a > 1/2 เราก็สามารถเขียนข้างต้นได้เป็น
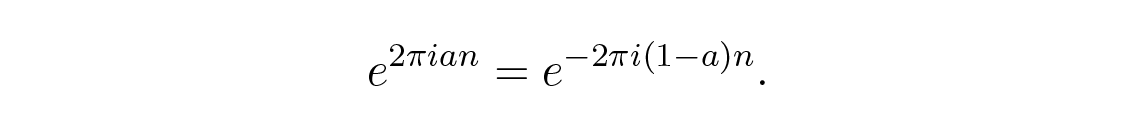
ดังนั้นแถบ aliased จึงมีความยาวน้อยกว่าครึ่งรอบ บวกหรือลบ ถ้าเราใช้ฟังก์ชันตรีโกณมิติจริงสองฟังก์ชันคือ sine และ cosine เราจะมี คู่ ของ eigenfunctions สำหรับแต่ละความถี่ และแถบจะอยู่ตั้งแต่ 0 ถึง 1/2 รอบ แต่เมื่อเราใช้สัญกรณ์ complex exponential เราจะมี หนึ่ง eigenfunction สำหรับแต่ละความถี่ แต่ตอนนี้แถบจะอยู่ตั้งแต่ –1/2 ถึง 1/2 รอบ การหลีกเลี่ยง eigenvalues ที่ซ้ำซ้อนนี้เป็นส่วนหนึ่งของเหตุผลที่ความถี่เชิงซ้อนนั้นจัดการได้ง่ายกว่าฟังก์ชัน sine และ cosine จริงมาก อัตราการสุ่มตัวอย่างสูงสุดที่ไม่มี aliasing เกิดขึ้นคือสองตัวอย่างต่อหนึ่งรอบ และเรียกว่า Nyquist rate จากตัวอย่างนั้น สัญญาณดั้งเดิมไม่สามารถระบุได้อย่างแม่นยำถึงความถี่ที่ถูก aliased มีเพียงความถี่พื้นฐานที่ตกอยู่ในช่วงพื้นฐานของความถี่ที่ไม่ถูก alias ( –1/2 ถึง 1/2 ) เท่านั้นที่สามารถระบุได้อย่างไม่ซ้ำกัน สัญญาณจากความถี่ aliased ต่างๆ จะไปรวมกันที่ความถี่เดียวในแถบและถูกบวกเข้าด้วยกันเชิงพีชคณิต นั่นคือสิ่งที่เราเห็นหลังจากทำการสุ่มตัวอย่างแล้ว ดังนั้นการบวกหรือการหักล้างอาจเกิดขึ้นระหว่างการ aliasing และเราไม่สามารถรู้จากสัญญาณที่ถูก alias แล้วว่าเรามีอะไรเดิมอยู่ ที่อัตราการสุ่มตัวอย่างสูงสุด เราไม่สามารถแยกผลลัพธ์จาก 1 ได้ ดังนั้นความถี่ที่ไม่ถูก alias จะต้องอยู่ ภายใน แถบเท่านั้น
เราจะยืด (บีบอัด) เวลาเพื่อให้อัตราการสุ่มตัวอย่างเป็นหนึ่งต่อหน่วยเวลา เพราะมันทำให้สิ่งต่างๆ ง่ายขึ้นมาก และนำประสบการณ์จากช่วงมิลลิวินาทีและไมโครวินาทีไปสู่สิ่งเหล่านั้นที่อาจใช้เวลาหลายวันหรือหลายปีระหว่างตัวอย่าง การใช้สัญกรณ์มาตรฐานและกรอบการคิดสำหรับสิ่งที่หลากหลายนั้นเป็นสิ่งที่ชาญฉลาดเสมอ—การประยุกต์ใช้ในสาขาหนึ่งอาจแนะนำสิ่งที่ควรทำในอีกสาขาหนึ่ง ผมพบว่ามันมีค่าอย่างมากที่จะทำเช่นนั้นเมื่อเป็นไปได้—กำจัด scale factors ที่ไม่เกี่ยวข้องออกไปและเข้าถึงนิพจน์พื้นฐาน (แต่ก็อย่างว่า ผมได้รับการฝึกฝนมาเป็นนักคณิตศาสตร์)
Aliasing เป็นผลกระทบพื้นฐานของการสุ่มตัวอย่าง และไม่เกี่ยวข้องกับวิธีการประมวลผลสัญญาณ ผมพบว่าสะดวกที่จะคิดว่าเมื่อสุ่มตัวอย่างแล้ว ความถี่ทั้งหมดจะอยู่ใน Nyquist band ดังนั้นเราไม่จำเป็นต้องวาด periodic extensions ของสิ่งใดๆ เพราะความถี่อื่นๆ ไม่มีอยู่ในสัญญาณอีกต่อไป—เมื่อสุ่มตัวอย่างแล้ว ความถี่ที่สูงกว่าจะถูก alias ลงไปในแถบที่ต่ำกว่า และไม่มีอยู่ในนั้นอีกต่อไป เป็นการประหยัดความคิดอย่างมาก! การสุ่มตัวอย่างสร้างสัญญาณที่ถูก alias ที่เราต้องใช้
ต่อไปผมจะเล่าเรื่องสามเรื่องที่ใช้เพียงแนวคิดของการสุ่มตัวอย่างและ aliasing เท่านั้น ในเรื่องแรก ผมกำลังพยายามคำนวณหาคำตอบเชิงตัวเลขของระบบสมการเชิงอนุพันธ์สามัญ 28 สมการ และผมต้องรู้อัตราการสุ่มตัวอย่างที่จะใช้ (ขนาดขั้นตอนของคำตอบคืออัตราการสุ่มตัวอย่างที่คุณใช้) เพราะถ้ามันเป็นครึ่งหนึ่งของที่คาดไว้ ค่าใช้จ่ายในการคำนวณก็จะประมาณสองเท่า สำหรับวิธีการแก้ปัญหาเชิงตัวเลขที่ได้รับความนิยมและใช้งานได้จริงส่วนใหญ่ ทฤษฎีทางคณิตศาสตร์จะกำหนดขนาดขั้นตอนตามอนุพันธ์อันดับที่ห้า ใครจะรู้ขอบเขตได้? ไม่มีใคร! แต่มองในมุมของการสุ่มตัวอย่าง การ aliasing จะเริ่มต้นที่สองตัวอย่างต่อความถี่สูงสุดที่มีอยู่ โดยมีเงื่อนไขว่า คุณมีข้อมูลจากลบอนันต์ถึงบวกอนันต์ แต่เมื่อมีข้อมูลเพียงช่วงสั้นๆ ไม่เกินห้าจุด ผม intuitively คิดว่าผมคงต้องใช้อัตราประมาณสองเท่า หรือสี่ตัวอย่างต่อหนึ่งรอบ และสุดท้าย เมื่อมีข้อมูลเพียงด้านเดียว ก็อาจต้องเพิ่มอีกสองเท่า รวมเป็นแปดตัวอย่างต่อหนึ่งรอบ
จากนั้นผมก็ทำสองสิ่ง: (1) พัฒนาทฤษฎี และ (2) ทดสอบเชิงตัวเลขกับสมการเชิงอนุพันธ์อย่างง่าย
ทั้งสองแสดงให้เห็นว่าที่ประมาณเจ็ดตัวอย่างต่อหนึ่งรอบ คุณอยู่ในขอบของความแม่นยำ (ต่อขั้นตอน) และที่สิบตัวอย่างคุณปลอดภัยมาก ดังนั้นผมจึงอธิบายสถานการณ์ให้พวกเขาฟัง และขอความถี่สูงสุดในคำตอบที่คาดหวัง พวกเขาเห็นถึงความถูกต้องของคำขอของผม และหลังจากนั้นไม่กี่วันพวกเขาก็บอกว่าผมต้องกังวลเกี่ยวกับความถี่สูงถึง 10 รอบต่อวินาที และพวกเขาจะจัดการกับความถี่ที่สูงกว่านั้น พวกเขาพูดถูก และคำตอบก็เป็นที่น่าพอใจ การใช้ sampling theorem ในทางปฏิบัติ!
เรื่องที่สองเกี่ยวข้องกับคำพูดที่พูดกับผมอย่างไม่เป็นทางการในโถงทางเดินของ Bell Telephone Laboratories ว่าผู้รับเหมาช่วงจากชายฝั่งตะวันตกรายหนึ่งกำลังประสบปัญหาในการจำลองการยิง ขีปนาวุธ Nike และกำลังใช้ระยะห่าง 1/1,000 ถึง 1/10,000 วินาที ผมหัวเราะทันทีและบอกว่าต้องมีความผิดพลาดแน่ๆ 70 ถึง 100 ตัวอย่างก็เพียงพอสำหรับโมเดลที่พวกเขาใช้ ปรากฏว่าพวกเขามีเลขฐานสองผิดไปเจ็ดตำแหน่งทางซ้าย ใหญ่เกินไป 128 เท่า! การดีบักโปรแกรมขนาดใหญ่ข้ามทวีปโดยใช้ sampling theorem!
เรื่องที่สามคือกลุ่มที่ Naval Postgraduate School กำลัง modulate สัญญาณความถี่สูงมากลงมายังจุดที่พวกเขาสามารถสุ่มตัวอย่างได้ ตาม sampling theorem ที่พวกเขาเข้าใจ แต่ผมตระหนักว่าถ้าพวกเขาสุ่มตัวอย่างที่ความถี่สูงอย่างชาญฉลาด การสุ่มตัวอย่างนั้นเองก็จะ modulate (alias) มันลงมา หลังจากโต้เถียงกันหลายวัน พวกเขาก็เอาชุดอุปกรณ์ลดความถี่ออก และอุปกรณ์ที่เหลือก็ทำงานได้ดีขึ้น! อีกครั้งหนึ่ง ผมต้องการเพียงความเข้าใจที่แน่นหนาเกี่ยวกับผลกระทบของ aliasing เนื่องจากการสุ่มตัวอย่าง มันเป็นอีกตัวอย่างหนึ่งว่าทำไมคุณต้องรู้ พื้นฐานให้ดีมากๆ แล้วส่วนที่หรูหราก็จะตามมาได้ง่าย และคุณสามารถทำสิ่งที่พวกเขาไม่เคยบอกคุณได้
การสุ่มตัวอย่างเป็นพื้นฐานของวิธีการที่เราใช้ประมวลผลข้อมูลในปัจจุบันเมื่อใช้คอมพิวเตอร์ดิจิทัล และตอนนี้เราเข้าใจแล้วว่าสัญญาณคืออะไร และการสุ่มตัวอย่างทำอะไรกับสัญญาณ เราก็สามารถหันไปหารายละเอียดเพิ่มเติมของการประมวลผลสัญญาณได้อย่างปลอดภัย
เราจะพูดถึง nonrecursive filters ก่อน ซึ่งมีจุดประสงค์เพื่อให้บางความถี่ผ่านและหยุดความถี่อื่น ปัญหานี้เกิดขึ้นครั้งแรกในบริษัทโทรศัพท์เมื่อพวกเขามีแนวคิดว่าถ้าข้อความเสียงหนึ่งถูกเลื่อนความถี่ทั้งหมดขึ้น (modulated) ให้เกินช่วงของอีกข้อความหนึ่ง สัญญาณทั้งสองก็จะถูกรวมและส่งผ่านสายเดียวกัน และที่ปลายทางก็จะถูกกรองแยกออกจากกัน และสัญญาณที่สูงกว่าก็จะถูกลด (demodulated) กลับไปยังความถี่ดั้งเดิม การเลื่อนนี้ทำได้ง่ายๆ โดยการคูณด้วยฟังก์ชัน sinusoidal และเลือกแถบความถี่หนึ่ง (single-sideband modulation) จากสองความถี่ที่เกิดขึ้นตามเอกลักษณ์ตรีโกณมิติต่อไปนี้ (คราวนี้เราใช้ฟังก์ชันจริง):
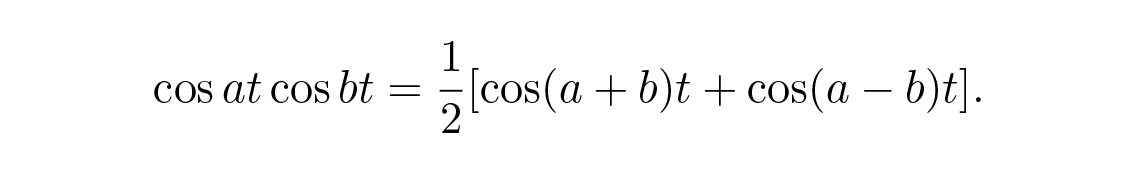
ไม่มีอะไรลึกลับเกี่ยวกับการเลื่อนความถี่ (modulation) ของสัญญาณ มันเป็นเพียงรูปแบบหนึ่งของเอกลักษณ์ตรีโกณมิติ
nonrecursive filters ที่เราจะพิจารณาก่อนเป็นหลักคือแบบ smoothing โดย input คือค่า u ( t ) = u ( n ) = u n และ output คือ
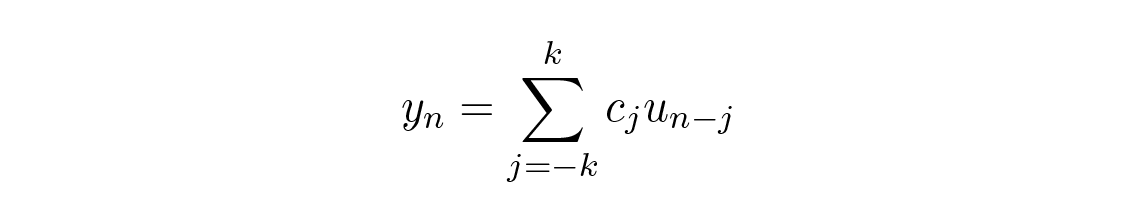
โดยที่ c j \= c –j (สัมประสิทธิ์มีความสมมาตรเกี่ยวกับค่ากลาง c 0 )
ผมต้องเตือนคุณเกี่ยวกับ least squares เพราะมันมีบทบาทพื้นฐานในสิ่งที่เรากำลังจะทำ ดังนั้นผมจะออกแบบ smoothing filter เพื่อแสดงให้คุณเห็นว่า filter เกิดขึ้นมาได้อย่างไร สมมติว่าเรามีสัญญาณที่มี "สัญญาณรบกวน" เพิ่มเข้ามาและต้องการทำให้เรียบ (smooth) หรือกำจัดสัญญาณรบกวนออกไป เราจะสมมติว่ามัน ดู สมเหตุสมผลที่จะ fitting เส้นตรงกับจุดข้อมูลห้าจุดที่ติดต่อกันในแบบ least squares จากนั้นนำค่ากลางบนเส้นนั้นมาเป็น "ค่าที่ปรับเรียบของฟังก์ชัน" ณ จุดนั้น
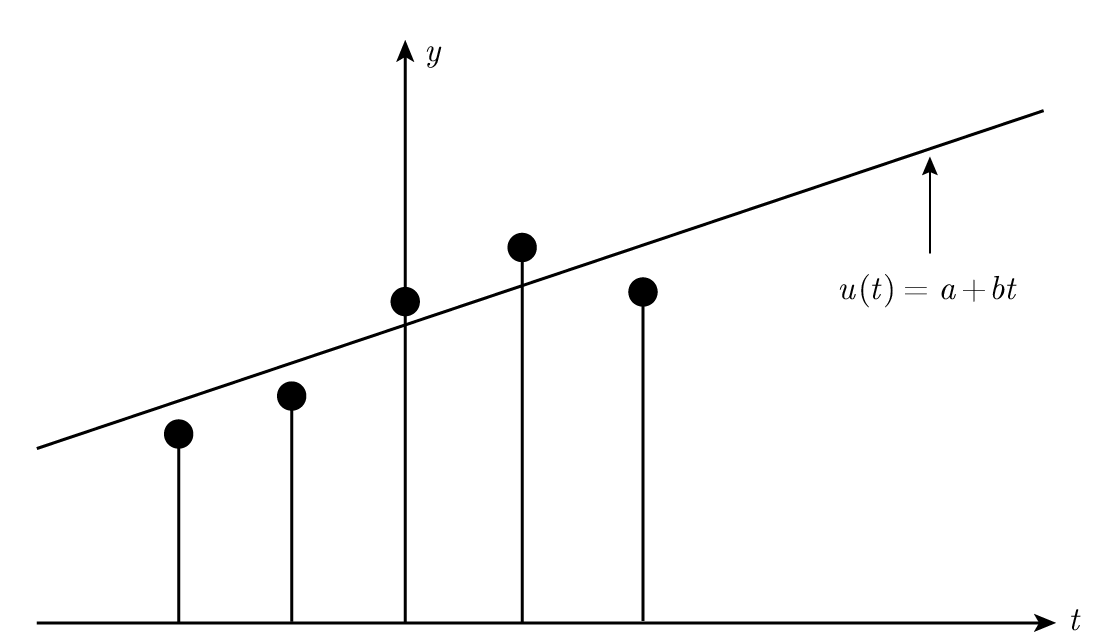
Figure 14.1—Fitting a straight line (การ fitting เส้นตรง)
เพื่อความสะดวกทางคณิตศาสตร์ เราเลือกห้าจุดที่ t \= –2 , –1 , 0 , 1 , 2 และ fitting เส้นตรง Figure 14.1 ,
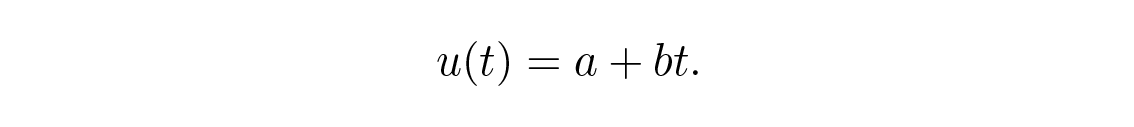
Least squares บอกว่าเราควรหาค่าต่ำสุดของผลรวมกำลังสองของความแตกต่างระหว่างข้อมูลกับจุดบนเส้น นั่นคือ หาค่าต่ำสุดของ
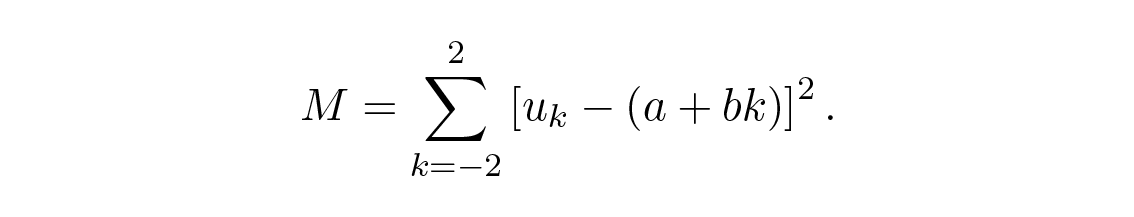
พารามิเตอร์อะไรที่ต้องใช้ในการหาอนุพันธ์เพื่อหาค่าต่ำสุด? พวกมันคือ a และ b ไม่ใช่ t (ซึ่งตอนนี้เป็นตัวแปรไม่ต่อเนื่อง k ) และ u เส้นตรงขึ้นอยู่กับพารามิเตอร์ a และ b และนี่มักเป็นอุปสรรคสำหรับนักศึกษา พารามิเตอร์ของสมการคือตัวแปรที่ใช้ในการ minimize! ดังนั้นเมื่อหาอนุพันธ์เทียบกับ a และ b และตั้งอนุพันธ์ให้เท่ากับศูนย์เพื่อหาค่าต่ำสุด เราจะได้:
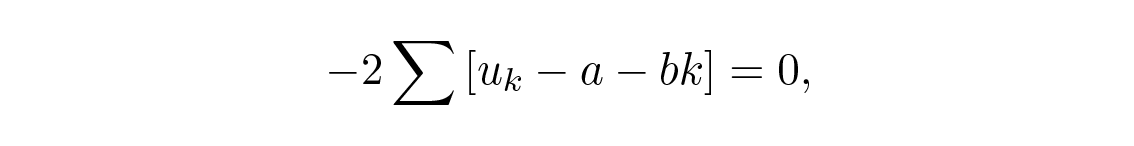
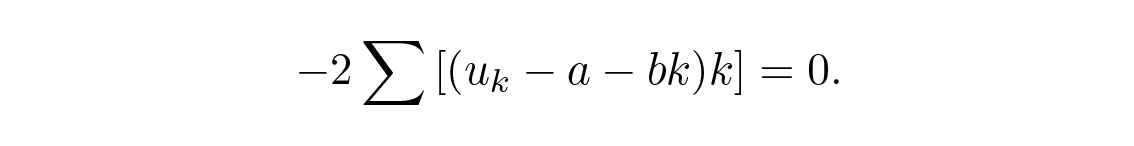
ในกรณีนี้เราต้องการแค่ a ซึ่งเป็นค่าของเส้นตรงที่จุดกึ่งกลาง ดังนั้นเมื่อใช้ (ผลรวมบางส่วนไว้ใช้ภายหลัง)
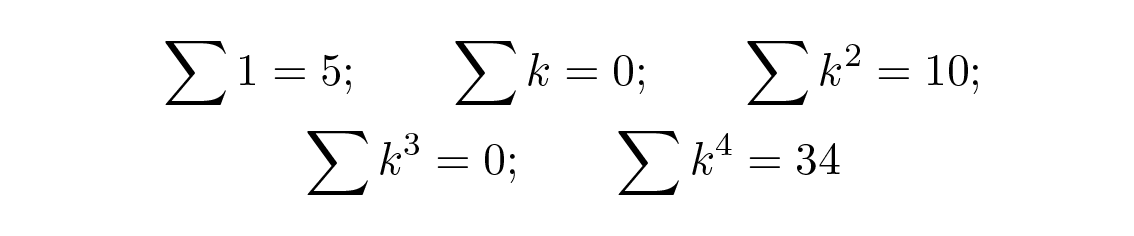
จากสมการบนสุดเราได้
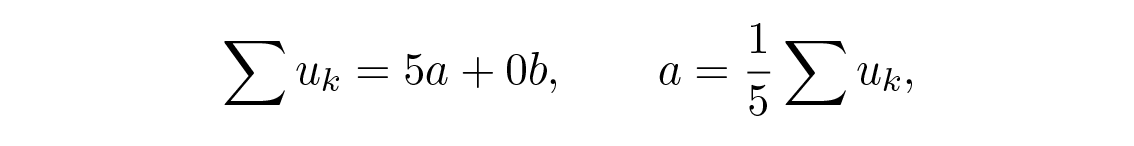
ซึ่งก็คือค่าเฉลี่ยของค่าที่อยู่ติดกันห้าค่านั่นเอง เมื่อคุณคิดถึงวิธีการคำนวณ a ซึ่งเป็นค่าที่ปรับเรียบแล้ว ให้คิดถึงข้อมูลในคอลัมน์แนวตั้ง Figure 14.2 โดยที่สัมประสิทธิ์แต่ละตัวคือ 1/5 เป็นการถ่วงน้ำหนักแบบเลื่อนของข้อมูล จากนั้นคุณสามารถคิดว่ามันเป็น หน้าต่าง (window) ที่คุณมองผ่านข้อมูล โดยที่ "รูปร่าง" ของหน้าต่างคือสัมประสิทธิ์ของ filter ในกรณีนี้การปรับเรียบจะมีขนาดเท่ากันหมด
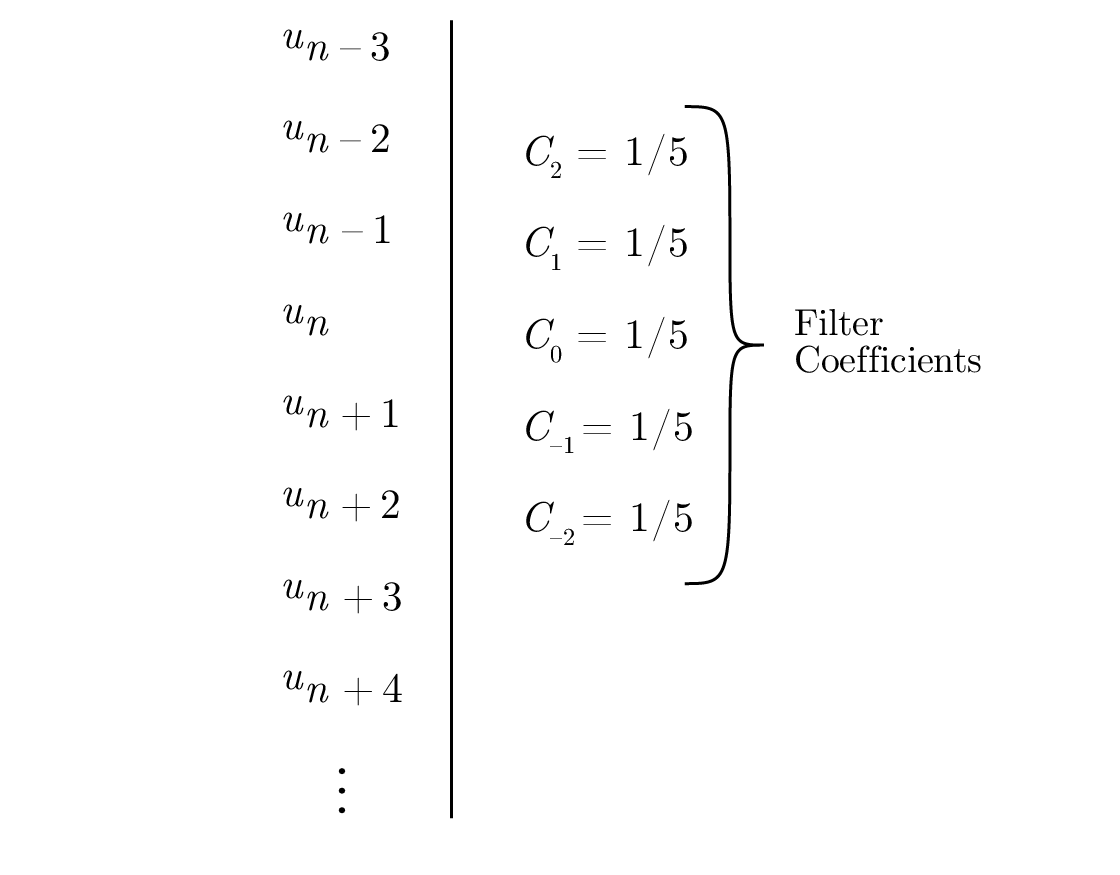
Figure 14.2—Data in a vertical column (ข้อมูลในคอลัมน์แนวตั้ง)
ถ้าเราใช้ 2 k + 1 จุดที่วางอย่างสมมาตร เราก็จะยังคงได้ค่าเฉลี่ยเลื่อนของจุดข้อมูลเป็นค่าที่ปรับเรียบ ซึ่งควรจะกำจัดสัญญาณรบกวนได้
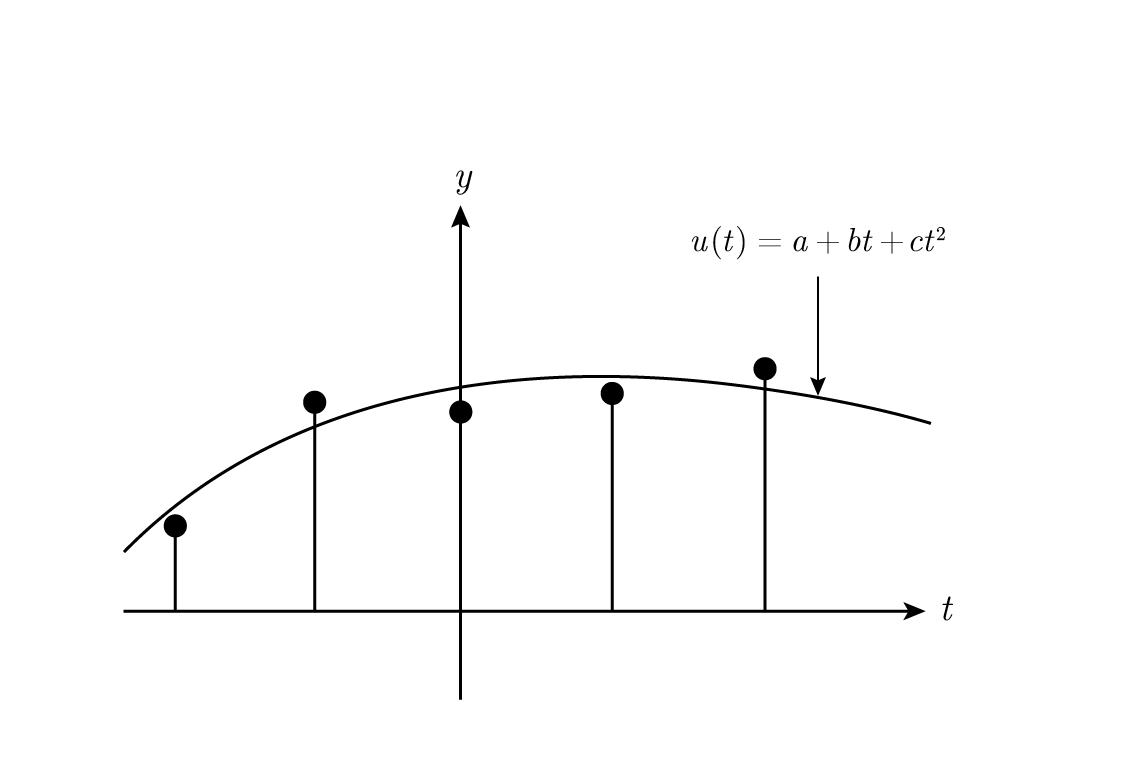
Figure 14.3—Fitting a quadratic (การ fitting สมการกำลังสอง)
สมมติว่าแทนที่จะใช้เส้นตรง เราได้ปรับเรียบโดยการ fitting สมการกำลังสอง Figure 14.3 :
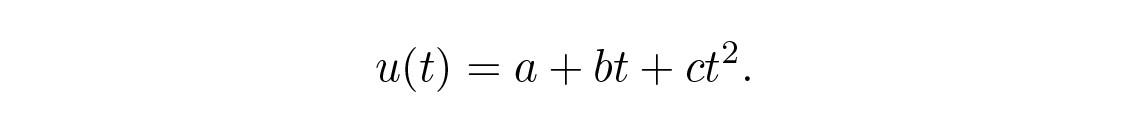
ตั้งค่าผลต่างของกำลังสองและหาอนุพันธ์คราวนี้เทียบกับ a , b , และ c เราจะได้
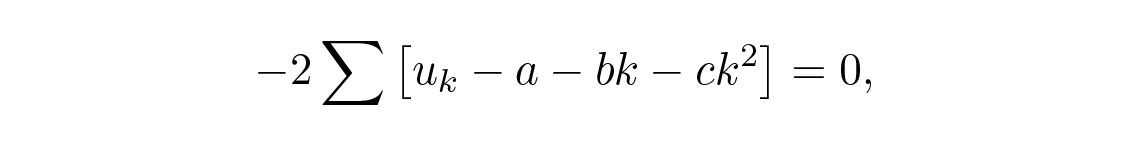
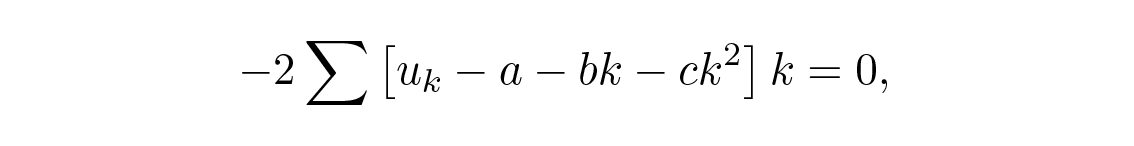
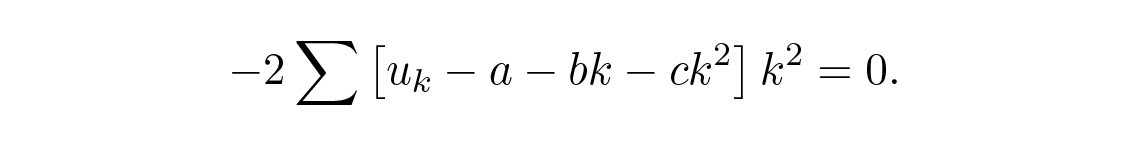
อีกครั้งเราแค่ต้องการ a เขียนสมการแรกและสมการที่สามใหม่ (สมการที่สองไม่เกี่ยวข้องกับ a ) และใส่ผลรวมที่รู้แล้วจากด้านบน เราจะได้
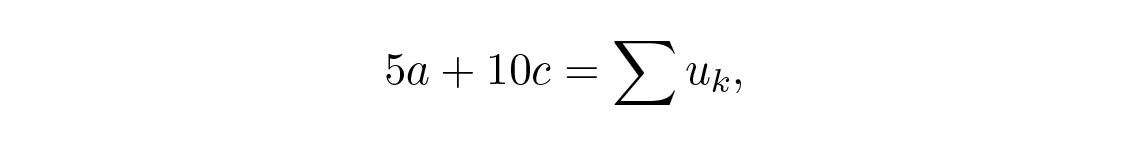
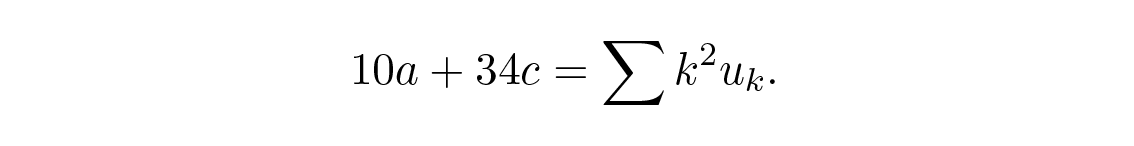
เพื่อกำจัด c ซึ่งเราไม่ต้องการ เราคูณสมการบนด้วย 17 และสมการล่างด้วย –5 แล้วบวกเข้าด้วยกันจะได้
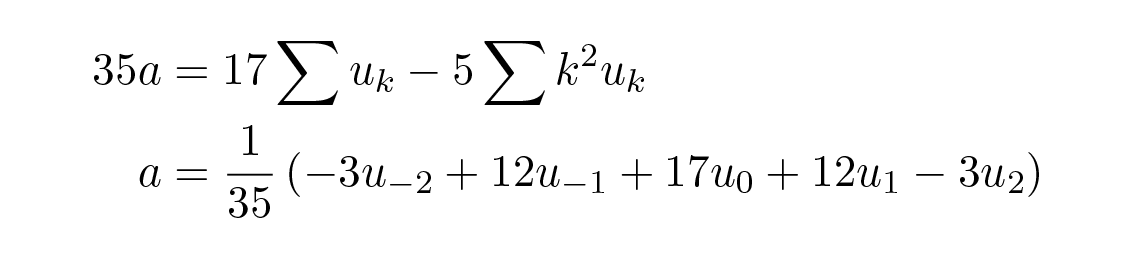
และครั้งนี้ "หน้าต่างปรับเรียบ" ของเราไม่ได้มีสัมประสิทธิ์ที่เท่ากัน แต่มีบางค่าที่เป็นลบ อย่าให้เรื่องนั้นทำให้คุณกังวล เพราะเรากำลังพูดถึงหน้าต่างในเชิงอุปมาอุปไมย การส่งผ่านค่าลบจึงเป็นไปได้
ถ้าเราเลื่อนสูตรการปรับเรียบที่ได้จาก least squares ทั้งสองนี้ไปยังตำแหน่งที่เหมาะสมรอบจุด n เราจะได้
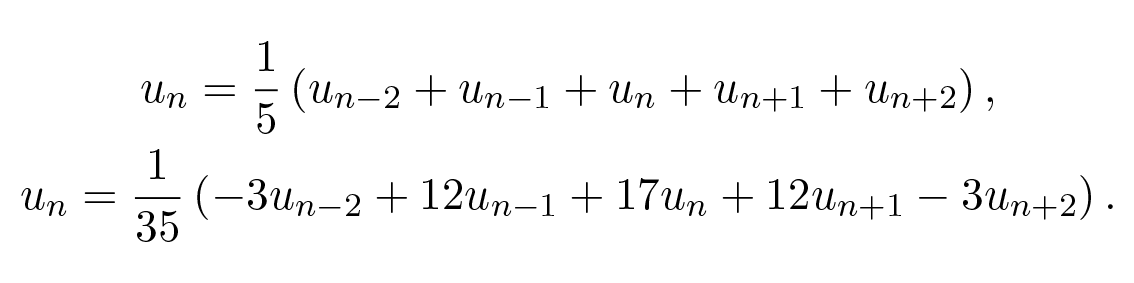
ตอนนี้เราถามว่าจะเกิดอะไรขึ้นถ้าเราใส่ eigenfunction บริสุทธิ์เข้าไป เรารู้ว่าเนื่องจากสมการเป็นแบบเชิงเส้น มันควรจะให้ eigenfunction กลับคืนมา แต่คูณด้วย eigenvalue ที่สอดคล้องกับความถี่ของ eigenfunction นั้น ซึ่งก็คือค่า transfer function ที่ความถี่นั้น นำสูตรการปรับเรียบอันแรกจากสองสูตรมาใช้เราจะได้
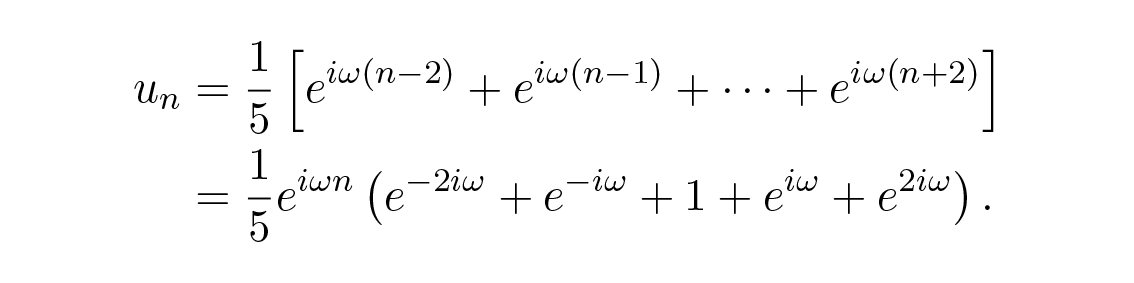
ดังนั้น eigenvalue ที่ความถี่ ω (transfer function) จากตรีโกณมิติพื้นฐานคือ
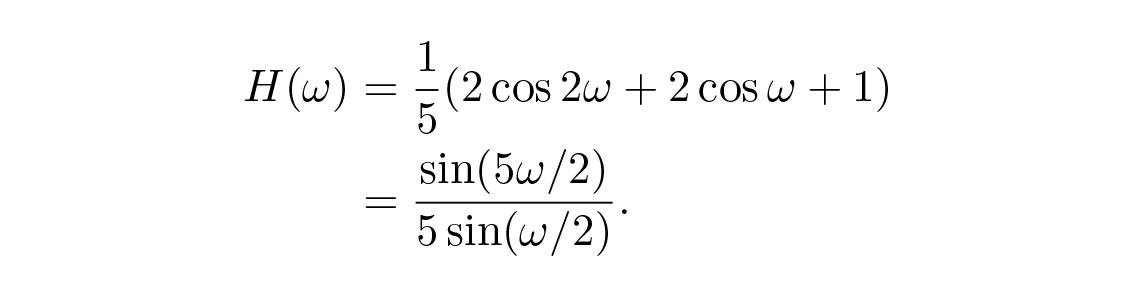
ในกรณีการปรับเรียบแบบพาราโบลาเราจะได้
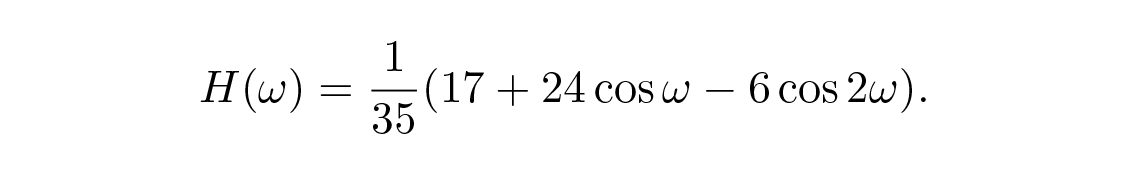
สิ่งเหล่านี้สามารถวาดได้ง่ายพร้อมกับเส้นโค้งการปรับเรียบ 2 k + 1 แบบเส้นตรง Figures 14.4 และ 14.5
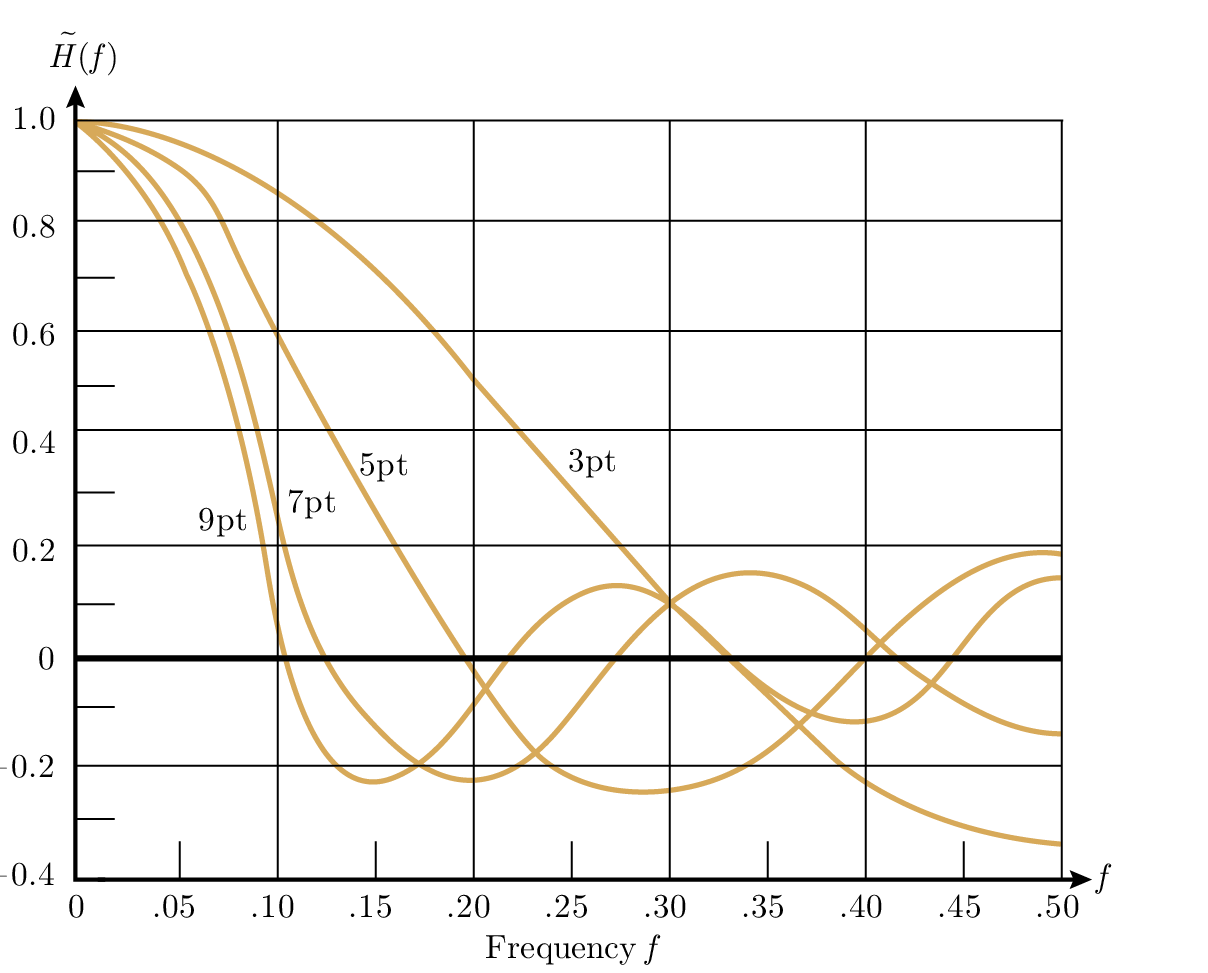
Figure 14.4—Transfer function for smoothing by least squares straight lines (ฟังก์ชันถ่ายโอนสำหรับการปรับเรียบด้วย least squares เส้นตรง)
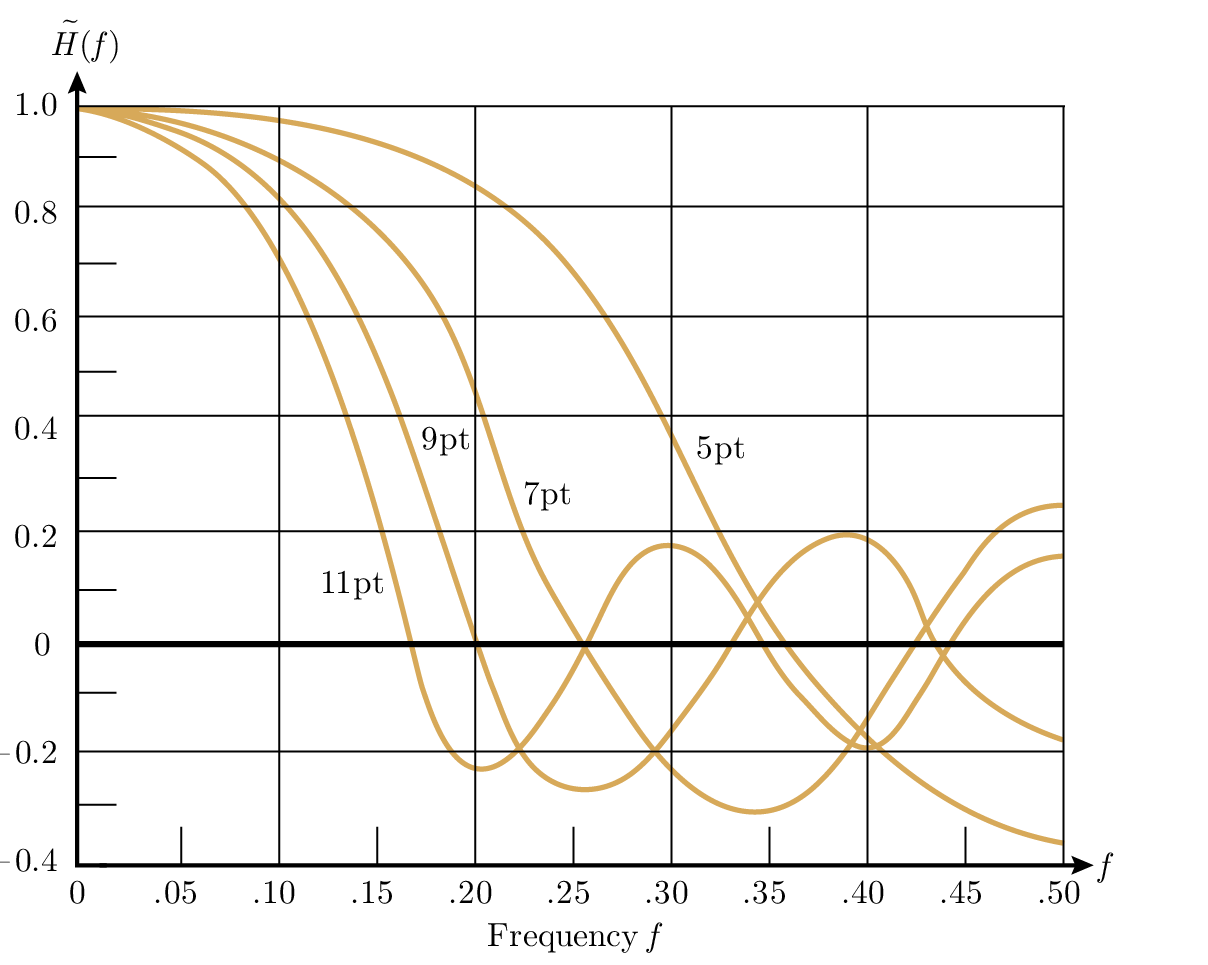
Figure 14.5—Transfer function for smoothing by least squares quadratics (ฟังก์ชันถ่ายโอนสำหรับการปรับเรียบด้วย least squares สมการกำลังสอง)
สูตรการปรับเรียบ มีความสมมาตรแบบศูนย์กลางในสัมประสิทธิ์ของมัน ในขณะที่ สูตรการหาอนุพันธ์ มีความสมมาตรแบบคี่ จากสูตรที่เห็นได้ชัด
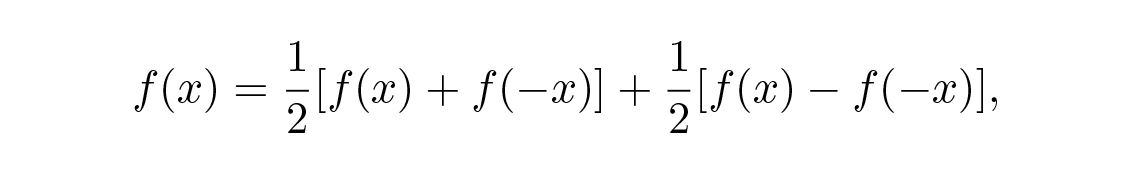
เราจะเห็นว่าสูตรใดๆ ก็ตามคือผลรวมของฟังก์ชันคี่และฟังก์ชันคู่ ดังนั้น nonrecursive digital filter ใดๆ ก็คือผลรวมของ smoothing filter และ differentiating filter เมื่อเราเข้าใจสองกรณีพิเศษนี้แล้ว เราก็จะเข้าใจกรณีทั่วไปได้
สำหรับสูตรการปรับเรียบ เราจะเห็นว่าเส้นโค้ง eigenvalue (transfer function) คือการขยายแบบ Fourier ในรูป cosine ในขณะที่สำหรับสูตรการหาอนุพันธ์ มันจะเป็นการขยายในรูป sine ดังนั้น เราจึงถูกนำไปสู่ปัญหาการขยายแบบ Fourier ของฟังก์ชันที่กำหนด เมื่อได้รับ transfer function ที่คุณต้องการ
ต่อไปเป็นการทบทวน Fourier series โดยสังเขป ถ้าเราสมมติว่าฟังก์ชันตามอำเภอใจ f ( t ) ถูกแทนด้วย
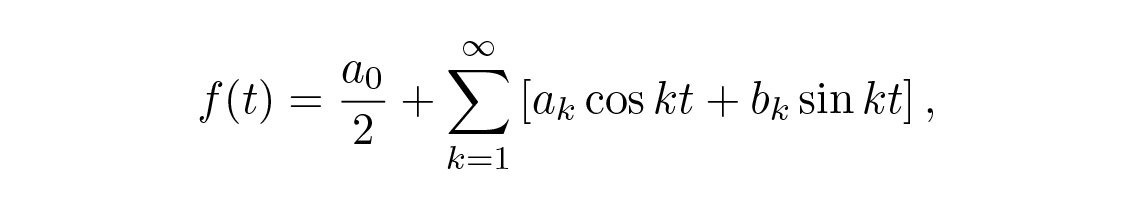
เราใช้เงื่อนไข orthogonal (ซึ่งหาได้จากตรีโกณมิติเบื้องต้นและการอินทิเกรตอย่างง่าย)
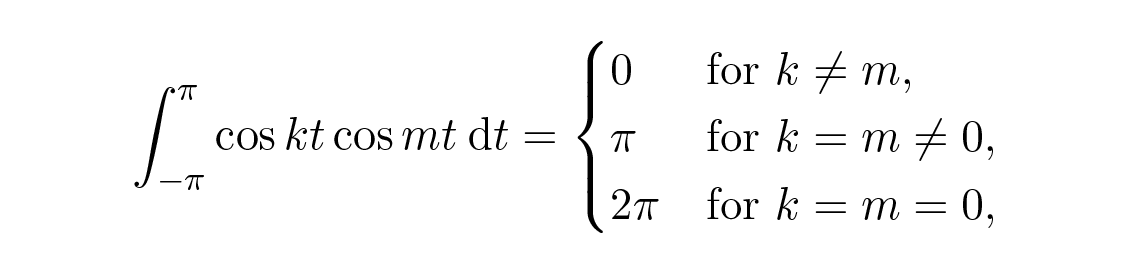
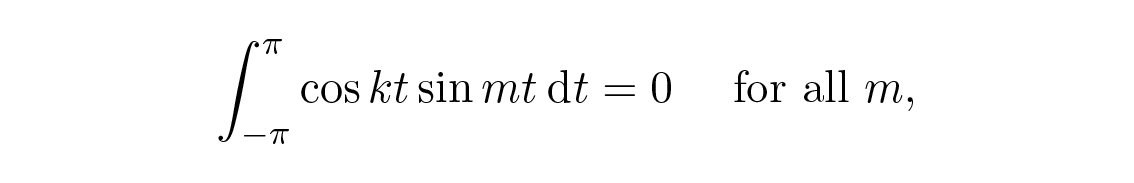
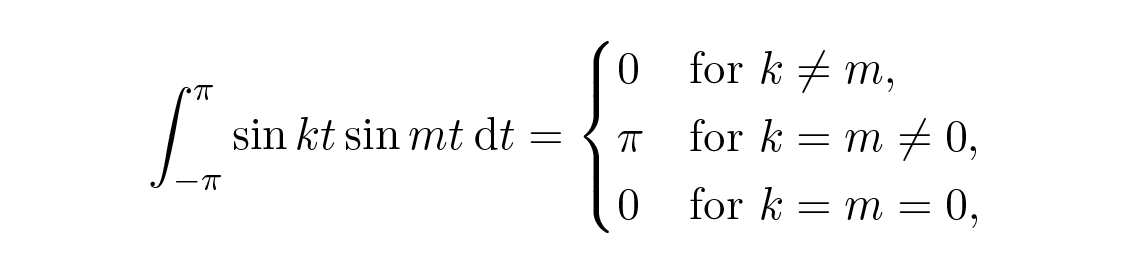
จะได้
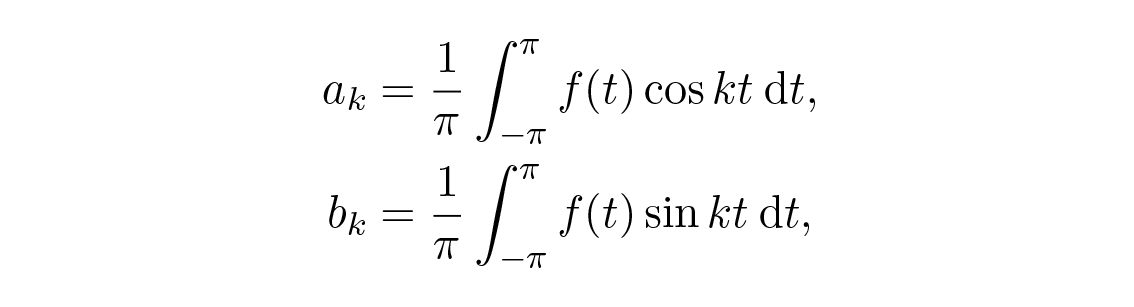
และเพราะเราใช้ a 0 /2 สำหรับสัมประสิทธิ์ตัวแรก สูตรเดียวกันสำหรับ a k จึงใช้ได้กับกรณี k \= 0 ด้วย ในสัญกรณ์เชิงซ้อนแน่นอนว่ามันง่ายกว่ามาก
ต่อไปเราต้องพิสูจน์ว่าการ fit ของ เซตใดๆ ของฟังก์ชัน orthogonal จะให้การ fit แบบ least squares ให้เซตของฟังก์ชัน orthogonal คือ { f k (t) } โดยมีฟังก์ชันถ่วงน้ำหนัก w ( t ) ≥ 0 . Orthogonality หมายถึง
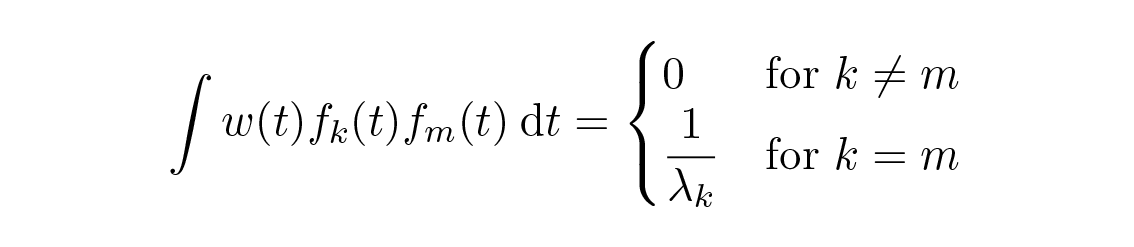
ดังที่กล่าวข้างต้น การกระจายแบบทางการจะให้สัมประสิทธิ์
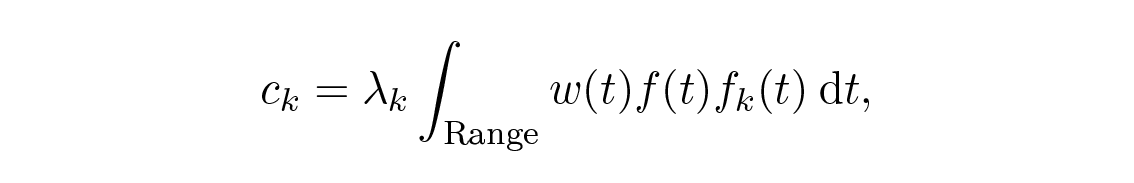
โดยที่
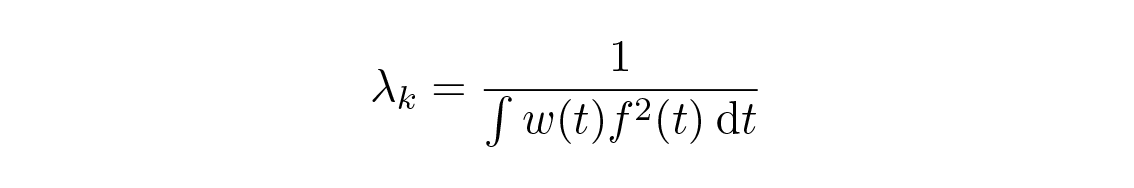
เมื่อฟังก์ชันเป็นจำนวนจริง และในกรณีของฟังก์ชันเชิงซ้อนเราจะคูณด้วย conjugate เชิงซ้อนของฟังก์ชัน
ทีนี้พิจารณาการ fit แบบ least squares ของเซตที่สมบูรณ์ของฟังก์ชัน orthogonal โดยใช้สัมประสิทธิ์ (ตัวพิมพ์ใหญ่) C k เราจะได้
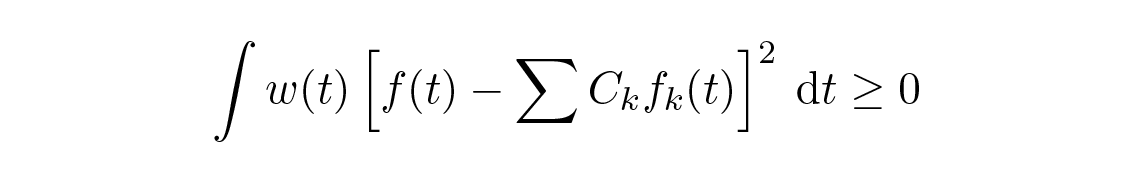
เพื่อหาค่าต่ำสุด หาอนุพันธ์เทียบกับ C m คุณจะได้
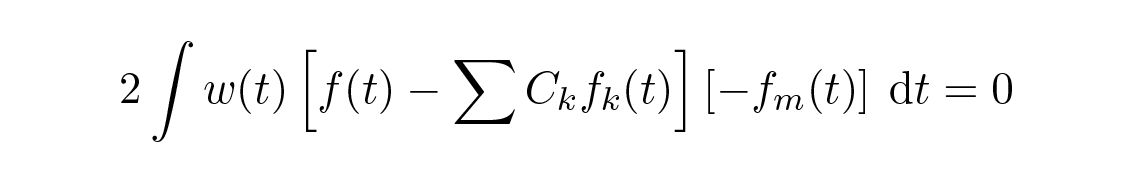
และจากการจัดเรียงใหม่เราจะเห็นว่า C k \= c k ดังนั้นการ fit ด้วยฟังก์ชัน orthogonal ทั้งหมดจึงเป็นการ fit แบบ least squares ไม่ว่าใช้เซตของฟังก์ชัน orthogonal ใดก็ตาม
ถ้าเราติดตามอสมการ เราจะพบว่าในกรณีทั่วไปตาม Bessel's inequality
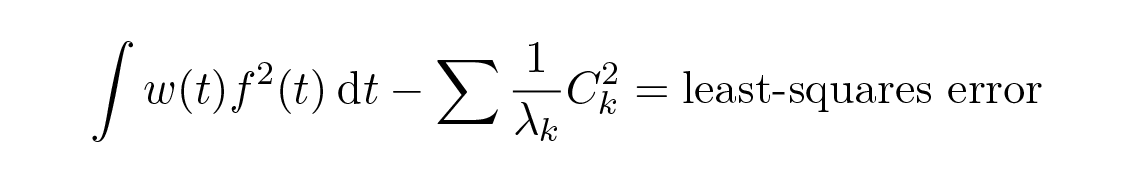
สำหรับจำนวนสัมประสิทธิ์ที่ใช้ในผลรวม และนี่เป็นตัวทดสอบแบบต่อเนื่องว่าเมื่อไรคุณมีพจน์มากพอในการประมาณแบบจำกัด ในทางปฏิบัติ ตัวนี้พิสูจน์แล้วว่าเป็นแนวทางที่มีประโยชน์มากว่าควรใช้กี่พจน์ในการกระจายแบบ Fourier