สองสิ่งที่ควรชัดเจนจากบทที่แล้ว อย่างแรกคือ เราต้องการให้ความยาวเฉลี่ย L ของข้อความที่ส่งมีค่าน้อยที่สุดเท่าที่จะทำได้ (เพื่อประหยัดทรัพยากร) อย่างที่สองคือ มันต้องเป็นทฤษฎีทางสถิติ เพราะเราไม่สามารถรู้ล่วงหน้าได้ว่าจะต้องส่งข้อความอะไรบ้าง แต่เราสามารถรู้ค่าทางสถิติบางส่วนได้จากการใช้ข้อความในอดีต รวมกับสมมติฐานว่าอนาคตอาจจะคล้ายกับอดีต สำหรับทฤษฎีที่ง่ายที่สุด ซึ่งเป็นเท่าที่เราจะพูดถึงได้ในที่นี้ เราจะต้องทราบความน่าจะเป็นของแต่ละสัญลักษณ์ที่ปรากฏในข้อความ วิธีการหาค่าเหล่านี้ไม่ใช่ส่วนหนึ่งของทฤษฎี แต่สามารถหาได้จากการตรวจสอบประสบการณ์ในอดีต หรือการคาดเดาอย่างสร้างสรรค์เกี่ยวกับการใช้งานระบบที่คุณกำลังออกแบบในอนาคต
ดังนั้นเราต้องการโค้ดที่ถอดรหัสได้ทันที ( instantaneous) และถอดรหัสได้แบบไม่ซ้ำ ( uniquely decodable) สำหรับชุดสัญลักษณ์นำเข้าที่กำหนด s i พร้อมกับความน่าจะเป็น p i เราควรกำหนดความยาว l i เท่าใด (โดยตระหนักว่าเราต้องปฏิบัติตาม Kraft inequality) เพื่อให้ได้ความยาวโค้ดเฉลี่ยต่ำที่สุด? Huffman เป็นผู้แก้ปัญหาการออกแบบโค้ดนี้
Huffman เป็นคนแรกที่แสดงให้เห็นว่าอสมการลำดับ ( running inequalities ) ต่อไปนี้ต้องเป็นจริงสำหรับโค้ดที่มีความยาวน้อยที่สุด ถ้า p i เรียงจากมากไปน้อย l i ก็ต้องเรียงจากน้อยไปมาก:
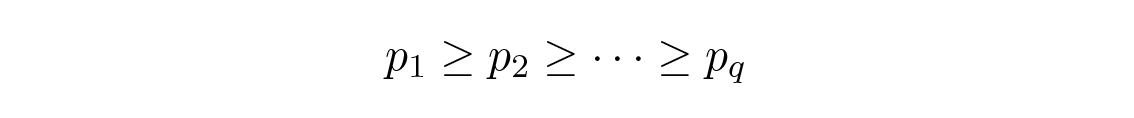
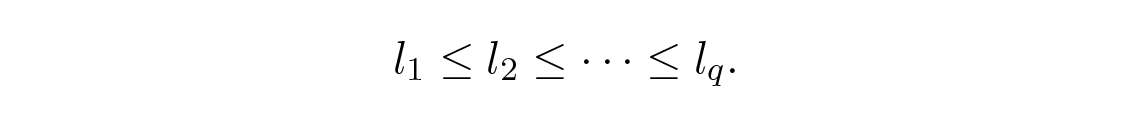
สมมติว่า p i เรียงลำดับแบบนี้ แต่มี l i อย่างน้อยหนึ่งคู่ที่ไม่ได้เรียงตามลำดับ ลองพิจารณาผลของการสลับสัญลักษณ์ที่ติดอยู่กับสองตัวที่ไม่ได้เรียงลำดับ ก่อนการสลับ สองเทอมนี้มีส่วนทำให้ความยาวโค้ดเฉลี่ย L เป็นจำนวน
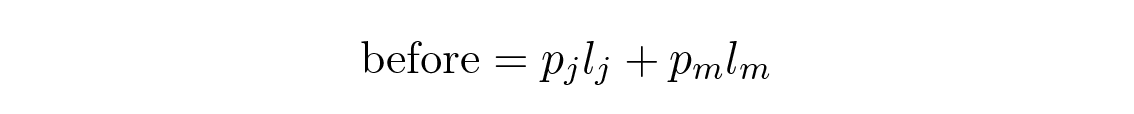
และหลังการสลับ เทอมเหล่านี้จะมีส่วนช่วยเป็น
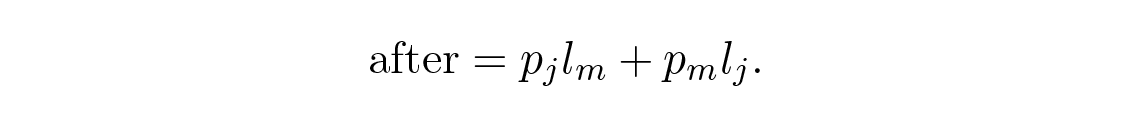
เทอมอื่น ๆ ทั้งหมดในผลรวม L จะยังคงเหมือนเดิม ส่วนต่างสามารถเขียนได้เป็น
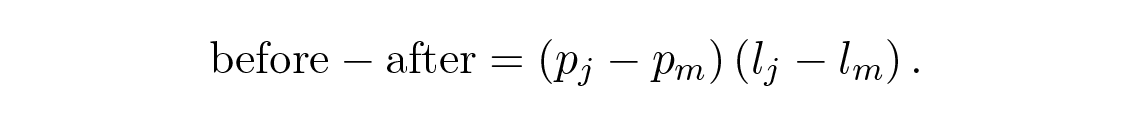
หนึ่งในสองตัวประกอบนี้ถูกสมมติให้เป็นลบ ดังนั้นเมื่อสลับสัญลักษณ์ทั้งสอง เราจะสังเกตเห็นว่าความยาวโค้ดเฉลี่ย L ลดลง ดังนั้นสำหรับโค้ดที่มีความยาวน้อยที่สุด เราจึงต้องมีอสมการลำดับทั้งสองนี้
จากนั้น Huffman สังเกตว่าโค้ดที่ถอดรหัสได้ทันที ( instantaneously decodable code ) จะมีแผนภาพการตัดสินใจ ( decision tree ) และทุกโหนดตัดสินใจควรมีทางออกสองทาง มิฉะนั้นจะเป็นการสูญเปล่า ดังนั้นจึงมีสัญลักษณ์ที่ยาวที่สุดสองตัวที่มีความยาวเท่ากัน
เพื่ออธิบาย Huffman coding เราจะใช้ตัวอย่างคลาสสิก ให้ p ( s 1 ) = 0.4 , p ( s 2 ) = 0.2 , p ( s 3 ) = 0.2 , p ( s 4 ) = 0.1 , และ p ( s 5 ) = 0.1 . เราแสดงไว้ใน Figure 11.1 . จากนั้น Huffman ให้เหตุผลจากสิ่งที่กล่าวมาข้างต้นว่าเขาสามารถรวม ( merge ) สัญลักษณ์ที่พบน้อยที่สุดสองตัว (ซึ่งต้องมีความยาวเท่ากัน) เข้าด้วยกันเป็นสัญลักษณ์เดียวที่มีความน่าจะเป็นรวมกัน โดยใช้บิตร่วมกันจนถึงบิตสุดท้ายที่ถูกตัดออกไป ทำให้ลดจำนวนสัญลักษณ์โค้ดลงหนึ่งตัว ทำซ้ำแบบนี้ไปเรื่อย ๆ จนกระทั่งเหลือระบบที่มีเพียงสองสัญลักษณ์ ซึ่งเขารู้วิธีกำหนดรหัสให้แล้ว นั่นคือสัญลักษณ์หนึ่งเป็น 0 และอีกสัญลักษณ์หนึ่งเป็น 1 .
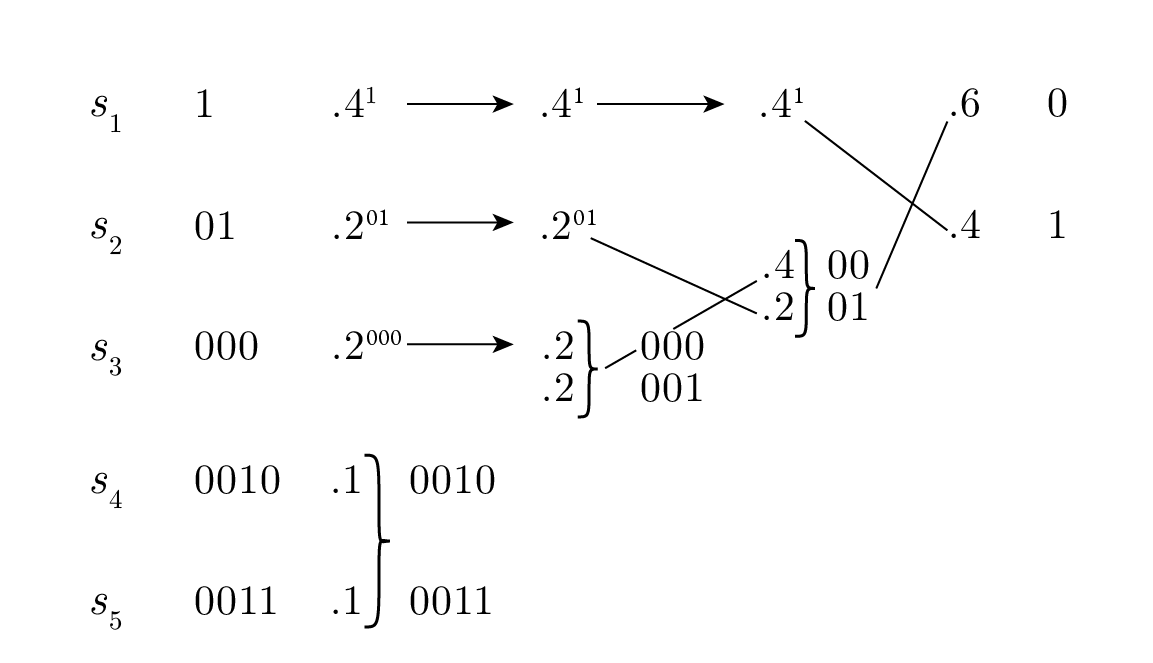
Figure 11.1—การเข้ารหัสแบบ Huffman (Huffman encoding)
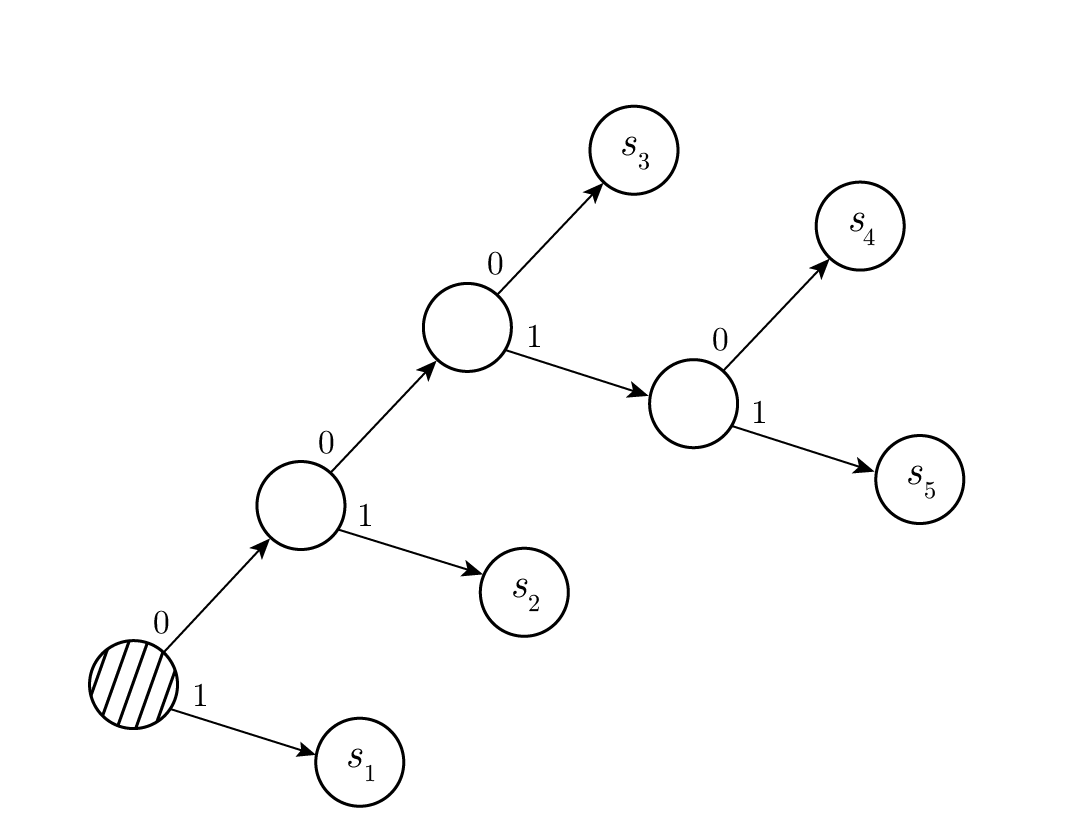
Figure 11.2—แผนภาพการถอดรหัส (Decoding tree)
ในการย้อนกลับเพื่อยกเลิกขั้นตอนการรวม ในแต่ละขั้นตอนเราจะต้องแยกสัญลักษณ์ที่เกิดจากการรวมของสองสัญลักษณ์ออกจากกัน โดยคงบิตนำหน้า ( leading bits ) เดิมไว้ แต่เพิ่ม 0 ให้กับสัญลักษณ์หนึ่ง และเพิ่ม 1 ให้กับอีกสัญลักษณ์หนึ่ง ด้วยวิธีนี้เขาจะได้โค้ดที่มีค่า L ต่ำที่สุด ดูเพิ่มเติมใน Figure 11.1 เพราะถ้ามีโค้ดอื่นที่มีความยาวน้อยกว่า L' การทำขั้นตอนไปข้างหน้า ซึ่งเปลี่ยนแปลงความยาวโค้ดเฉลี่ยด้วยจำนวนคงที่ จะทำให้ในที่สุดเราได้สองสัญลักษณ์ที่มีความยาวโค้ดเฉลี่ยน้อยกว่า 1 —ซึ่งเป็นไปไม่ได้ ดังนั้น Huffman encoding จึงให้โค้ดที่มีความยาวน้อยที่สุด ดู Figure 11.2 สำหรับแผนภาพการถอดรหัสที่สอดคล้องกัน
โค้ดที่ได้นั้นไม่จำเป็นต้องมีรูปแบบเดียว ขั้นแรก ในแต่ละขั้นตอนของกระบวนการย้อนกลับ เราสามารถกำหนดได้ตามอำเภอใจว่าสัญลักษณ์ไหนจะได้ 0 และสัญลักษณ์ไหนจะได้ 1 ประการที่สอง ถ้าในขั้นตอนใดมีสองสัญลักษณ์ที่มีความน่าจะเป็นเท่ากัน ก็ไม่สำคัญว่าอันไหนจะถูกวางไว้เหนืออีกอันหนึ่ง บางครั้งสิ่งนี้อาจทำให้เกิดโค้ดที่ดูแตกต่างกันมาก แต่มีความยาวโค้ดเฉลี่ยเท่ากัน
ถ้าเราวางเทอมที่รวมกันแล้วไว้สูงที่สุดเท่าที่จะทำได้ เราจะได้ Figure 11.3 พร้อมกับแผนภาพการถอดรหัสที่สอดคล้องกันใน Figure 11.4 ความยาวเฉลี่ยของโค้ดทั้งสองนั้นเท่ากัน แต่โค้ดและแผนภาพการถอดรหัสต่างกัน แบบแรกเป็นแบบ "ยาว" ( long ) และแบบที่สองเป็นแบบ "เป็นพุ่ม" ( bushy ) โดยแบบที่สองจะมีความแปรปรวนน้อยกว่าแบบแรก
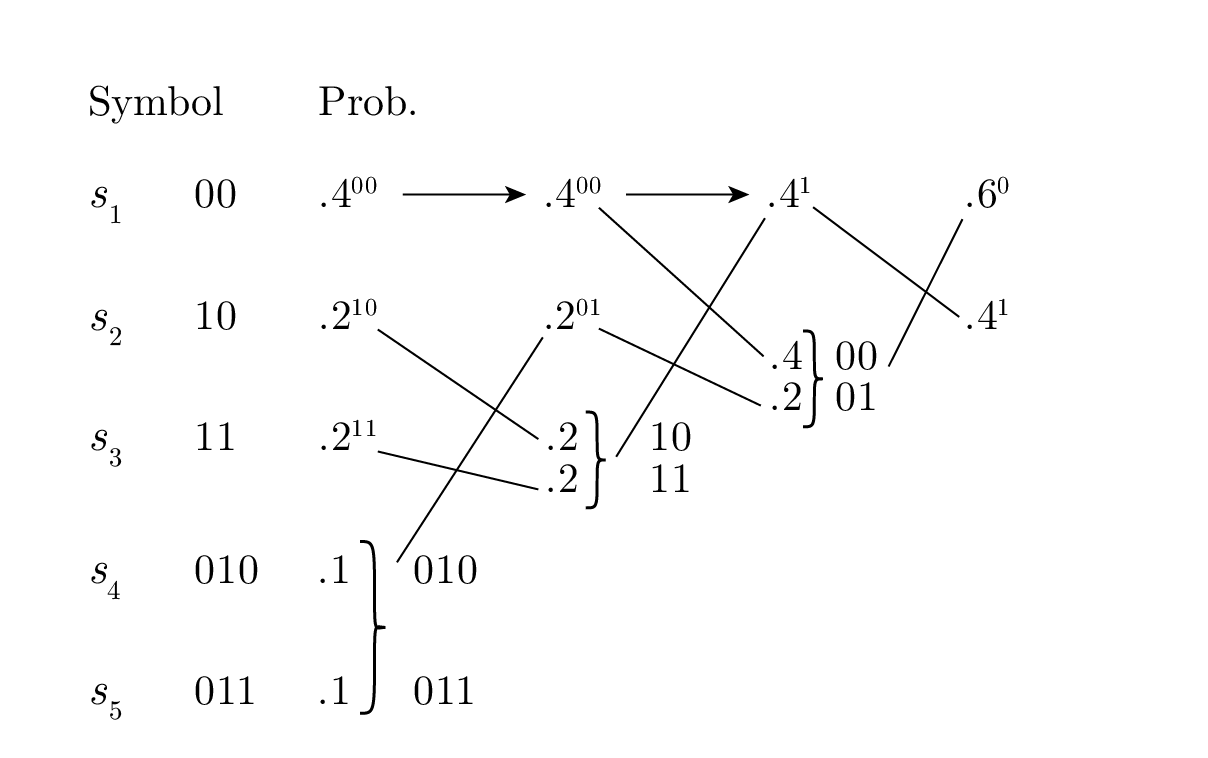
Figure 11.3—การเข้ารหัสแบบ Huffman (Huffman encoding)
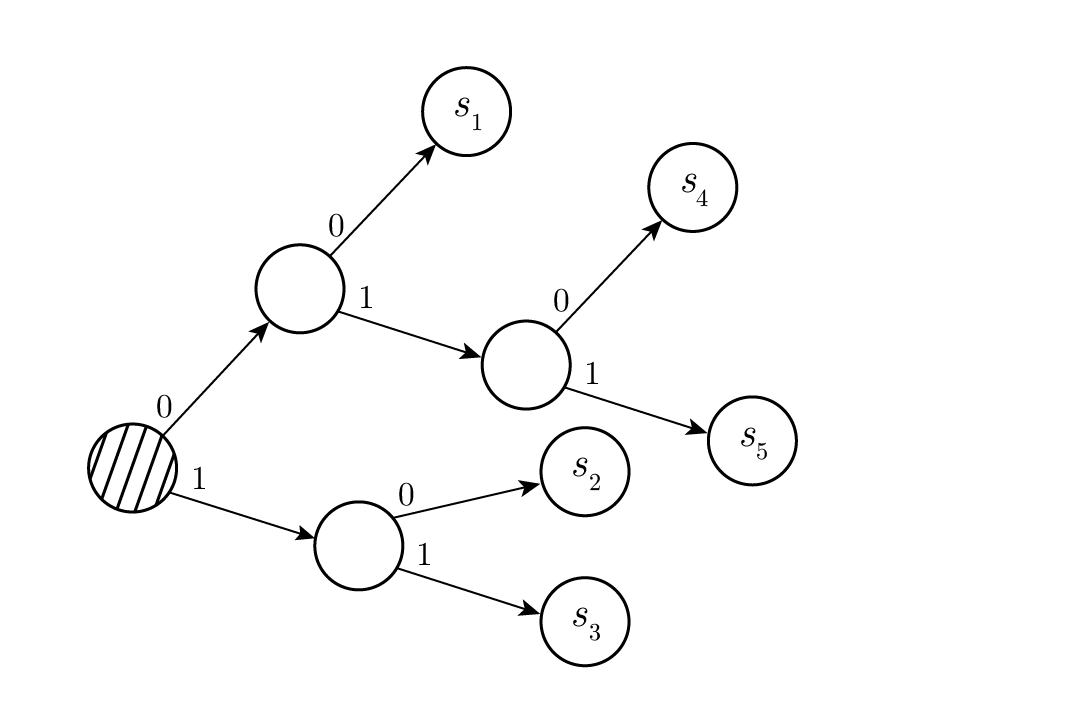
Figure 11.4—แผนภาพการถอดรหัส (Decoding tree)
ตอนนี้เราจะทำตัวอย่างที่สองเพื่อให้แน่ใจว่าคุณเข้าใจวิธีการทำงานของ Huffman encoding เนื่องจากเป็นเรื่องธรรมชาติที่คุณจะต้องการใช้ความยาวโค้ดเฉลี่ยที่สั้นที่สุดเมื่อออกแบบระบบเข้ารหัส ตัวอย่างเช่น คุณอาจมีข้อมูลจำนวนมากที่ต้องเก็บลงใน backup store และการเข้ารหัสด้วย Huffman code ที่เหมาะสมนั้น บางครั้งสามารถประหยัดพื้นที่จัดเก็บได้มากกว่าครึ่งหนึ่ง! ให้ p ( s 1 ) = 1/3 , p ( s 2 ) = 1/5 , p ( s 3 ) = 1/6 , p ( s 4 ) = 1/10 , p ( s 5 ) = 1/12 , p ( s 6 ) = 1/20 , p ( s 7 ) = 1/30 , และ p ( s 8 ) = 1/30 . ก่อนอื่นเราต้องตรวจสอบว่าความน่าจะเป็นรวมเป็น 1 . ตัวส่วนร่วมของเศษส่วนเหล่านี้คือ 60 . ดังนั้นเราจึงได้ความน่าจะเป็นรวม
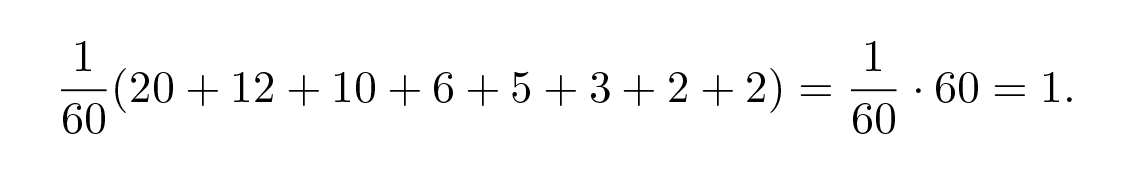
ตัวอย่างที่สองนี้แสดงไว้ใน Figure 11.5 โดยที่เราตัด 60 ในตัวส่วนของความน่าจะเป็นออกไป เพราะมีเฉพาะขนาดสัมพัทธ์เท่านั้นที่สำคัญ ความยาวโค้ดเฉลี่ยต่อสัญลักษณ์เป็นเท่าใด? เราคำนวณ:
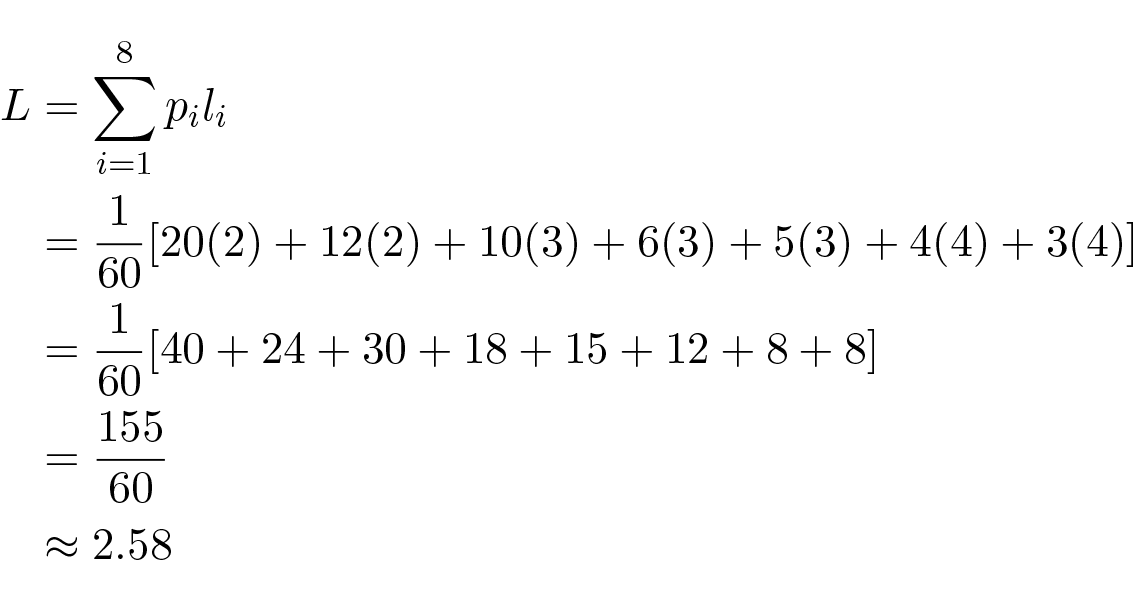
สำหรับ block code ของแปดสัญลักษณ์ แต่ละสัญลักษณ์จะมีความยาว 3 และค่าเฉลี่ยจะเป็น 3 ซึ่งมากกว่า 2.58 .
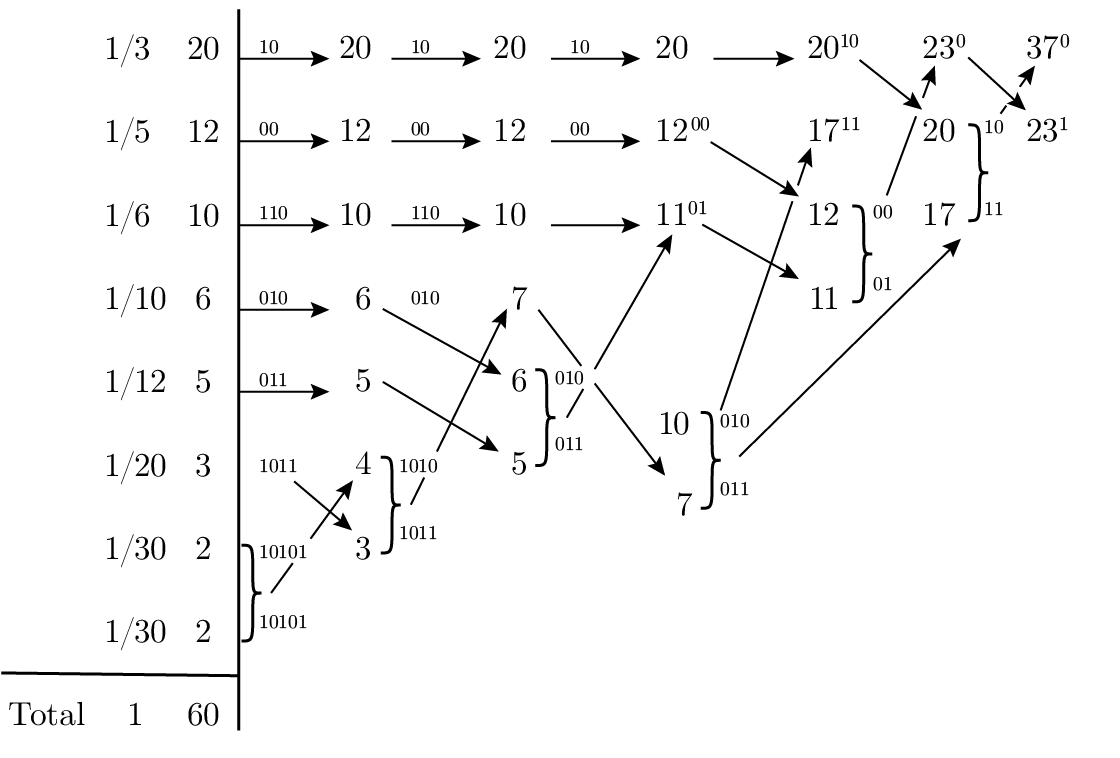
Figure 11.5—การเข้ารหัสแบบ Huffman (Huffman encoding)
สังเกตว่ากระบวนการนี้เป็นกลไกที่เครื่องสามารถทำได้ง่ายเพียงใด แต่ละขั้นตอนไปข้างหน้าสำหรับ Huffman code คือการทำซ้ำกระบวนการเดิม คือ รวมความน่าจะเป็นต่ำที่สุดสองค่า วางผลรวมใหม่ในตำแหน่งที่เหมาะสมใน Array และทำเครื่องหมายไว้ ในกระบวนการย้อนกลับ ให้นำสัญลักษณ์ที่ถูกทำเครื่องหมายมาแยกออก สิ่งเหล่านี้เป็นโปรแกรมง่าย ๆ ที่เขียนขึ้นสำหรับคอมพิวเตอร์ ดังนั้นโปรแกรมคอมพิวเตอร์สามารถหา Huffman code ได้เมื่อได้รับ s i และความน่าจะเป็น p i จำไว้ว่าในทางปฏิบัติ คุณต้องกำหนด escape symbol ที่มีความน่าจะเป็นน้อยมากเพื่อให้สามารถออกจากกระบวนการถอดรหัสเมื่อสิ้นสุดข้อความ อันที่จริง คุณสามารถเขียนโปรแกรมที่สุ่มตัวอย่างข้อมูลที่จะจัดเก็บ หาค่าประมาณของความน่าจะเป็น (ความผิดพลาดเล็กน้อยทำให้ L เปลี่ยนแปลงเพียงเล็กน้อย) หา Huffman code ทำการเข้ารหัส และส่งอัลกอริทึมการถอดรหัส (แผนภาพ) ก่อนแล้วจึงส่งข้อมูลที่เข้ารหัสตามหลัง ทั้งหมดนี้โดยไม่ต้องใช้มนุษย์ช่วยหรือต้องคิดใด ๆ ! ฝั่งถอดรหัสได้รับแผนภาพการถอดรหัสเรียบร้อยแล้ว ดังนั้นเมื่อเขียนเป็น library program แล้ว คุณสามารถใช้มันได้ทุกครั้งที่คิดว่ามันจะเป็นประโยชน์
Huffman codes ถูกนำไปใช้ในคอมพิวเตอร์บางรุ่นแม้กระทั่งในส่วนคำสั่ง ( instruction part ) ของคำสั่งเครื่อง เนื่องจากคำสั่งต่าง ๆ มีความน่าจะเป็นในการถูกใช้งานที่แตกต่างกันมาก ดังนั้นเราจึงต้องพิจารณาถึงประโยชน์ที่ได้รับในแง่ของความยาวโค้ดเฉลี่ย L ที่เราคาดหวังได้จากการใช้ Huffman encoding เทียบกับ block encoding ทั่วไป ซึ่งใช้สัญลักษณ์ที่มีความยาวเท่ากันทั้งหมด
ถ้าความน่าจะเป็นทั้งหมดเท่ากันและมีสัญลักษณ์ 2 k ตัวพอดี การตรวจสอบกระบวนการของ Huffman จะแสดงให้เห็นว่าคุณจะได้ block code มาตรฐานที่สัญลักษณ์ทุกตัวมีความยาวเท่ากัน ถ้าคุณไม่มีสัญลักษณ์ครบ 2 k ตัว สัญลักษณ์บางตัวจะสั้นลง แต่เป็นการยากที่จะบอกว่าหลายตัวจะสั้นลงหนึ่งบิตหรือไม่ บางตัวอาจสั้นลงสองบิตหรือมากกว่า ไม่ว่าในกรณีใด ค่าของ L จะเท่าเดิม และไม่น้อยไปกว่า block code ที่สอดคล้องกันมากนัก
ในทางกลับกัน ถ้าแต่ละ p i มีค่ามากกว่าสองในสามของผลรวมของความน่าจะเป็นทั้งหมดที่ตามมา ยกเว้นตัวสุดท้าย คุณจะได้ comma code ซึ่งมีสัญลักษณ์หนึ่งตัวที่มีความยาว 1 (0) , หนึ่งตัวที่มีความยาว 2 (10) , ไปเรื่อย ๆ จนถึงตัวสุดท้าย โดยที่ปลายสุดคุณจะมีสองสัญลักษณ์ที่มีความยาวเท่ากัน q – 1 , 1111…10 และ 1111…11 ในกรณีนี้ ค่าของ L สามารถน้อยกว่า block code ที่สอดคล้องกันได้มาก
กฎ: Huffman coding ให้ประโยชน์เมื่อความน่าจะเป็นของสัญลักษณ์แตกต่างกันมาก และให้ประโยชน์ไม่มากนักเมื่อความน่าจะเป็นทั้งหมดค่อนข้างเท่าเทียมกัน
เมื่อมีความน่าจะเป็นเท่ากันเกิดขึ้นในกระบวนการ Huffman สามารถวางไว้ในลำดับใดก็ได้ ดังนั้นโค้ดที่ได้อาจแตกต่างกันมาก แม้ว่าความยาวโค้ดเฉลี่ยในทั้งสองกรณีจะเท่ากันคือ L จึงเป็นคำถามธรรมชาติว่าควรเลือกลำดับใดเมื่อความน่าจะเป็นเท่ากัน เกณฑ์ที่สมเหตุสมผลคือการลดความแปรปรวน ( variance ) ของโค้ด เพื่อให้ข้อความที่มีความยาวเท่ากันในสัญลักษณ์ต้นฉบับมีความยาวใกล้เคียงกันในข้อความที่เข้ารหัส คุณไม่ต้องการให้ข้อความต้นฉบับสั้น ๆ ถูกเข้ารหัสกลายเป็นข้อความที่ยาวมากโดยบังเอิญ กฎง่าย ๆ คือ ให้วางความน่าจะเป็นใหม่เมื่อแทรกลงในตารางให้สูงที่สุดเท่าที่จะทำได้ อันที่จริง ถ้าคุณวางมันเหนือสัญลักษณ์ที่มีความน่าจะเป็นสูงกว่าเล็กน้อย โดยปกติแล้วคุณจะลดความแปรปรวนลงได้มาก และในขณะเดียวกันก็เพิ่ม L เพียงเล็กน้อยเท่านั้น ดังนั้นจึงเป็นกลยุทธ์ที่ดีที่จะใช้
หลังจากที่เราทำทุกอย่างที่ต้องการเกี่ยวกับ source encoding (ถึงแม้เราจะยังพูดถึงหัวข้อนี้ไม่หมดก็ตาม) เราจะหันไปที่ channel encoding ซึ่ง noise ถูกนำมาเป็นแบบจำลอง ช่องสัญญาณโดยสมมติมี noise หมายความว่าบางบิตถูกเปลี่ยนแปลงไประหว่างการส่ง (หรือการจัดเก็บ) เราทำอะไรได้บ้าง?
การตรวจจับความผิดพลาดเดี่ยว ( single error ) ทำได้ง่าย สำหรับบล็อกของ n – 1 บิต เราเพิ่มบิตที่ n เข้าไป โดยตั้งค่าให้บิตทั้งหมด n บิตมีจำนวน 1 เป็นเลขคู่ (หรือเลขคี่ถ้าต้องการ แต่ในทางทฤษฎีเราจะใช้เลขคู่) เรียกว่า even (odd) parity check หรือเรียกสั้น ๆ ว่า parity check .
ดังนั้นถ้าข้อความทั้งหมดที่ฉันส่งให้คุณมีคุณสมบัตินี้ ฝั่งรับก็สามารถตรวจสอบได้ว่าเงื่อนไขเป็นไปตามที่กำหนดหรือไม่ ถ้า parity check ไม่ผ่าน คุณจะรู้ว่ามีความผิดพลาดเกิดขึ้นอย่างน้อยหนึ่งครั้ง อันที่จริง คุณรู้ว่ามีความผิดพลาดเกิดขึ้นเป็นจำนวนคี่ ถ้า parity ผ่าน แสดงว่าข้อความนั้นถูกต้อง หรือไม่ก็มีความผิดพลาดเป็นจำนวนคู่ เนื่องจากเป็นการรอบคอบที่จะใช้ระบบที่ความน่าจะเป็นของความผิดพลาดในตำแหน่งใด ๆ นั้นต่ำ ความน่าจะเป็นของความผิดพลาดหลายครั้งจึงต้องต่ำกว่ามาก
เพื่อความสะดวกในการคำนวณทางคณิตศาสตร์ เราจะสมมติว่าช่องสัญญาณมี white noise หมายความว่า: (1) แต่ละตำแหน่งในบล็อกของ n บิตมีความน่าจะเป็นที่จะเกิดความผิดพลาดเท่ากับตำแหน่งอื่น ๆ และ (2) ความผิดพลาดในตำแหน่งต่าง ๆ ไม่สัมพันธ์กัน ( uncorrelated ) หมายถึงเป็นอิสระต่อกัน ภายใต้สมมติฐานเหล่านี้ ความน่าจะเป็นของความผิดพลาดคือ:
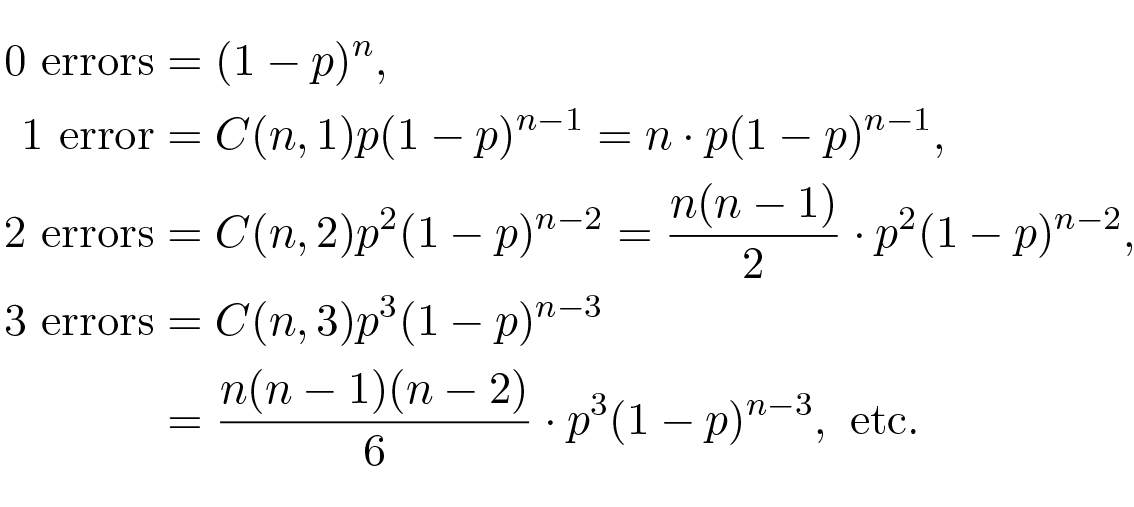
จากนี้ ถ้า p มีค่าน้อยเมื่อเทียบกับความยาวบล็อก n (หมายถึงผลคูณ np น้อย) ความผิดพลาดหลายครั้งจะเกิดขึ้นได้น้อยกว่าความผิดพลาดเดี่ยวมาก เป็นการตัดสินใจทางวิศวกรรมว่าจะทำให้ n ยาวเท่าใดสำหรับความน่าจะเป็นของความผิดพลาด p ที่กำหนด ถ้า n มีค่าน้อย คุณจะมีความซ้ำซ้อน ( redundancy — อัตราส่วนของจำนวนบิตที่ส่งต่อจำนวนบิตต่ำสุดที่เป็นไปได้ n/ ( n – 1)) สูงกว่าเมื่อเทียบกับ n ที่ใหญ่กว่า แต่ถ้า np มีค่ามาก คุณจะมีความซ้ำซ้อนต่ำแต่มีความน่าจะเป็นสูงกว่าที่ความผิดพลาดจะไม่ถูกตรวจจับ คุณต้องตัดสินใจทางวิศวกรรมว่าคุณจะสร้างสมดุลระหว่างสองผลกระทบนี้อย่างไร
เมื่อคุณพบความผิดพลาดเดี่ยว คุณสามารถขอให้ส่งซ้ำ ( retransmission ) และคาดหวังว่าจะได้ข้อมูลที่ถูกต้องในครั้งที่สอง ถ้าไม่ก็ครั้งที่สาม ฯลฯ อย่างไรก็ตาม ถ้าข้อความในพื้นที่จัดเก็บผิดพลาด คุณจะเรียกให้ส่งซ้ำไปเรื่อย ๆ จนกว่าจะเกิดความผิดพลาดอีกครั้ง และคุณอาจจะมีความผิดพลาดสองครั้งซึ่งจะไม่ถูกตรวจจับในรูปแบบการตรวจจับความผิดพลาดเดี่ยวนี้ ดังนั้นการใช้การส่งซ้ำซ้ำ ๆ ควรขึ้นอยู่กับลักษณะที่คาดหวังของความผิดพลาด
โค้ดเหล่านี้ถูกใช้อย่างแพร่หลายแม้ในยุคของรีเลย์ บริษัทโทรศัพท์ในสำนักงานกลาง ( central offices ) และในคอมพิวเตอร์รีเลย์รุ่นแรก ๆ หลายรุ่นใช้โค้ด 2-out-of-5 ซึ่งหมายถึงรีเลย์สองตัวและเพียงสองตัวจากห้าตัวเท่านั้นที่ต้องเป็น "เปิด" โค้ดนี้ใช้แทนเลขฐานสิบ เนื่องจาก C (5, 2) = 10 ถ้าไม่ใช่สองรีเลย์พอดีที่เปิดอยู่ ก็ถือว่าเกิดความผิดพลาดและต้องทำซ้ำ นอกจากนี้ยังมีการใช้โค้ด 3-out-of-7 ซึ่งเห็นได้ชัดว่าเป็น odd parity check code
ฉันพบโค้ด 2-out-of-5 เหล่านี้ครั้งแรกขณะใช้คอมพิวเตอร์รีเลย์ Model 5 ที่ Bell Labs และรู้สึกประทับใจ ไม่เพียงแต่มันช่วยให้ได้คำตอบที่ถูกต้องเท่านั้น แต่ที่สำคัญกว่านั้น ในความคิดของฉัน มันช่วยให้ทีมบำรุงรักษาสามารถดูแลรักษาเครื่องได้ ความผิดพลาดใด ๆ จะถูกตรวจจับโดยเครื่องเกือบจะทันทีที่เกิดขึ้น และด้วยเหตุนี้จึงชี้ให้ทีมบำรุงรักษาทราบถึงจุดที่มีปัญหาอย่างถูกต้อง แทนที่จะให้พวกเขาลองผิดลองถูกกับส่วนนั้นส่วนนี้ ปรับแต่งชิ้นส่วนที่ดีอยู่แล้วผิดพลาดไปในความพยายามหาชิ้นส่วนที่เสีย
ถึงแม้จะออกนอกลำดับเวลา แต่ยังคงอยู่ในลำดับแนวคิด ครั้งหนึ่งฉันถูก at&t ขอให้ออกแบบวิธีการเข้ารหัสเมื่อมนุษย์ใช้ตัวอักษร 26 ตัว เลขฐานสิบ 10 ตัว และ "ช่องว่าง" ( space ) ซึ่งเป็นเรื่องปกติในการตั้งชื่อสินค้าคงคลัง การตั้งชื่อชิ้นส่วน และการตั้งชื่อสิ่งต่าง ๆ อีกมากมาย รวมถึงการตั้งชื่ออาคาร ฉันรู้จากข้อมูลความผิดพลาดในการหมุนโทรศัพท์ รวมถึงประสบการณ์ยาวนานในการคำนวณด้วยมือ ว่ามนุษย์มีแนวโน้มสูงที่จะสลับหลักที่อยู่ติดกัน (เช่น 67 มักจะกลายเป็น 76 ) รวมถึงเปลี่ยนหลักเดี่ยว ๆ (มักจะเพิ่มตัวเลขผิดตำแหน่งเป็นสองเท่า เช่น 556 มักจะกลายเป็น 566 ) ดังนั้นการตรวจจับความผิดพลาดเดี่ยวจึงไม่เพียงพอ ฉันพาคนที่ฉลาดมากสองคนเข้าไปในห้องประชุมและตั้งคำถาม ข้อเสนอแล้วข้อเสนอเล่าที่ฉันปฏิเสธเพราะยังดีไม่พอ จนกระทั่งหนึ่งในนั้น Ed Gilbert เสนอ weighted code โดยเฉพาะอย่างยิ่งเขาเสนอให้กำหนดตัวเลข (ค่า) 0 , 1 , 2 , …, 36 ให้กับสัญลักษณ์ 0 , 1 , …, 9 , A , B , …, Z , space จากนั้นเขาไม่ได้คำนวณผลรวมของค่า แต่ถ้าสัญลักษณ์ที่ k มีค่า (กำหนดให้สะดวก) คือ s k ดังนั้นสำหรับข้อความที่มี n สัญลักษณ์ เราคำนวณ
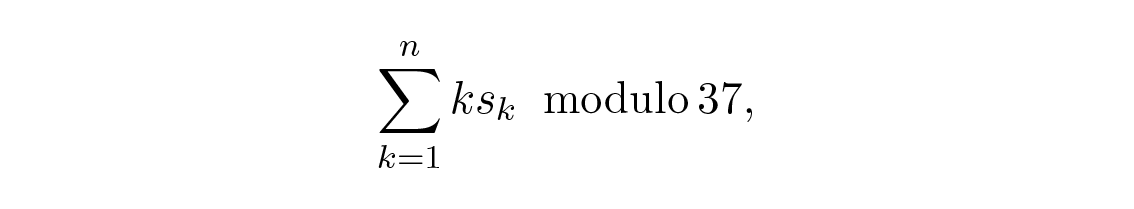
"modulo" หมายถึงการหาร weighted sum นี้ด้วย 37 และเก็บเฉพาะเศษ ในการเข้ารหัสข้อความที่มี n สัญลักษณ์ ให้เว้นสัญลักษณ์แรก k \= 1 ว่างไว้ แล้วนำเศษที่ได้ซึ่งมีค่าน้อยกว่า 37 ไปลบออกจาก 37 และใช้สัญลักษณ์ที่สอดคล้องกันเป็น check symbol ซึ่งจะถูกวางในตำแหน่งแรก ดังนั้นข้อความทั้งหมดเมื่อมี check symbol อยู่ในตำแหน่งแรก จะมี check sum เท่ากับ 0 พอดี เมื่อคุณพิจารณาการสลับที่ของสัญลักษณ์สองตัวที่แตกต่างกัน รวมถึงการเปลี่ยนสัญลักษณ์เดี่ยวใด ๆ คุณจะเห็นว่ามันทำลาย weighted parity check แบบ modulo 37 (โดยมีเงื่อนไขว่าสัญลักษณ์ที่สลับกันนั้นไม่ได้ห่างกัน 37 ตำแหน่งพอดี!) โดยไม่ต้องลงรายละเอียด สิ่งสำคัญคือ modulus ต้องเป็นจำนวนเฉพาะ ( prime number ) ซึ่ง 37 ก็เป็นจำนวนเฉพาะ
ในการหา weighted sum ของสัญลักษณ์ (หรือก็คือค่าของมัน) คุณสามารถหลีกเลี่ยงการคูณและใช้แค่การบวกและการลบเท่านั้นก็ได้ วางตัวเลขเรียงกันในคอลัมน์แล้วคำนวณผลรวมสะสม ( running sum ) จากนั้นคำนวณผลรวมสะสมของผลรวมสะสมแบบ modulo 37 แล้ว complement ค่านี้เทียบกับ 37 คุณก็จะได้ check symbol ตารางต่อไปนี้แสดงตัวอย่างโดยใช้ w , x , y , และ z .
| สัญลักษณ์ (Symbols) | ผลรวม (Sum) | ผลรวมของผลรวม (Sum of sums) |
|---|---|---|
| w | w | w |
| x | w + x | 2 w + x |
| y | w + x + y | 3 w + 2 x + y |
| z | w + x + y + z | 4 w + 3 x + 2 y + z
\= weighted check sum |
ที่ฝั่งรับ คุณลบ modulus ซ้ำ ๆ จนกว่าคุณจะได้ 0 (สัญลักษณ์ถูกต้อง) หรือเลขลบ (สัญลักษณ์ผิด)
ถ้าคุณใช้การเข้ารหัสนี้ ตัวอย่างเช่น สำหรับชื่อชิ้นส่วนในคลังสินค้า ครั้งแรกที่ชื่อชิ้นส่วนผิดมาถึงคอมพิวเตอร์ ไม่ว่าจะเป็นในช่วงการส่งข้อมูล หรือก่อนหน้านั้น (เช่นตอนเตรียมคำสั่งซื้อ) ความผิดพลาดจะถูกตรวจจับ คุณจะไม่ต้องรอจนกว่าคำสั่งซื้อจะถึงสำนักงานใหญ่เพื่อถูกบอกทีหลังว่าไม่มีชิ้นส่วนดังกล่าว หรือไม่ก็พวกเขาส่งชิ้นส่วนผิดมา! ก่อนที่มันจะออกจากที่ของคุณ มันจะถูกตรวจจับและแก้ไขได้ง่ายในเวลานั้น เล็กน้อยไหม? ใช่! มีประสิทธิภาพในการป้องกันความผิดพลาดของมนุษย์ (เมื่อเทียบกับ white noise ก่อนหน้านี้)? ใช่!
อันที่จริง คุณเห็นโค้ดแบบนี้บนหนังสือของคุณทุกวันนี้ในรูปแบบของ isbn s มันเป็นโค้ดเดียวกันยกเว้นว่าใช้เลขฐานสิบเพียงสิบตัว และเนื่องจากสิบไม่ใช่จำนวนเฉพาะ พวกเขาจึงต้องเพิ่มสัญลักษณ์ที่สิบเอ็ดชื่อ X ซึ่งบางครั้งอาจปรากฏใน parity check—อันที่จริง ทุก ๆ ประมาณสิบเอ็ดเล่มคุณจะมี X เป็นตัวเลข parity check ในสัญลักษณ์สุดท้ายของ isbn ขีดกลางมีไว้เพื่อการตกแต่งเท่านั้นและไม่ได้ใช้ในโค้ดเลย ลองตรวจสอบด้วยตัวคุณเองบนหนังสือเรียนของคุณ องค์กรขนาดใหญ่อื่น ๆ อีกมากมายสามารถใช้โค้ดเหล่านี้ให้เกิดประโยชน์ได้ ถ้าพวกเขาต้องการลงทุนทำ
ฉันได้กล่าวซ้ำแล้วซ้ำเล่าว่าฉันเชื่อว่าอนาคตจะเกี่ยวข้องกับข้อมูลในรูปแบบของสัญลักษณ์มากขึ้น และเกี่ยวข้องกับสิ่งของทางกายภาพน้อยลง ดังนั้นทฤษฎีการเข้ารหัส (การแทน) ข้อมูลในโค้ดที่สะดวกจึงเป็นหัวข้อที่ไม่ใช่เรื่องเล็กน้อย เนื้อหาข้างต้นได้ให้ตัวอย่างง่าย ๆ ของ error-detecting code สำหรับสถานการณ์แบบเครื่องจักร รวมถึง weighted code สำหรับการใช้งานของมนุษย์ สิ่งเหล่านี้เป็นเพียงสองตัวอย่างว่าทฤษฎีการเข้ารหัสสามารถช่วยองค์กรในจุดที่อาจเกิดความผิดพลาดของเครื่องจักรและมนุษย์ได้อย่างไร
เมื่อคุณคิดถึงอินเทอร์เฟซระหว่างมนุษย์กับเครื่อง สิ่งหนึ่งที่คุณต้องการคือให้มนุษย์กดแป้นพิมพ์น้อยครั้ง— Huffman encoding ในรูปแบบ disguised! เห็นได้ชัดว่า เมื่อกำหนดความน่าจะเป็นที่คุณจะเลือกกิ่งต่าง ๆ ในเมนูของโปรแกรม คุณสามารถออกแบบวิธีการที่ลดจำนวนการกดแป้นพิมพ์ทั้งหมดของคุณได้ถ้าต้องการ ดังนั้นชุดเมนูเดียวกันนี้สามารถปรับให้เข้ากับนิสัยการทำงานของคนแต่ละคนได้ แทนที่จะแสดงหน้าเดิมให้ทุกคนเห็น ในความหมายที่กว้างกว่านี้ "การเขียนโปรแกรมอัตโนมัติ" ( automatic programming ) ในภาษาระดับสูงเป็นการพยายามบรรลุสิ่งที่คล้ายกับ Huffman encoding เพื่อให้สำหรับปัญหาที่คุณต้องการแก้ไข คุณต้องกดแป้นพิมพ์ค่อนข้างน้อย และสำหรับปัญหาที่คุณไม่ต้องการ เป็นอีกเรื่องหนึ่ง