หลังจากที่ได้ศึกษาคอมพิวเตอร์และการทำงานของมันแล้ว ต่อไปเราจะมาดูปัญหาของ การแทน ข้อมูล—ว่า เราจะแทนข้อมูลที่ต้องการประมวลผลได้อย่างไร? จำไว้ว่าความหมายใดๆ ที่สัญลักษณ์หนึ่งๆ อาจมีนั้นขึ้นอยู่กับว่ามันถูกประมวลผลอย่างไร ไม่มีความหมายโดยเนื้อแท้ในบิตที่เครื่องจักรใช้งาน ในภาษาสังเคราะห์ที่กล่าวถึงในบทที่ 4 เกี่ยวกับประวัติศาสตร์ของซอฟต์แวร์ การแยกคำสั่งออกเป็นส่วนๆ นั้นแทบจะเหมือนกันสำหรับทุกคำสั่งในภาษา และนี่ก็เป็นจริงสำหรับภาษาส่วนใหญ่ "ความหมาย" ของคำสั่งใดๆ ก็ตามถูกกำหนดโดย subroutine ที่สอดคล้องกัน
เพื่อให้ปัญหาการแทนข้อมูลง่ายขึ้น ในตอนนี้เราจะพิจารณาเฉพาะปัญหาการถ่ายทอดข้อมูลจากที่หนึ่งไปยังอีกที่หนึ่งเท่านั้น ซึ่งก็เหมือนกับการถ่ายทอดจากปัจจุบันไปยังอนาคตนั่นคือการจัดเก็บข้อมูล การส่งผ่านเวลาหรือการส่งผ่านพื้นที่นั้นเป็นปัญหาเดียวกัน ระบบจำลองมาตรฐานแสดงอยู่ใน Figure 10.1 .
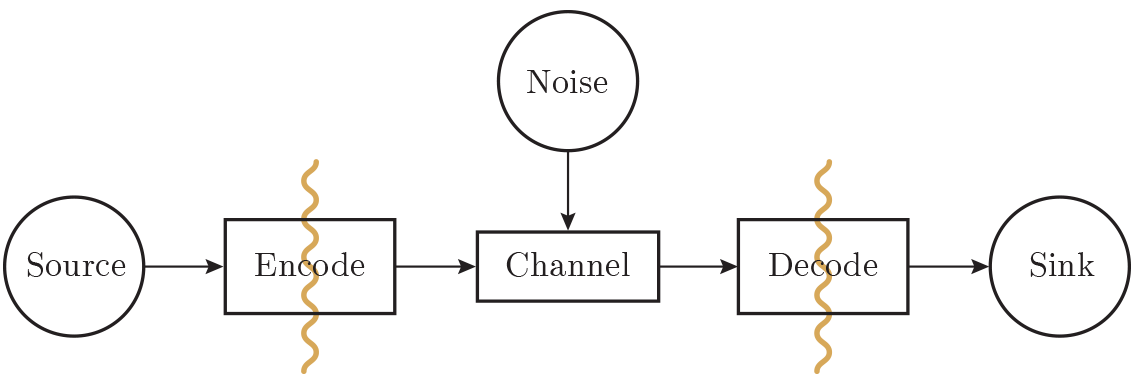
Figure 10.1—ระบบข้อมูล (Information system)
เริ่มจากทางซ้ายมือของ Figure 10.1 เรามีแหล่งข้อมูล (source of information) เราไม่ได้พูดถึงว่าแหล่งข้อมูลคืออะไร มันอาจเป็นสายอักขระตัวอักษร ตัวเลข สูตรคณิตศาสตร์ โน้ตดนตรี สัญลักษณ์ที่ใช้แทนการเคลื่อนไหวในการเต้นรำ—ไม่ว่าแหล่งที่มาจะเป็นอะไร และไม่ว่า "ความหมาย" ที่เกี่ยวข้องกับสัญลักษณ์จะเป็นอะไร ล้วนไม่เป็นส่วนหนึ่งของทฤษฎีนี้ เราตั้งสมมติฐานเพียงว่ามีแหล่งข้อมูลอยู่เท่านั้น และการทำเพียงแค่นี้ โดยไม่เพิ่มอะไรอีก เราก็มีทฤษฎีทั่วไปที่ทรงพลังและสามารถนำไปประยุกต์ใช้ได้อย่างกว้างขวาง การละทิ้งรายละเอียดต่างหากที่ทำให้เกิดการประยุกต์ใช้ที่หลากหลาย
ในช่วงปลายทศวรรษ 1940 Shannon ได้สร้าง information theory ขึ้นมา มีความเชื่อโดยทั่วไปว่าเขาควรเรียกมันว่า communication theory แต่เขายืนกรานที่จะใช้คำว่า "information" และนั่นคือคำที่กลายเป็นทั้งแหล่งที่มาของความสนใจและความผิดหวังในทฤษฎีนี้มาโดยตลอด ผู้คนต้องการมีทฤษฎีของ "ข้อมูล" แต่มันก็เป็นเพียงทฤษฎีของสายอักขระเท่านั้น ย้ำอีกครั้ง สิ่งที่เราสมมติคือมีแหล่งข้อมูลดังกล่าวอยู่ และเราจะเข้ารหัส (encode) มันเพื่อการส่งผ่าน
ตัวเข้ารหัส (encoder) ถูกแบ่งออกเป็นสองส่วน ส่วนแรกเรียกว่า source encoding ซึ่งตามชื่อก็บอกอยู่แล้วว่าปรับให้เข้ากับแหล่งข้อมูล โดยแหล่งข้อมูลต่างๆ อาจมีรูปแบบการเข้ารหัสที่แตกต่างกัน
ส่วนที่สองของกระบวนการเข้ารหัสเรียกว่า channel encoding และถูกปรับให้เข้ากับช่องสัญญาณ (channel) ที่จะใช้ส่งสัญลักษณ์ที่เข้ารหัส ดังนั้นส่วนที่สองของกระบวนการเข้ารหัสจึงถูกปรับให้เหมาะกับช่องสัญญาณ ด้วยวิธีนี้ ด้วยอินเทอร์เฟสร่วม เราสามารถมีแหล่งข้อมูลหลากหลายที่ถูกเข้ารหัสไปยังอินเทอร์เฟสร่วมก่อน จากนั้นข้อความก็ถูกเข้ารหัสเพิ่มเติมเพื่อปรับให้เข้ากับช่องสัญญาณเฉพาะที่กำลังใช้งานอยู่
ต่อไป ไปทางขวาของ Figure 10.1 ช่องสัญญาณถูกสมมติว่ามี "สัญญาณรบกวนแบบสุ่มเพิ่มเข้าไป" (random noise added) สัญญาณรบกวนทั้งหมดในระบบถูกรวมไว้ที่นี้ เราสมมติว่าตัวเข้ารหัสสามารถจดจำสัญลักษณ์ขาเข้าได้อย่างไม่ผิดพลาด และตัวถอดรหัสก็ทำงานได้อย่างไม่ผิดพลาดเช่นกัน สิ่งเหล่านี้เป็นอุดมคติ แต่ในทางปฏิบัติหลายกรณีก็ใกล้เคียงกับความเป็นจริง
ถัดมา การถอดรหัส (decoding) ทำเป็นสองขั้น คือจากช่องสัญญาณไปเป็นรหัสมาตรฐาน และจากรหัสมาตรฐานไปเป็นรหัสต้นทาง สุดท้ายก็ส่งต่อไปยังผู้รับ (sink) หรือปลายทาง อีกครั้ง เราไม่ได้ถามว่าผู้รับจะทำอะไรกับมัน
ดังที่กล่าวไว้ก่อนหน้านี้ ระบบนี้คล้ายกับการส่งผ่าน เช่น ข้อความโทรศัพท์จากฉันถึงคุณ วิทยุ หรือรายการ tv และสิ่งอื่นๆ เช่น ตัวเลขใน register ของคอมพิวเตอร์ที่ถูกส่งไปยังที่อื่น ย้ำอีกครั้ง การส่งผ่านพื้นที่นั้นเหมือนกับการส่งผ่านเวลา นั่นคือ การจัดเก็บ (storage) หากคุณมีข้อมูลและต้องการใช้มันในภายหลัง คุณก็เข้ารหัสเพื่อจัดเก็บและเก็บไว้ ต่อมาเมื่อคุณต้องการก็ถอดรหัสออกมา หนึ่งในระบบการเข้ารหัสคือการคงรูปเดิม (identity) ซึ่งไม่มีการเปลี่ยนแปลงในการแทนข้อมูล
ความแตกต่างพื้นฐานระหว่างทฤษฎีประเภทนี้กับทฤษฎีปกติในฟิสิกส์คือการสมมติ ตั้งแต่เริ่มต้น ว่ามี "สัญญาณรบกวน" เพราะความผิดพลาดจะเกิดขึ้นได้ในอุปกรณ์ทุกชนิด แม้แต่ในกลศาสตร์ควอนตัม สัญญาณรบกวนก็ปรากฏในขั้นหลังเป็น หลักความไม่แน่นอน (uncertainty principle) ไม่ใช่เป็นสมมติฐานเริ่มต้น และไม่ว่าในกรณีใด "สัญญาณรบกวน" ในทฤษฎีสารสนเทศก็ไม่เหมือนกับความไม่แน่นอนใน qm เลย
เพื่อความสะดวก เราจะสมมติว่าใช้รูปแบบไบนารี (binary form) ในการแทนข้อมูลในระบบ รูปแบบอื่นก็สามารถจัดการได้เช่นเดียวกัน แต่ความทั่วไปนั้นไม่คุ้มกับสัญกรณ์ที่เพิ่มขึ้นมา
เราเริ่มต้นด้วยการสมมติว่าสัญลักษณ์รหัสที่เราใช้มี ความยาวแปรผัน (variable length) คล้ายกับ รหัสมอร์ส (Morse code) แบบดั้งเดิมที่มีจุดและขีด โดยตัวอักษรที่พบบ่อยจะสั้นและตัวที่หายากจะยาว ซึ่งทำให้รหัสมีประสิทธิภาพ แต่ควรสังเกตว่ารหัสมอร์สเป็นรหัสแบบ ternary ไม่ใช่ binary เพราะมีการเว้นวรรคร่วมกับจุดและขีด หากสัญลักษณ์รหัสทั้งหมดมีความยาวเท่ากัน เราจะเรียกมันว่า block code .
คุณสมบัติแรกที่เราต้องการอย่างชัดเจนคือความสามารถในการถอดรหัสข้อความได้โดยไม่ซ้ำกัน (uniquely decode) หากไม่มีสัญญาณรบกวนเพิ่ม—อย่างน้อยก็ดูเหมือนเป็นคุณสมบัติที่พึงประสงค์ แม้ว่าในบางสถานการณ์อาจละเลยไปได้บ้างในระดับหนึ่ง สิ่งที่ส่งออกไปคือกระแสของสัญลักษณ์ซึ่งผู้รับมองเห็นเป็นสายของ 0 และ 1 เราเรียกสัญลักษณ์สองตัวติดกันว่า second extension สามตัวว่า third extension และโดยทั่วไปถ้าเราส่ง n สัญลักษณ์ ผู้รับจะเห็น n th extension ของสัญลักษณ์รหัสพื้นฐาน เมื่อไม่ทราบ n คุณในฐานะผู้รับต้องแบ่งกระแสข้อมูลออกเป็นหน่วยที่สามารถแปลได้ และคุณต้องการ อย่างที่เรากล่าวไว้ข้างต้น ให้สามารถที่ฝั่งรับ ซึ่งหมายถึงคุณอีกนั่นแหละ ทำการแยกกระแสข้อมูลนี้ได้อย่างไม่ซ้ำกัน เพื่อที่จะกู้คืนข้อความ originál ที่ฉันซึ่งอยู่ฝั่งส่งได้ส่งให้คุณ
ผมจะใช้ตัวอักษรชุดเล็กๆ ของสัญลักษณ์ที่จะเข้ารหัสในการยกตัวอย่าง โดยปกติแล้วตัวอักษรชุดจะมีขนาดใหญ่กว่ามาก โดยทั่วไปตัวอักษรภาษาธรรมชาติจะมีขนาดตั้งแต่ 16 ถึง 36 ตัวอักษร ทั้งตัวพิมพ์ใหญ่และตัวพิมพ์เล็ก รวมถึงตัวเลขและสัญลักษณ์วรรคตอนมากมาย ตัวอย่างเช่น ascii มี 128 = 2 7 สัญลักษณ์ในชุดตัวอักษรของมัน
มาดูรหัสพิเศษหนึ่งตัวของสัญลักษณ์สี่ตัว s 1 , s 2 , s 3 , s 4 :
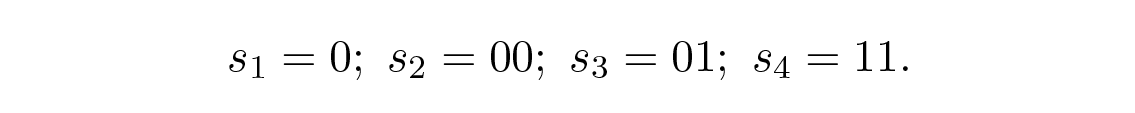
หากคุณได้รับ
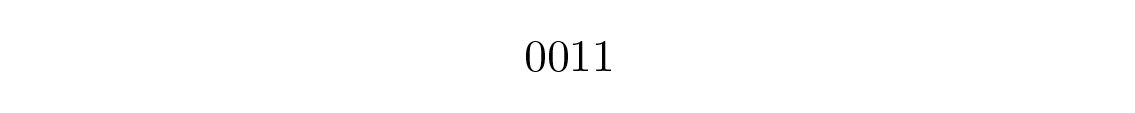
คุณจะทำอย่างไร? มันคือ s 1 s 1 s 4 หรือว่า s 2 s 4 ? คุณไม่สามารถบอกได้; รหัสนี้ไม่สามารถ ถอดรหัสได้อย่างไม่ซ้ำกัน (uniquely decodable) ดังนั้นจึงไม่น่าพอใจ
ในทางกลับกัน รหัส
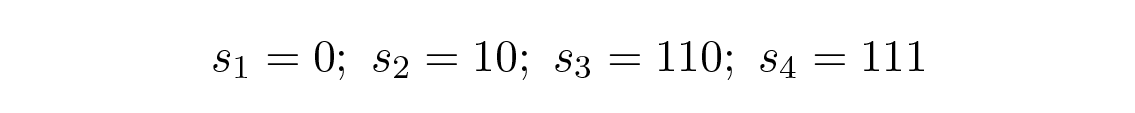
สามารถถอดรหัสได้อย่างไม่ซ้ำกัน ลองใช้สายอักขระสุ่มมาสักสายแล้วดูว่าคุณจะถอดรหัสมันอย่างไร คุณจะสร้าง ต้นไม้ถอดรหัส (decoding tree) ในรูปแบบที่แสดงใน Figure 10.2 . สายอักขระ
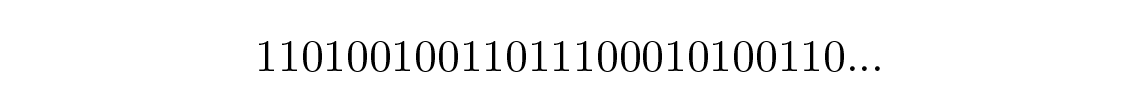
สามารถแยกออกเป็นสัญลักษณ์
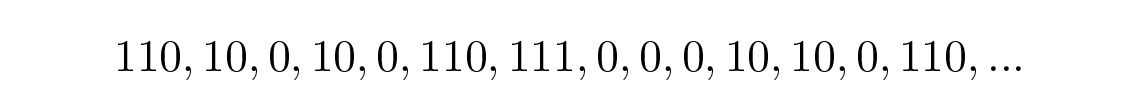
โดยเพียงทำตามต้นไม้ถอดรหัสโดยใช้กฎ:
ทุกครั้งที่คุณมาถึงจุดแยก (node) คุณจะอ่านสัญลักษณ์ถัดไป และเมื่อคุณมาถึงใบ (leaf) ของต้นไม้ คุณจะปล่อยสัญลักษณ์ที่เกี่ยวข้องออกมาและกลับไปยังจุดเริ่มต้น
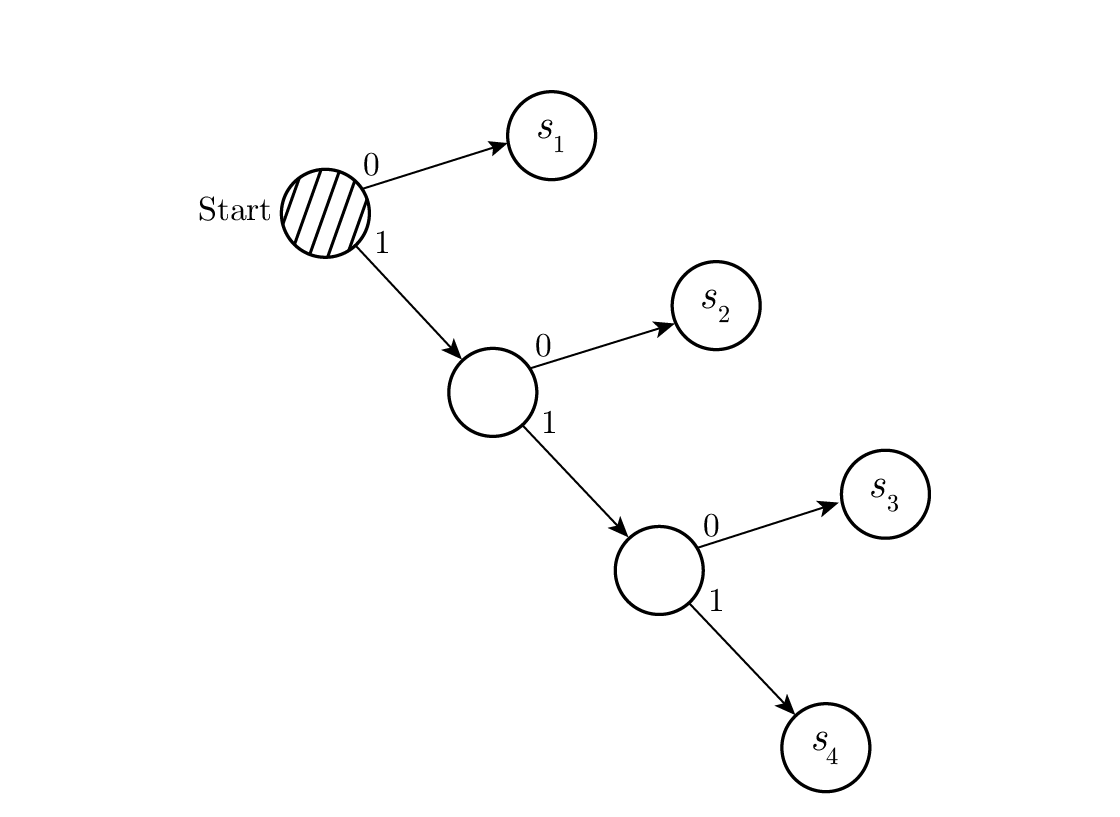
Figure 10.2—ต้นไม้ถอดรหัส (Decoding tree)
เหตุผลที่ต้นไม้นี้มีอยู่ได้ก็คือไม่มีสัญลักษณ์ใดเป็น prefix ของสัญลักษณ์อื่น ดังนั้นคุณจะรู้เสมอเมื่อคุณมาถึงจุดสิ้นสุดของสัญลักษณ์ปัจจุบัน
มีหลายสิ่งที่ควรสังเกต ประการแรก การถอดรหัสเป็นกระบวนการที่ตรงไปตรงมาซึ่งแต่ละ digit ถูกตรวจสอบเพียงครั้งเดียว ประการที่สอง ในทางปฏิบัติคุณมักจะรวมสัญลักษณ์ที่เป็น exit ออกจากกระบวนการถอดรหัส ซึ่งจำเป็นเมื่อจบข้อความ การไม่เตรียม escape symbol ไว้เป็น ข้อผิดพลาดที่พบบ่อยในการออกแบบรหัส แน่นอนว่าคุณอาจไม่เคยต้องออกจากโหมดถอดรหัสเลย ซึ่งในกรณีนั้นก็ไม่จำเป็นต้องใช้ escape symbol
หัวข้อถัดไปคือ instantaneously decodable codes (รหัสที่ถอดรหัสได้ทันที) เพื่อให้เข้าใจแนวคิดนี้ ลองพิจารณารหัสข้างต้นโดยกลับ digits จากท้ายมาหน้า
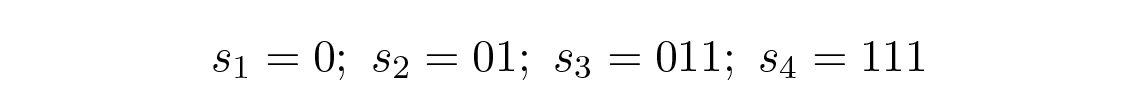
ทีนี้ลองพิจารณาการรับ 011111…111 วิธีเดียวที่คุณจะถอดรหัสนี้ได้คือเริ่มจากจุดสิ้นสุด แล้วจัดกลุ่มทีละสามจนกว่าคุณจะเห็นว่าเหลือ 1 กี่ตัวที่จะไปคู่กับ 0 ตัวแรก มีเพียงเท่านั้นคุณถึงจะถอดรหัสสัญลักษณ์แรกได้ ใช่ มันสามารถ ถอดรหัสได้อย่างไม่ซ้ำกัน แต่ไม่ใช่ทันที! คุณต้องรอจนกว่าจะถึงจุดสิ้นสุดของข้อความก่อนที่จะเริ่มกระบวนการถอดรหัสได้! ซึ่งจะพบว่า ( ทฤษฎีบทของ McMillan) การถอดรหัสได้ทันทีนั้นไม่มีต้นทุนเพิ่มในทางปฏิบัติ ดังนั้นเราจะยึดติดกับรหัสที่ถอดรหัสได้ทันทีและไม่ซ้ำกัน (instantaneously uniquely decodable codes)
ต่อไปเราจะมาดูตัวอย่างการเข้ารหัสสัญลักษณ์เดียวกันคือ s i . การเข้ารหัสแบบแรกคือ
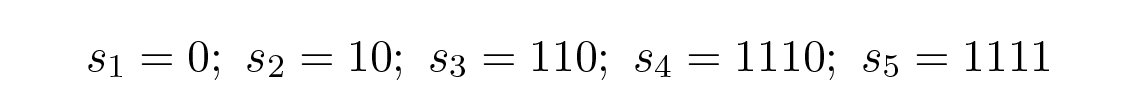
ซึ่งจะมีต้นไม้ถอดรหัสดังแสดงใน Figure 10.3 .
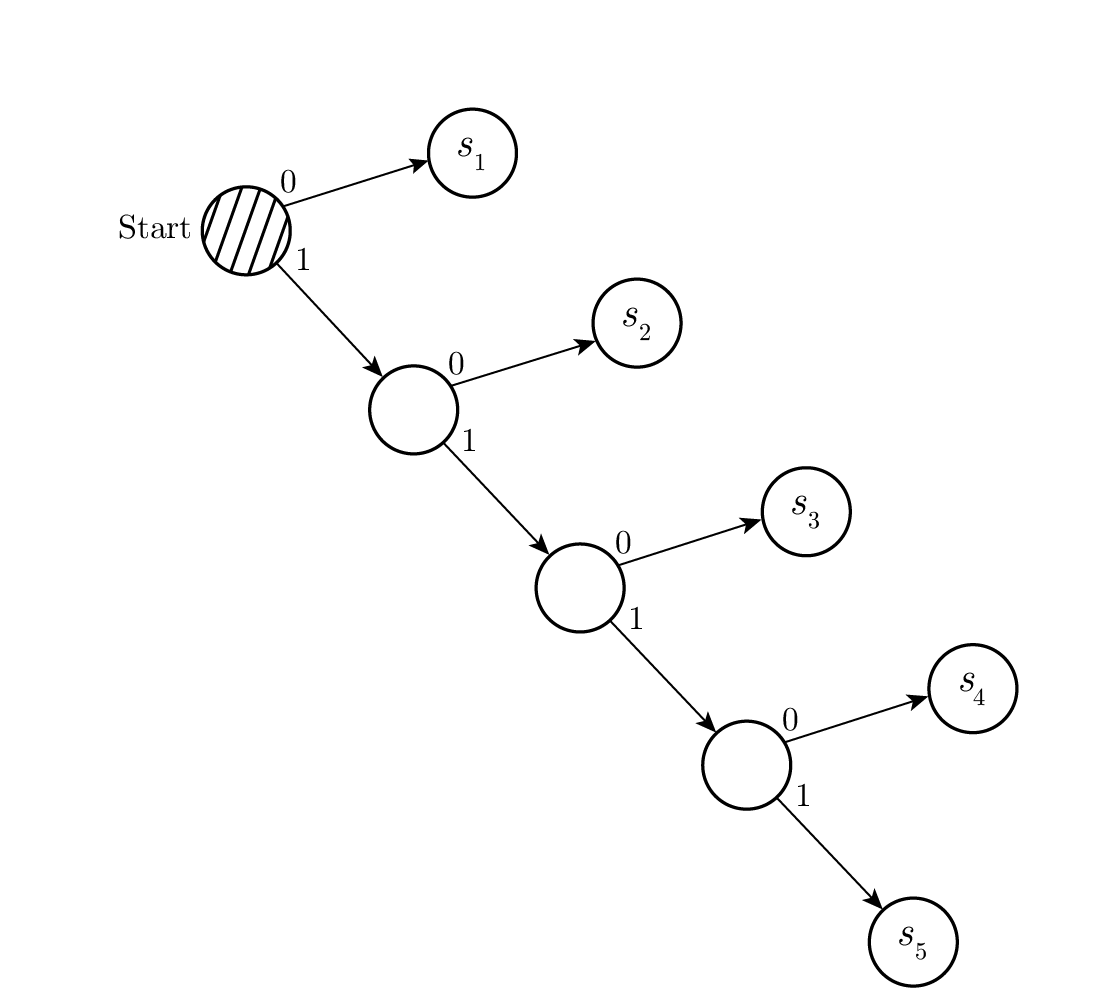
Figure 10.3—ต้นไม้ถอดรหัสแรกสำหรับ s 1 ถึง s 5 (First decoding tree for s₁ through s₅)
การเข้ารหัสแบบที่สองเป็นแหล่งข้อมูลเดียวกัน แต่เรามี
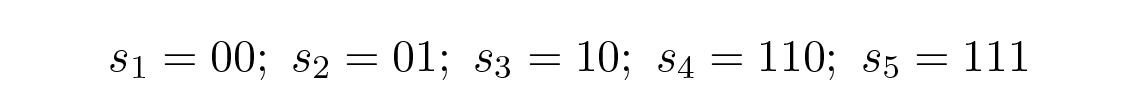
โดยมีต้นไม้ดังแสดงใน Figure 10.4 .
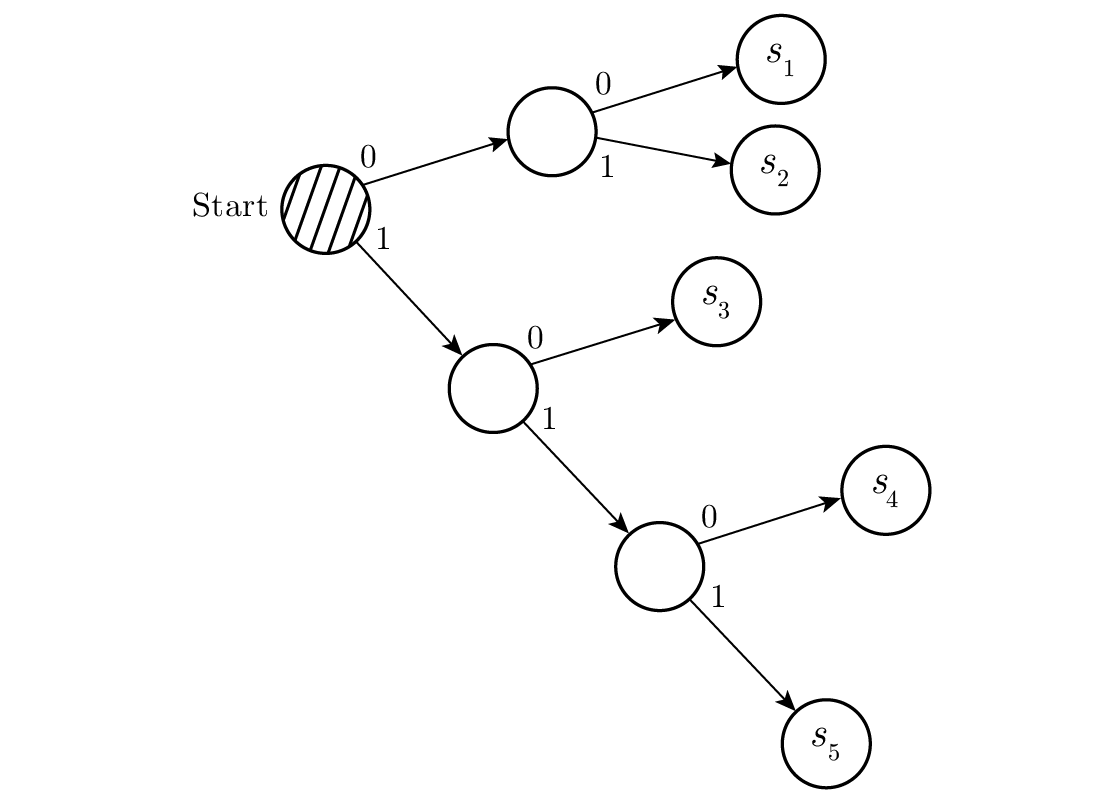
Figure 10.4—ต้นไม้ถอดรหัสที่สองสำหรับ s 1 ถึง s 5 (Second decoding tree for s₁ through s₅)
การวัด "ความดี" ของรหัสที่เห็นได้ชัดที่สุดคือความยาวเฉลี่ย (average length) สำหรับชุดของข้อความบางชุด สำหรับสิ่งนี้เราต้องคำนวณความยาวรหัส l i ของแต่ละสัญลักษณ์คูณด้วยความน่าจะเป็น p i ที่มันจะเกิดขึ้น แล้วนำผลคูณเหล่านี้มารวมกันทั่วทั้งรหัส ดังนั้นสูตรสำหรับความยาวรหัสเฉลี่ย L สำหรับตัวอักษรชุดที่มี q สัญลักษณ์ คือ
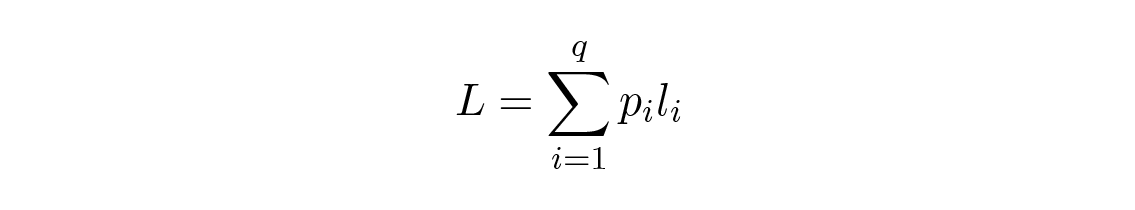
โดยที่ p i คือความน่าจะเป็นของสัญลักษณ์ s i และ l i คือความยาวที่สอดคล้องกันของสัญลักษณ์ที่เข้ารหัส สำหรับรหัสที่มีประสิทธิภาพ ค่า L นี้ควรมีค่าน้อยที่สุดเท่าที่จะเป็นไปได้ ถ้า p 1 \= 1/2 , p 2 \= 1/4 , p 3 \= 1/8 , p 4 \= 1/16 และ p 5 \= 1/16 ดังนั้นสำหรับรหัส #1 เราจะได้
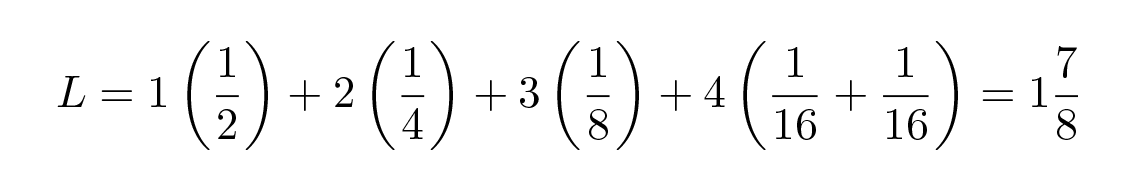
และสำหรับรหัส #2
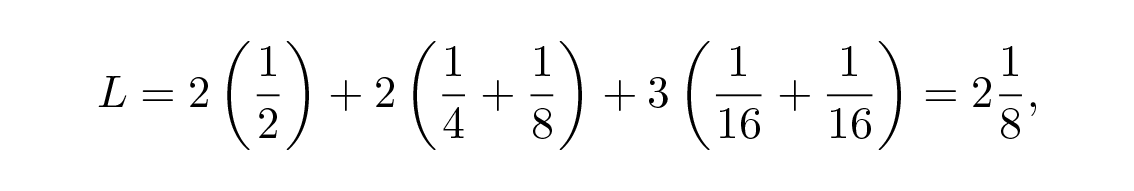
และด้วยความน่าจะเป็นที่กำหนดนี้จะทำให้รหัสแรกดีกว่า
หาก codeword ส่วนใหญ่มีความน่าจะเป็นในการเกิดขึ้นเท่าๆ กัน การเข้ารหัสแบบที่สองจะมีความยาวรหัสเฉลี่ยน้อยกว่าแบบแรก ให้ p i \= 1/5 สำหรับทุก i . แล้วรหัส #1 จะมี
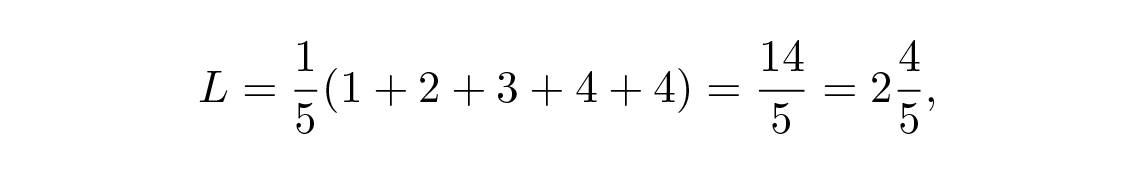
ในขณะที่รหัส #2 จะมี
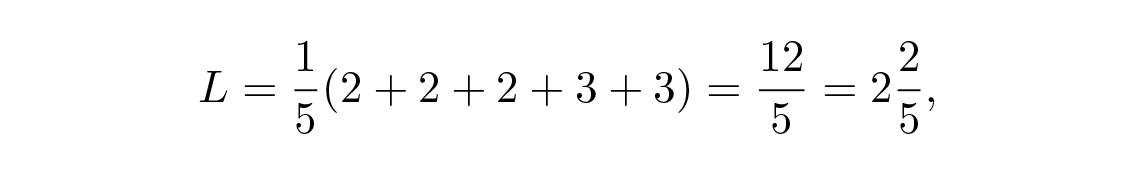
จึงทำให้รหัสที่สองดีกว่า เห็นได้ชัดว่าการออกแบบรหัสที่ "ดี" จะต้องขึ้นอยู่กับความถี่ของสัญลักษณ์ที่เกิดขึ้น
ต่อไปเราจะพูดถึง Kraft inequality (อสมการของ Kraft) ซึ่งให้ขีดจำกัดของความยาว l i ของสัญลักษณ์รหัส ในฐาน 2 อสมการของ Kraft คือ
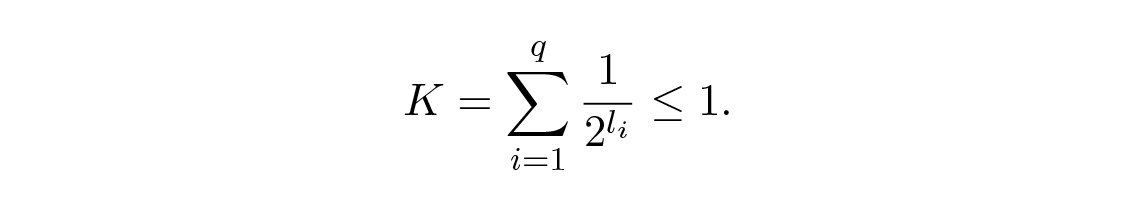
เมื่อพิจารณาอย่างละเอียด อสมการนี้บอกว่าไม่สามารถมีสัญลักษณ์ที่สั้นมากเกินไปได้ เพราะไม่อย่างนั้นผลรวมจะมีค่ามากเกินไป
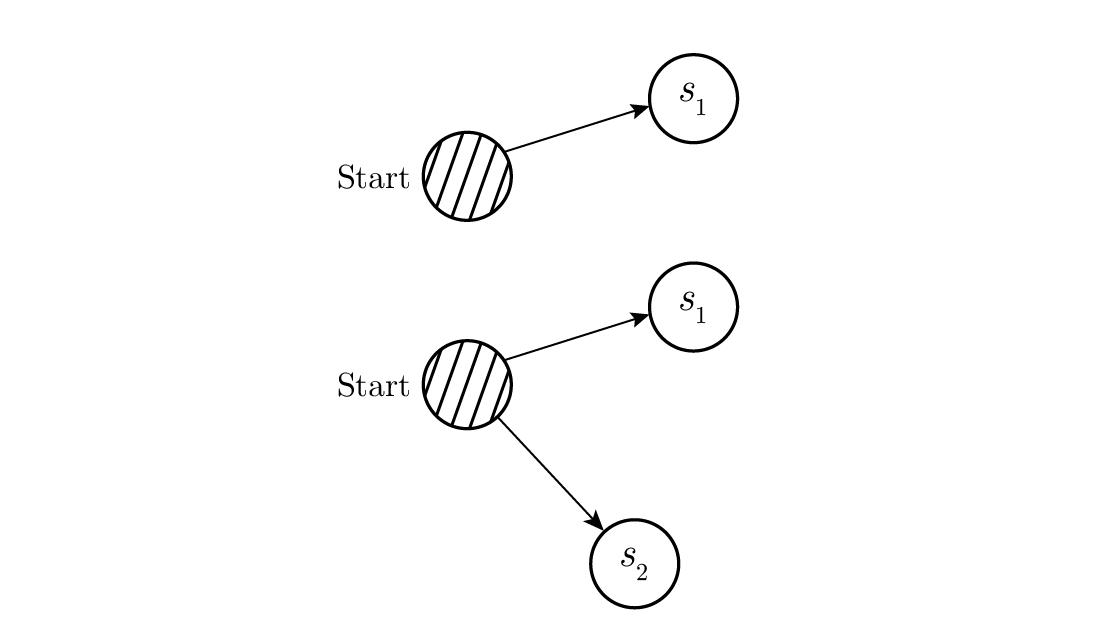
Figure 10.5—กรณีเล็กน้อยสำหรับอสมการของ Kraft (The trivial cases for Kraft inequality)
เพื่อพิสูจน์อสมการของ Kraft สำหรับรหัสที่ถอดรหัสได้ทันทีและไม่ซ้ำกัน เราก็แค่วาดต้นไม้ถอดรหัส ซึ่งแน่นอนว่ามีอยู่จริง แล้วใช้การอุปนัยทางคณิตศาสตร์ (mathematical induction) ถ้าต้นไม้มีใบหนึ่งหรือสองใบ ดังที่แสดงใน Figure 10.5 ก็ไม่มีข้อกังขาว่าอสมการเป็นจริง ถัดมา ถ้ามีมากกว่าสองใบ เราจะแยกต้นไม้ที่มีความยาว m (สำหรับขั้นอุปนัย) ออกเป็นสองต้น และโดยสมมติฐานการอุปนัย อสมการจะใช้ได้กับแต่ละกิ่งที่มีความยาว m – 1 หรือน้อยกว่า โดยการอุปนัย อสมการจะใช้ได้กับแต่ละกิ่ง โดยให้ K' และ K" สำหรับผลรวมของมัน ทีนี้เมื่อเรารวมสองต้นเข้าด้วยกัน แต่ละความยาวจะเพิ่มขึ้น 1 ดังนั้นแต่ละพจน์ในผลรวมจะได้ตัวส่วนเพิ่มอีก factor 2 และเราจะได้
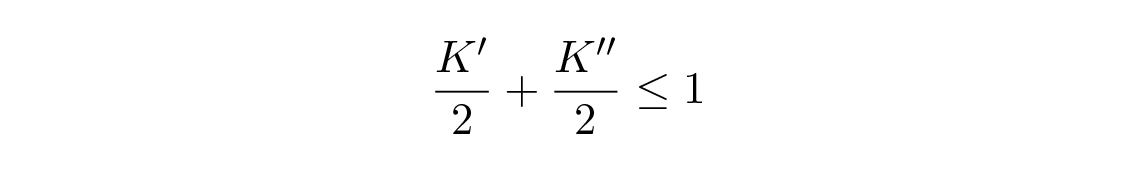
และทฤษฎีบทก็ได้รับการพิสูจน์
อสมการของ Kraft ใช้ได้กับรหัสที่ไม่ถอดรหัสได้ทันที (non-instantaneous) ด้วย ตราบใดที่มันสามารถถอดรหัสได้อย่างไม่ซ้ำกัน
ต่อไปเราจะพิจารณาการพิสูจน์ ทฤษฎีบทของ McMillan (McMillan's theorem) การพิสูจน์ขึ้นอยู่กับข้อเท็จจริงที่ว่าสำหรับจำนวนใดๆ K > 1 ยกกำลัง n บางค่าย่อมมีค่ามากกว่าฟังก์ชันเชิงเส้นใดๆ ของ n เมื่อ n มีขนาดใหญ่พอ เราเริ่มด้วยอสมการของ Kraft ยกกำลัง n (ซึ่งให้ n th extension) แล้วขยายผลรวม
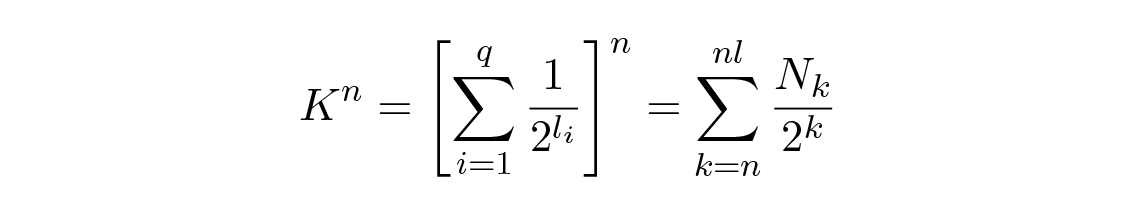
โดยที่ N k คือจำนวนสัญลักษณ์ที่มีความยาว k และผลรวมเริ่มจากความยาวต่ำสุดของ n th extension ของสัญลักษณ์ ซึ่งคือ n และสิ้นสุดที่ความยาวสูงสุด nl โดยที่ l คือความยาวสูงสุดของสัญลักษณ์รหัสใดๆ แต่จากการถอดรหัสได้อย่างไม่ซ้ำกัน จะต้องได้ว่า N k ≤ 2 k . ผลรวมกลายเป็น
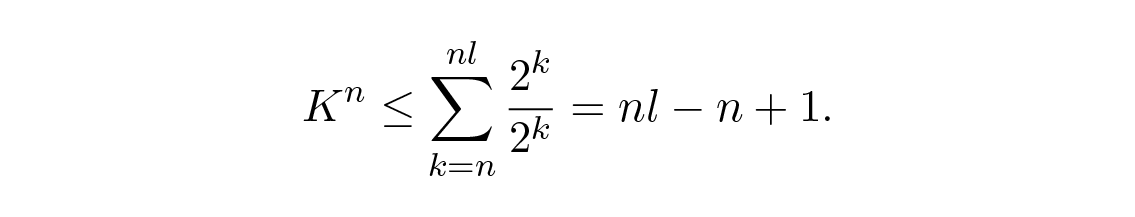
ถ้า K มีค่า มากกว่า 1 เราก็จะสามารถหา n ที่มากพอจนทำให้อสมการเป็นเท็จ ดังนั้นเราจะเห็นว่า K ≤ 1 และทฤษฎีบทของ McMillan ก็ได้รับการพิสูจน์
เนื่องจากตอนนี้เราเห็นแล้ว อย่างที่เราบอกไว้ว่าจะแสดงให้เห็น ว่าการถอดรหัสได้ทันทีนั้นไม่มีต้นทุนเพิ่ม เราจะยึดติดกับรหัสประเภทนี้และไม่สนใจรหัสที่ถอดรหัสได้อย่างไม่ซ้ำกันเพียงอย่างเดียว—ความทั่วไปของมันไม่ได้ให้ประโยชน์อะไรแก่เรา
ลองยกตัวอย่างสองสามตัวอย่างเพื่อแสดงอสมการของ Kraft จะมีรหัสที่ถอดรหัสได้อย่างไม่ซ้ำกันที่มีความยาว 1, 3, 3, 3 ได้หรือไม่? ได้ เพราะ
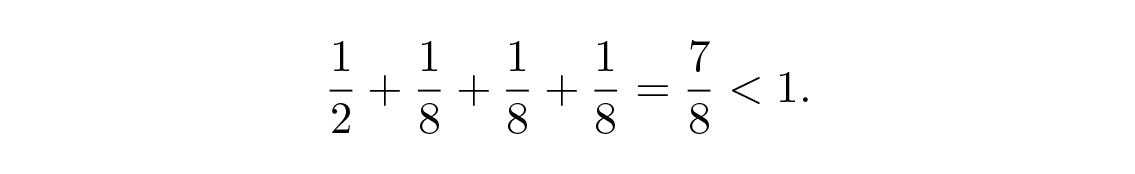
แล้วความยาว 1, 2, 2, 3 ล่ะ? เรามี
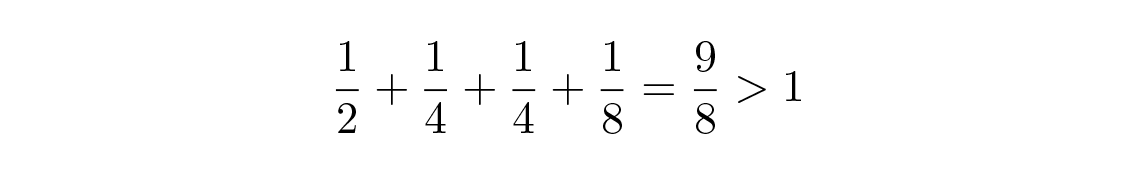
ดังนั้นไม่ได้! มีความยาวสั้นมากเกินไป
Comma codes คือรหัสที่สัญลักษณ์แต่ละตัวเป็นสายของ 1 ตามด้วย 0 ยกเว้นสัญลักษณ์สุดท้ายที่เป็น 1 ทั้งหมด ในกรณีพิเศษเรามี
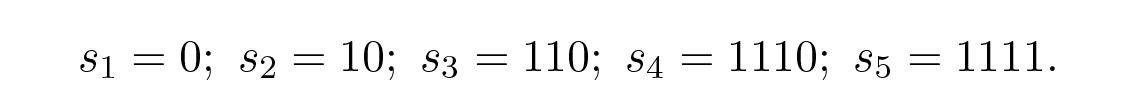
เรามีผลรวม Kraft
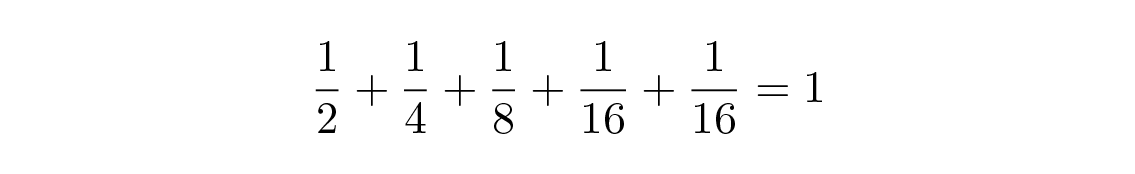
และเราก็ตรงตามเงื่อนไขพอดี จะเห็นได้ง่ายว่า comma code ทั่วไปก็เป็นไปตามอสมการของ Kraft อย่างเท่ากันพอดี
ถ้าผลรวม Kraft น้อยกว่า 1 แสดงว่ามีความสามารถในการส่งสัญญาณเกิน (excess signaling capacity) เพราะสามารถเพิ่มสัญลักษณ์อื่นได้ หรือทำให้สัญลักษณ์ที่มีอยู่สั้นลง ทำให้ความยาวรหัสเฉลี่ยลดลง
สังเกตว่าถ้าอสมการของ Kraft เป็นไปตามนั้น ไม่ได้หมายความว่ารหัสจะถอดรหัสได้อย่างไม่ซ้ำกัน เพียงแต่แสดงว่ามีรหัสที่มีความยาวสัญลักษณ์เหล่านั้นซึ่งถอดรหัสได้อย่างไม่ซ้ำกัน ถ้าคุณกำหนดเลขไบนารีตามลำดับตัวเลข แต่ละตัวมีความยาว l i ในหน่วยบิตที่ถูกต้อง คุณจะพบรหัสที่ถอดรหัสได้อย่างไม่ซ้ำกัน ตัวอย่างเช่น กำหนดความยาว 2, 2, 3, 3, 4, 4, 4, 4 เรามีสำหรับอสมการของ Kraft
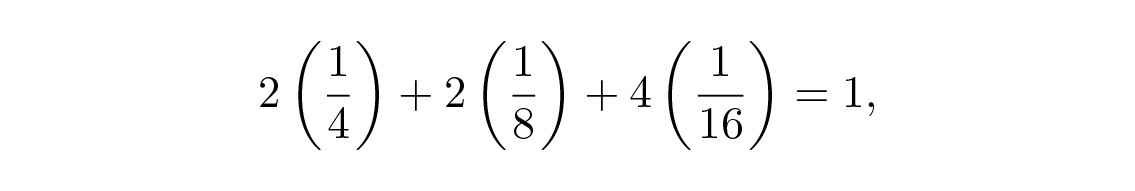
ดังนั้นรหัสที่ถอดรหัสได้ทันทีจึงมีอยู่จริง เราเลือกสัญลักษณ์ตามลำดับขนาดตัวเลขที่เพิ่มขึ้น โดยให้จุดไบนารีอยู่ทางซ้าย ดังนี้ และสังเกตความยาว l i ที่สอดคล้องกันอย่างระมัดระวัง:
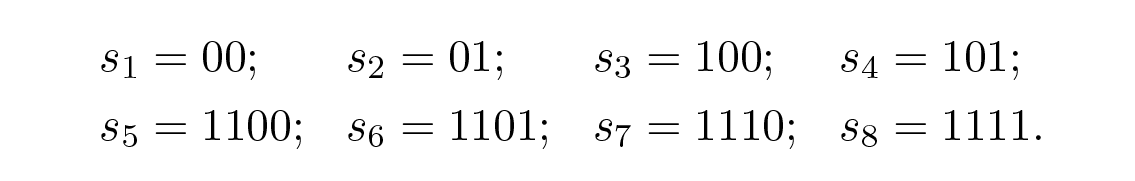
ผมรู้สึกว่าจำเป็นต้องชี้ให้เห็นว่าสิ่งต่างๆ เกิดขึ้นจริงอย่างไรเมื่อเราสื่อสารความคิด ดังนั้น ณ จุดนี้ ผมต้องการส่งความคิดจากหัวของผมไปยังหัวของคุณ ผมเปล่งคำบางคำออกมา ซึ่งคุณควรจะได้รับความคิดนั้น แต่ถ้าคุณพยายามส่งความคิดนี้ต่อให้เพื่อน คุณก็จะเปล่งคำที่แตกต่างออกไปเกือบแน่นอน ในความหมายที่แท้จริง "ความหมาย" ไม่ได้อยู่ในคำเฉพาะที่ผมใช้ เพราะคุณอาจใช้คำต่างกันเพื่อสื่อสารความคิดเดียวกัน เห็นได้ชัดว่าคำที่แตกต่างกันสามารถสื่อ "ข้อมูล" เดียวกันได้ แต่ถ้าคุณบอกว่าคุณไม่เข้าใจข้อความ โดยปกติแล้วชุดคำที่แตกต่างกันจะถูกใช้โดยผู้ส่งในการนำเสนอความคิดครั้งที่สองหรือสาม ดังนั้นอีกครั้ง ในบางแง่มุม "ความหมาย" ไม่ได้อยู่ในคำที่ผมใช้จริง แต่คุณเติมข้อมูลแวดล้อมจำนวนมากเมื่อคุณแปลจากคำพูดของผมไปเป็นความเข้าใจในสิ่งที่ผมพูดภายในหัวของคุณ
เราได้เรียนรู้ที่จะ "ปรับ" คำที่เราใช้ให้เหมาะกับผู้รับ เราคัดเลือกในระดับหนึ่งตามสิ่งที่เราคิดว่าเป็นสัญญาณรบกวนของช่องสัญญาณ ถึงแม้ว่าสิ่งนี้จะไม่ตรงกับโมเดลที่ผมใช้ข้างต้น เนื่องจากมีสัญญาณรบกวนอย่างมีนัยสำคัญในกระบวนการถอดรหัส จะว่ากันตามนั้น ความสามารถที่ผู้รับจะไม่ได้ "ยินในสิ่งที่พูด" โดยบุคคลในตำแหน่งผู้บริหารระดับสูง แต่กลับได้ยินเพียงสิ่งที่พวกเขาคาดหวังจะได้ยินนั้น เป็นปัญหาสำคัญในทุกองค์กรขนาดใหญ่ และเป็นสิ่งที่คุณควรตระหนักอย่างยิ่งเมื่อคุณก้าวขึ้นสู่ตำแหน่งสูงในองค์กร ดังนั้น การแทนข้อมูลในทฤษฎีทางการที่เราได้ให้นั้น สะท้อนให้เห็นเพียงบางส่วนในชีวิตจริง แต่ก็แสดงให้เห็นถึงความเกี่ยวข้องในระดับที่พอสมควรนอกเหนือขอบเขตทางการของการใช้คอมพิวเตอร์ ซึ่งมันสามารถนำไปประยุกต์ใช้ได้อย่างสูง