Information theory ถูกสร้างขึ้นโดย C.E. Shannon ในช่วงปลายทศวรรษ 1940s ผู้บริหารของ Bell Telephone Labs อยากให้เขาเรียกมันว่า "communication theory" เพราะชื่อนั้นถูกต้องตรงตัวมากกว่า แต่ด้วยเหตุผลด้านการประชาสัมพันธ์ "information theory" กลับมีแรงดึงดูดมากกว่า—แชนนอนเลือกชื่อนี้และมันก็เป็นที่รู้จักมาจนถึงทุกวันนี้ ชื่อนี้สื่อว่าทฤษฎีนี้เกี่ยวข้องกับสารสนเทศ—ดังนั้นมันจึงต้องสำคัญ เนื่องจากเรากำลังก้าวเข้าสู่ยุคสารสนเทศมากขึ้นเรื่อยๆ ผมจึงจะอธิบายผลลัพษ์หลักๆ สองสามอย่าง ไม่ใช่ด้วยการพิสูจน์อย่างเข้มงวดในรูปแบบทั่วไป แต่ใช้การพิสูจน์โดยสัญชาตญาณในกรณีพิเศษ เพื่อให้คุณเข้าใจว่าทฤษฎีสารสนเทศคืออะไร และมันทำอะไรได้และไม่ได้บ้าง
ก่อนอื่น "สารสนเทศ" คืออะไร? แชนนอนให้นิยามสารสนเทศว่าคือ ความประหลาดใจ (surprise) เขาเลือกค่าลบของ log ของความน่าจะเป็นของเหตุการณ์เป็นปริมาณสารสนเทศที่คุณได้รับเมื่อเหตุการณ์ที่มีความน่าจะเป็น p เกิดขึ้น ตัวอย่างเช่น ถ้าผมบอกว่ามีหมอกควันในลอสแอนเจลิส p ก็จะใกล้ 1 ซึ่งไม่ค่อยมีสารสนเทศเท่าไหร่ แต่ถ้าผมบอกว่าฝนตกในมอนเทอเรย์ในเดือนมิถุนายน นั่นเป็นเรื่องที่น่าประหลาดใจและมีสารสนเทศมากกว่า เพราะ log 1 = 0 เหตุการณ์ที่แน่นอนจึงไม่มีสารสนเทศเลย
โดยละเอียดแล้ว แชนนอนเชื่อว่าการวัดปริมาณสารสนเทศควรเป็นฟังก์ชันต่อเนื่องของความน่าจะเป็น p ของเหตุการณ์ และสำหรับเหตุการณ์ที่เป็นอิสระต่อกัน มันควรจะบวกกันได้—สิ่งที่คุณเรียนรู้จากแต่ละ เหตุการณ์อิสระ เมื่อนำมารวมกันควรเท่ากับปริมาณที่คุณเรียนรู้จากเหตุการณ์รวม ตัวอย่างเช่น ผลลัพธ์ของการทอยลูกเต๋าและการโยนเหรียญโดยทั่วไปถือว่าเป็นเหตุการณ์อิสระต่อกัน ในสัญลักษณ์ทางคณิตศาสตร์ ถ้า I ( p ) คือปริมาณสารสนเทศที่คุณมีสำหรับเหตุการณ์ที่มีความน่าจะเป็น p แล้วสำหรับเหตุการณ์ x ที่มีความน่าจะเป็น p 1 และเหตุการณ์อิสระ y ที่มีความน่าจะเป็น p 2 คุณจะได้ว่าสำหรับเหตุการณ์ที่ทั้ง x และ y เกิดขึ้น
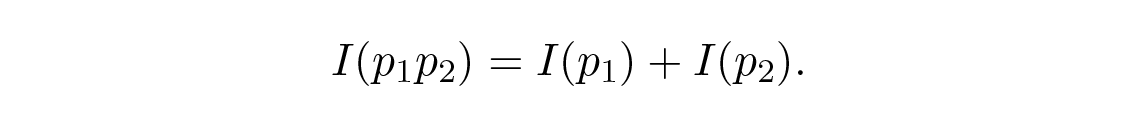
นี่คือ สมการเชิงฟังก์ชัน (functional equation) ซึ่งเป็นจริงสำหรับทุก p 1 และ p 2
เพื่อแก้สมการเชิงฟังก์ชันนี้ สมมติให้
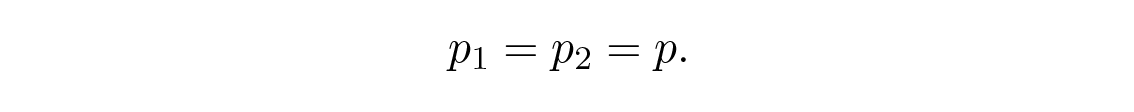
ซึ่งจะได้
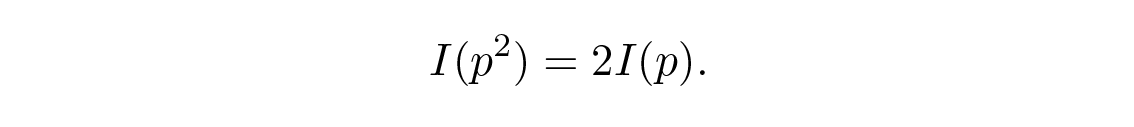
ถ้า p 1 \= p 2 และ p 2 \= p แล้ว
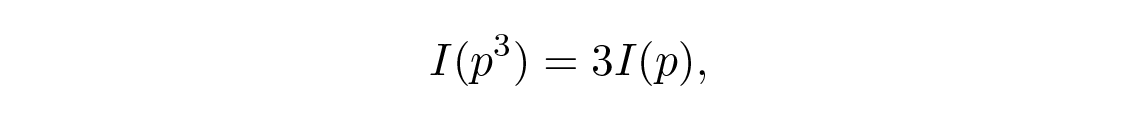
ฯลฯ การขยายกระบวนการนี้ คุณสามารถแสดงได้ โดยใช้วิธีมาตรฐานสำหรับเลขยกกำลัง สำหรับจำนวนตรรกยะ m/n ทุกจำนวนว่า
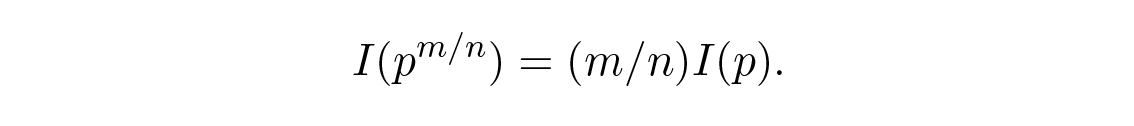
จากสมมติฐานเรื่องความต่อเนื่องของการวัดสารสนเทศ จะได้ว่า log เป็นคำตอบแบบต่อเนื่องเพียงหนึ่งเดียวของสมการเชิงฟังก์ชันจากตอนต้น
ในทฤษฎีสารสนเทศ เป็นธรรมเนียมที่จะใช้ฐานของระบบ log เป็น 2 ดังนั้นทางเลือกแบบ binary จะเท่ากับหนึ่ง bit ของสารสนเทศพอดี ดังนั้นสารสนเทศจึงถูกวัดโดยสูตร
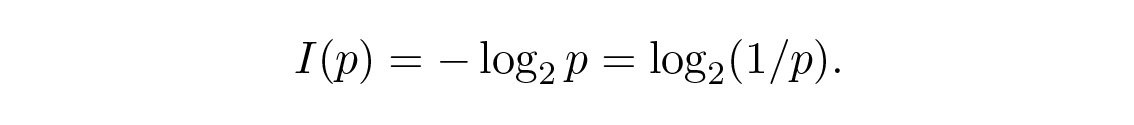
ขอให้เราหยุดพิจารณาสิ่งที่เกิดขึ้นจนถึงตอนนี้ ประการแรก เรายังไม่ได้ให้นิยาม "สารสนเทศ" เราแค่ให้สูตรสำหรับวัดปริมาณของมัน ประการที่สอง การวัดขึ้นอยู่กับ ความประหลาดใจ และถึงแม้มันจะสอดคล้องในระดับที่สมเหตุสมผลกับสถานการณ์ของเครื่องจักร เช่น ระบบโทรศัพท์ วิทยุ โทรทัศน์ คอมพิวเตอร์ และอื่นๆ แต่มันก็ ไม่ ได้แทนทัศนคติปกติของมนุษย์ที่มีต่อสารสนเทศเลย ประการที่สาม มันเป็นการวัดเชิงสัมพัทธ์เพราะขึ้นอยู่กับสถานะความรู้ของคุณ ถ้าคุณกำลังดูกระแสของ "ตัวเลขสุ่ม" จากแหล่งกำเนิดแบบสุ่ม คุณก็จะคิดว่าแต่ละตัวเลขมาอย่างน่าประหลาดใจ แต่ถ้าคุณรู้สูตรสำหรับคำนวณ "ตัวเลขสุ่ม" เหล่านั้น ตัวเลขถัดไปก็จะไม่มีความประหลาดใจเลย จึงไม่มีสารสนเทศ! ดังนั้น แม้ว่านิยาม ที่แชนนอนตั้งไว้สำหรับสารสนเทศจะเหมาะสมในหลายๆ ด้านสำหรับเครื่องจักร แต่มันก็ดูไม่เข้ากับการใช้งานของมนุษย์สำหรับคำนี้ นี่คือเหตุผลว่าทำไมมันควรจะถูกเรียกว่า "communication theory" ไม่ใช่ "information theory" มันสายเกินไปที่จะเปลี่ยนนิยามนี้ (ซึ่งสร้างความนิยมในช่วงแรกและยังคงทำให้คนคิดว่ามันจัดการกับ "สารสนเทศ") ดังนั้นเราจึงต้องยอมรับมัน แต่คุณควรตระหนักให้ชัดเจนว่ามันบิดเบือนมุมมองทั่วไปเกี่ยวกับสารสนเทศมากแค่ไหน และมันจัดการกับสิ่งอื่นซึ่งแชนนอนถือว่าเป็นความประหลาดใจ
นี่คือประเด็นที่ต้องพิจารณาเมื่อใดก็ตามที่มีการเสนอคำนิยาม นิยามที่ถูกเสนอ—เช่น นิยามสารสนเทศของแชนนอน—สอดคล้องกับแนวคิดดั้งเดิมที่คุณมีมากแค่ไหน และแตกต่างไปมากแค่ไหน? แทบไม่มีนิยามใดที่สอดคล้องกับแนวคิดโดยสัญชาตญาณก่อนหน้าของคุณอย่างสมบูรณ์แบบ แต่ในระยะยาว นิยามนั่นเองที่กำหนดความหมายของแนวคิด—ดังนั้นการทำให้เป็นทางการผ่านนิยามที่เฉียบคมมักจะก่อให้เกิดการบิดเบือนอยู่เสมอ
กำหนดให้มีตัวอักษร q ตัวที่มีความน่าจะเป็น p i แล้ว ปริมาณสารสนเทศเฉลี่ย (ค่าคาดหวัง) ในระบบคือ
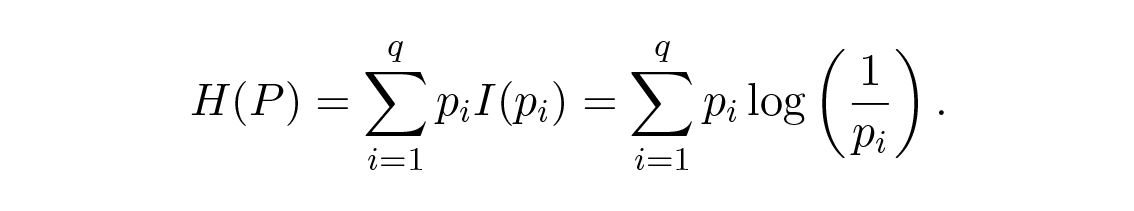
สิ่งนี้เรียกว่า เอนโทรปี (entropy) ของระบบที่มีการแจกแจงความน่าจะเป็น { p i } ชื่อ "เอนโทรปี" ถูกใช้เพราะรูปแบบทางคณิตศาสตร์เดียวกันนี้เกิดขึ้นในเทอร์โมไดนามิกส์และกลศาสตร์สถิติ ดังนั้นคำว่า "เอนโทรปี" จึงให้กลิ่นอายของความสำคัญซึ่งไม่สมเหตุสมผลในระยะยาว รูปแบบทางคณิตศาสตร์ที่เหมือนกันไม่ได้หมายถึงการตีความสัญลักษณ์ที่เหมือนกัน!
เอนโทรปีของการแจกแจงความน่าจะเป็นมีบทบาทสำคัญในทฤษฎีการเข้ารหัส (coding theory) ผลลัพธ์ที่สำคัญอย่างหนึ่งคือ อสมการของกิ๊บส์ (Gibbs' inequality) สำหรับการแจกแจงความน่าจะเป็นสองแบบที่แตกต่างกัน p i และ q i เราต้องพิสูจน์
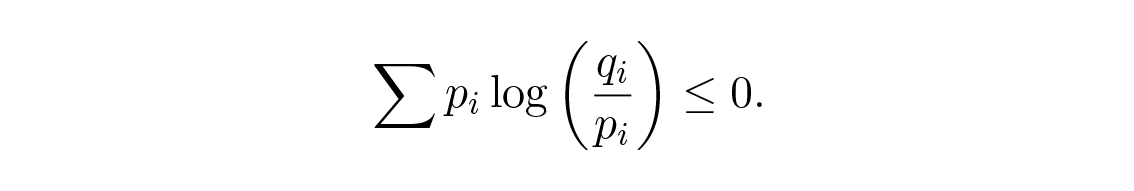
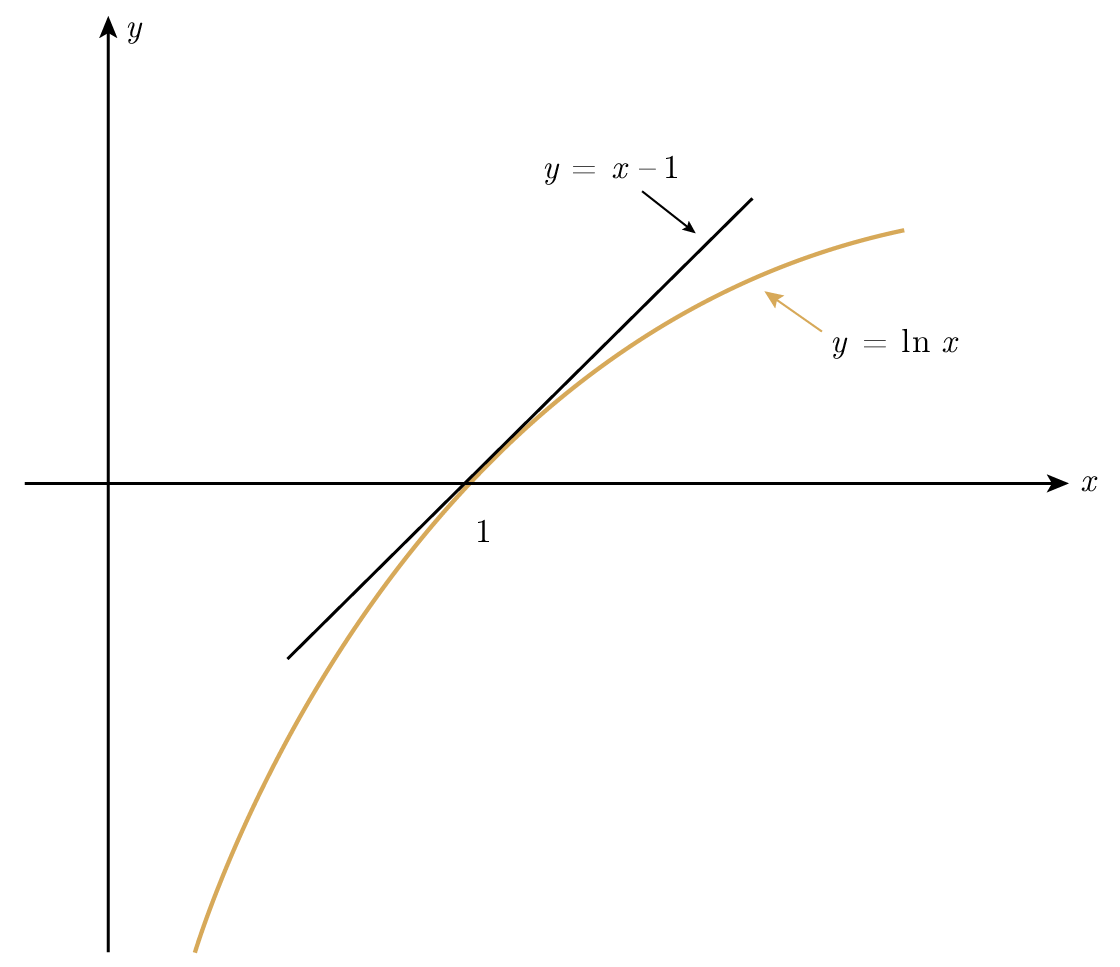
Figure 13.1—Log inequality (อสมการลอการิทึม)
การพิสูจน์อาศัยภาพที่ชัดเจน Figure 13.1 ว่า
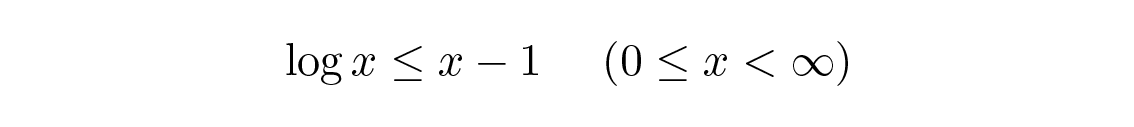
และการเท่ากันเกิดขึ้นที่ x \= 1 เท่านั้น การนำอสมการนี้ไปใช้กับผลรวมจากตอนต้นจะได้ดังต่อไปนี้
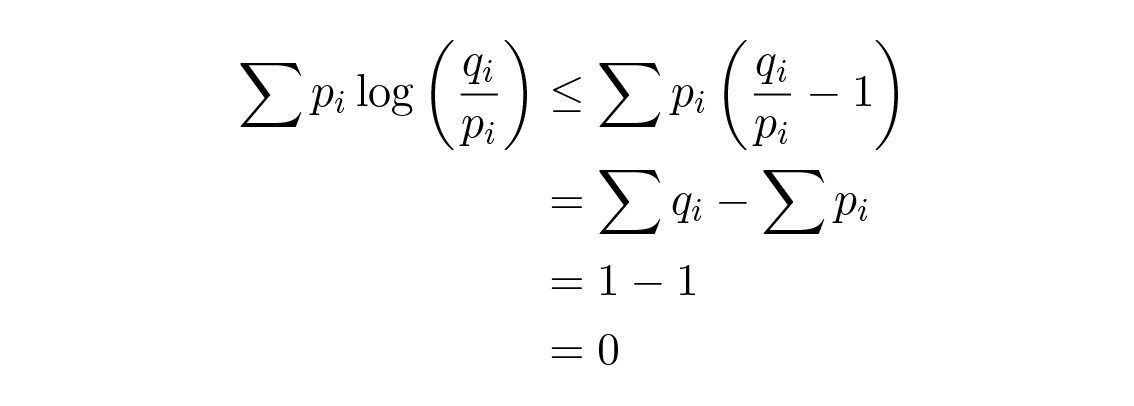
ถ้ามี q สัญลักษณ์ในระบบการส่งสัญญาณ การเลือก q i \= 1/ q จากอสมการของกิ๊บส์ โดยการย้ายเทอม q จะได้
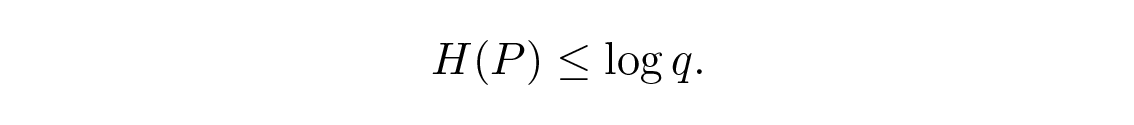
นี่บอกว่าในการแจกแจงความน่าจะเป็น ถ้าสัญลักษณ์ q ทั้งหมดมีความน่าจะเป็นเท่ากันคือ 1/ q แล้วเอนโทรปีสูงสุดจะเท่ากับ ln q พอดี และถ้าไม่เป็นเช่นนั้น อสมการก็จะเป็นจริง
กำหนดให้มี รหัสที่ถอดรหัสได้ไม่ซ้ำกัน (uniquely decodable code) เราจะได้ อสมการคราฟท์ (Kraft inequality)
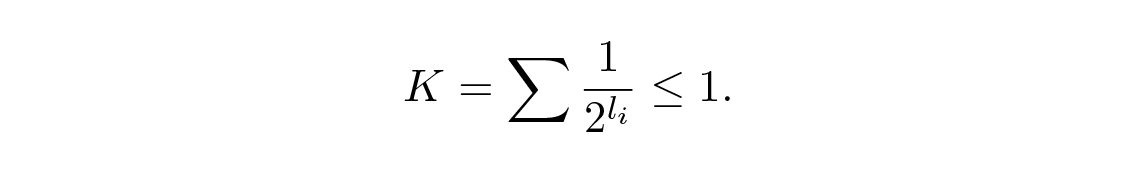
ทีนี้ถ้าเรานิยามความน่าจะเป็นเทียม (pseudo-probabilities)
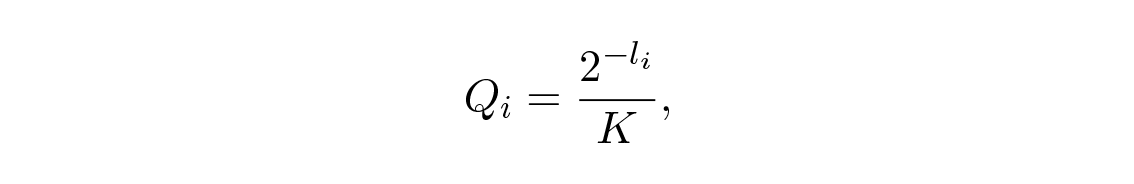
โดยแน่นอนว่า Σ [ Q i ] = 1 จากอสมการของกิ๊บส์จะได้ว่า
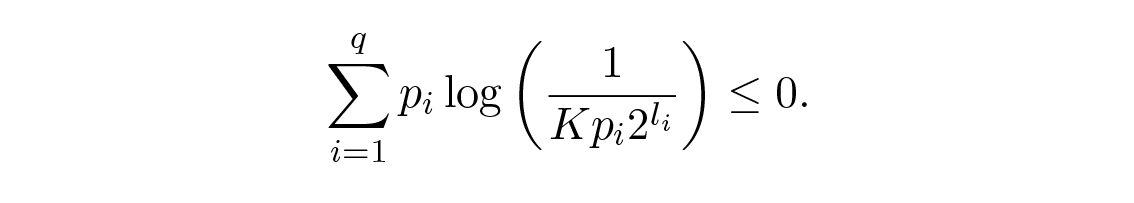
จากนั้นหลังจากพีชคณิตเล็กน้อย (จำไว้ว่า K ≤ 1 ดังนั้นเราสามารถทิ้งเทอม log และอาจทำให้อสมการเข้มงวดขึ้นได้):
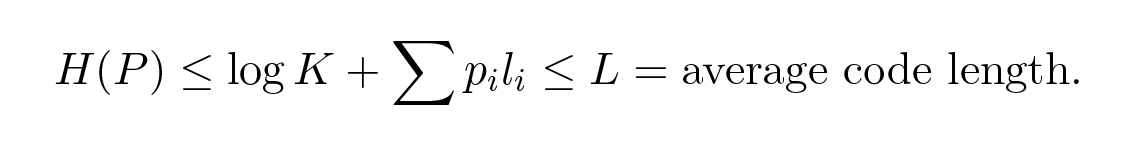
ดังนั้นเอนโทรปีจึงเป็นขอบล่าง (lower bound) สำหรับการเข้ารหัสใดๆ แบบ symbol ต่อ symbol สำหรับความยาวรหัสเฉลี่ย L นี่คือ ทฤษฎีบทการเข้ารหัสแบบไม่มีสัญญาณรบกวนของ แชนนอน (Shannon's noiseless coding theorem)
ตอนนี้เราจะมาพิจารณาทฤษฎีบทหลักเกี่ยวกับขอบเขตของระบบการส่งสัญญาณ ซึ่งใช้การเข้ารหัสของกระแส bit ที่เป็นอิสระต่อกันและแปลงแบบ symbol ต่อ symbol ในที่ที่มีสัญญาณรบกวน (in the presence of noise) หมายถึงมีความน่าจะเป็นที่ bit ของสารสนเทศถูกต้องคือ P > 1/2 และความน่าจะเป็นที่สอดคล้องกัน Q \= 1 – P ที่มันถูกเปลี่ยนแปลงเมื่อถูกส่ง เพื่อความสะดวก ให้ถือว่าข้อผิดพลาดเป็นอิสระต่อกันและเหมือนกันสำหรับแต่ละ bit ที่ส่ง ซึ่งเรียกว่า "white noise"
เราจะเข้ารหัสกระแสยาวของ n bits เข้าไปในข้อความที่เข้ารหัสหนึ่งชุด ซึ่งเป็นส่วนขยายลำดับที่ n ของรหัสหนึ่ง bit โดยที่ n จะถูกกำหนดในภายหลังเมื่อทฤษฎีดำเนินไป เราถือว่าข้อความของ n bits เป็นจุดหนึ่งในปริภูมิ n มิติ เนื่องจากเรามีส่วนขยายลำดับที่ n เพื่อความง่ายเราจะถือว่าแต่ละข้อความมีความน่าจะเป็นในการเกิดขึ้นเท่ากัน และเราจะถือว่ามี M ข้อความ ( M จะถูกกำหนดในภายหลังด้วย) ดังนั้นความน่าจะเป็นของแต่ละข้อความเริ่มต้นคือ 1/ M
ต่อไปเราจะพิจารณาแนวคิดของ ความจุของช่องสัญญาณ (channel capacity) โดยไม่ลงรายละเอียด ความจุของช่องสัญญาณถูกนิยามเป็นปริมาณสารสนเทศสูงสุดที่สามารถส่งผ่านช่องสัญญาณได้อย่างน่าเชื่อถือ โดยหาค่าสูงสุดเหนือการเข้ารหัสที่เป็นไปได้ทั้งหมด ดังนั้นจึงไม่มีการโต้แย้งว่าสามารถส่งสารสนเทศมากกว่าที่ความจุของช่องสัญญาณอนุญาตได้อย่างน่าเชื่อถือ สำหรับ binary symmetric channel (ที่เรากำลังใช้) สามารถพิสูจน์ได้ว่าความจุ C ต่อ bit ที่ส่ง คือ
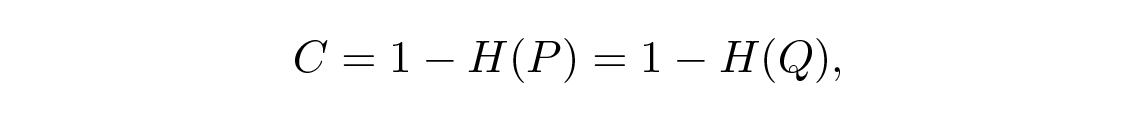
โดยที่ P คือความน่าจะเป็นที่ไม่มีข้อผิดพลาดใน bit ใดๆ ที่ส่ง สำหรับ n bits อิสระที่ส่ง เราจะมีความจุของช่องสัญญาณ
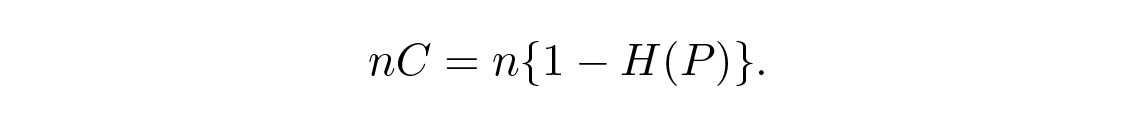
ถ้าเราต้องการเข้าใกล้ความจุของช่องสัญญาณ เราจะต้องส่งสารสนเทศในปริมาณเกือบเท่านั้นสำหรับแต่ละสัญลักษณ์ a i , i \= 1 , … , M และทั้งหมดมีความน่าจะเป็น 1/ M และเราจะต้องได้
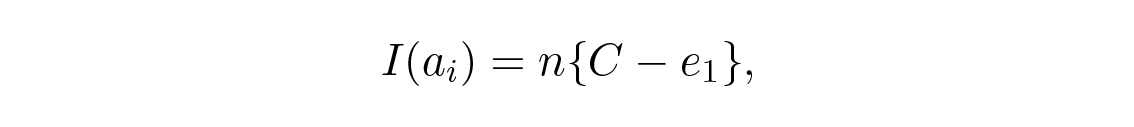
เมื่อเราส่งข้อความ a i ใดๆ ใน M ข้อความที่มีโอกาสเท่ากัน ดังนั้นเราจึงได้:
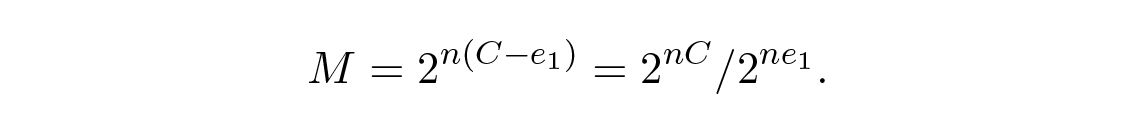
ด้วย n bits เราคาดว่าจะมีข้อผิดพลาด nQ ครั้ง ในทางปฏิบัติ สำหรับข้อความที่ส่งขนาด n bits เราจะมีข้อผิดพลาดประมาณ nQ ครั้งในข้อความที่ได้รับ สำหรับ n ที่มีขนาดใหญ่ การกระจายตัวเชิงสัมพัทธ์ ( spread = width ซึ่งคือรากที่สองของ variance ) ของการแจกแจงจำนวนข้อผิดพลาดจะแคบลงเรื่อยๆ เมื่อ n เพิ่มขึ้น
จากมุมมองของผู้ส่ง ผมนำข้อความ a i ที่จะส่ง และวาดทรงกลมรอบมันด้วยรัศมี
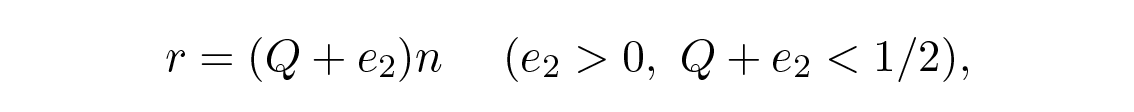
ซึ่งใหญ่กว่าจำนวนข้อผิดพลาดที่คาดไว้ Q เล็กน้อยด้วยค่า e 2 , Figure 13.2 ถ้า n มีขนาดใหญ่พอ ก็จะมีความน่าจะเป็นน้อยตามอำเภอใจที่จุดข้อความที่ได้รับ b j จะตกอยู่นอกทรงกลมนี้ เมื่อวาดภาพสถานการณ์ตามที่ผมในฐานะผู้ส่งเห็น เราจะมีตามรัศมีใดๆ จากสัญญาณที่เลือก a i ไปยังข้อความที่ได้รับ b j โดยที่ความน่าจะเป็นของข้อผิดพลาดเป็น (เกือบ) การแจกแจงแบบปกติ โดยมีจุดสูงสุดที่ nQ และสำหรับค่า e 2 ใดๆ จะมี n ที่มากพอจนความน่าจะเป็นที่จุดที่ได้รับ b j จะตกนอกทรงกลมของผมนั้นเล็กเท่าที่คุณต้องการ

Figure 13.2—Sender (ผู้ส่ง)

Figure 13.3—Receiver (ผู้รับ)
ทีนี้เมื่อมองจากฝั่งคุณ Figure 13.3 ในฐานะผู้รับ จะมีทรงกลม S ( r ) ที่มีรัศมี r เดียวกันรอบจุดที่ได้รับ b i ในปริภูมิ โดยที่ถ้าข้อความที่ได้รับ b i อยู่ ภายในทรงกลมของผม ข้อความต้นฉบับ a i ที่ผมส่งก็จะอยู่ภายในทรงกลมของคุณ
ข้อผิดพลาดเกิดขึ้นได้อย่างไร? ข้อผิดพลาดสามารถเกิดขึ้นได้ตามตารางต่อไปนี้
| กรณี | a i อยู่ใน S ( r ) | ตัวอื่นใน S ( r ) | ความหมาย |
|---|---|---|---|
| 1 | ใช่ | ใช่ | ข้อผิดพลาด |
| 2 | ใช่ | ไม่ | ไม่มีข้อผิดพลาด |
| 3 | ไม่ | ใช่ | | 4 | ไม่ | ไม่ | ข้อผิดพลาด |
ในที่นี้เราจะเห็นว่าถ้ามีจุดข้อความต้นฉบับอื่นอย่างน้อยหนึ่งจุดในทรงกลมรอบจุดที่ได้รับของคุณ ก็จะเกิดข้อผิดพลาด เนื่องจากคุณไม่สามารถตัดสินได้ว่ามันคือจุดไหน ข้อความที่ส่งจะถูกต้องก็ต่อเมื่อจุดที่ส่งอยู่ในทรงกลมและไม่มีจุดรหัสอื่นอยู่ในนั้น
ดังนั้นเราจึงมีสมการทางคณิตศาสตร์สำหรับความน่าจะเป็น P E ของข้อผิดพลาด ถ้าข้อความที่ส่งคือ a i :
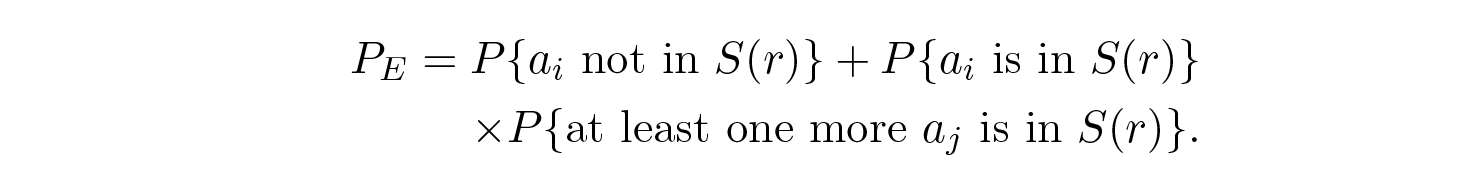
เราสามารถทิ้งตัวประกอบแรกในเทอมที่สองโดยตั้งค่าให้เท่ากับ 1 ทำให้เกิดอสมการ:
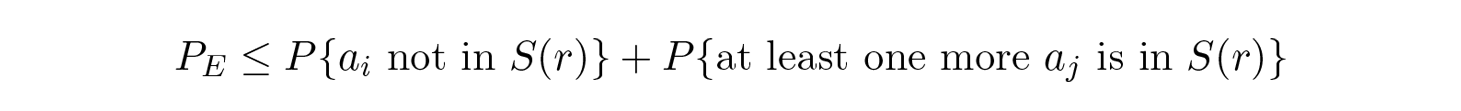
แต่ใช้ข้อเท็จจริงที่ชัดเจน
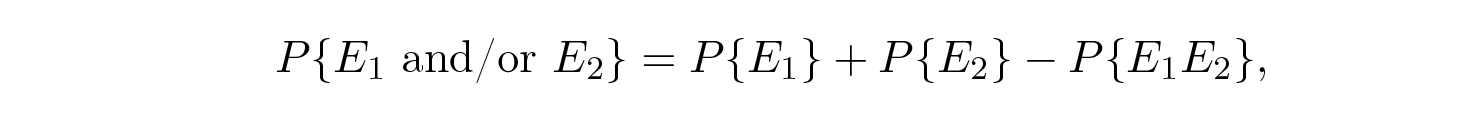
ดังนั้น
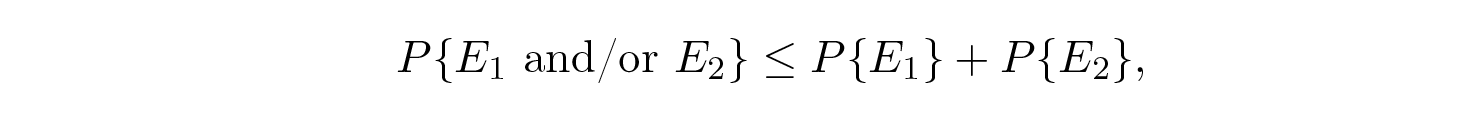
เมื่อนำไปใช้ซ้ำกับเทอมสุดท้ายทางขวาจะได้
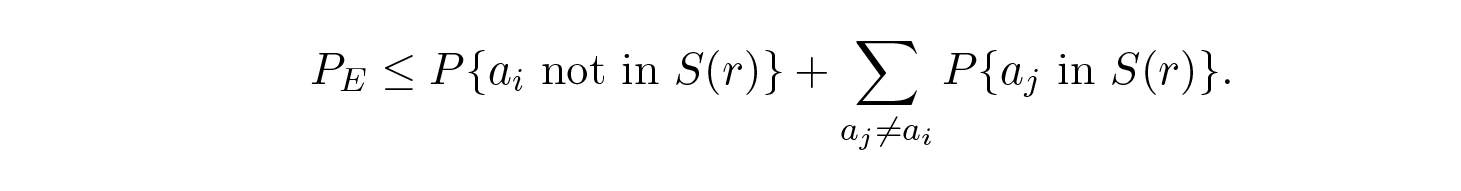
โดยการทำให้ n ใหญ่พอ เทอมแรกสามารถทำให้เล็กเท่าที่เราต้องการ เช่น น้อยกว่าจำนวน d ดังนั้นเราจึงได้:
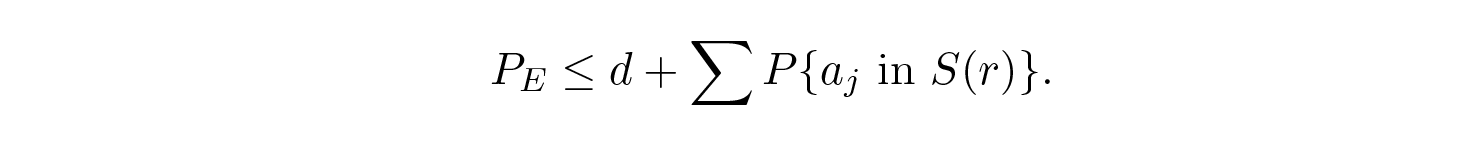
ทีนี้เรามาดูว่าเราจะสร้างสมุดรหัส (code book) สำหรับการเข้ารหัส M ข้อความ แต่ละข้อความยาว n bits ได้อย่างไร โดยไม่รู้วิธีการเข้ารหัส เนื่องจากรหัสแก้ไขข้อผิดพลาดยังไม่ถูกประดิษฐ์ขึ้นในตอนนั้น แชนนอนเลือกการเข้ารหัสแบบสุ่ม (random encoding) โดยโยนเหรียญสำหรับแต่ละ bit ของ n bits ของข้อความในสมุดรหัส แล้วทำซ้ำสำหรับ M ข้อความทั้งหมด มีการโยนทั้งหมด nM ครั้ง ดังนั้นจึงมีสมุดรหัสที่เป็นไปได้ 2 nM เล่ม โดยทุกเล่มมีความน่าจะเป็นเท่ากันคือ 1/2 nM แน่นอนว่ากระบวนการสุ่มในการสร้างสมุดรหัสหมายความว่ามีโอกาสที่จะมีรหัสซ้ำกัน และอาจมีจุดรหัสที่อยู่ใกล้กันซึ่งจะเป็นแหล่งของข้อผิดพลาดที่อาจเกิดขึ้น สิ่งที่เราต้องพิสูจน์คือสิ่งนี้จะไม่เกิดขึ้นโดยมีความน่าจะเป็นสูงกว่าระดับข้อผิดพลาดเล็กน้อยใดๆ ที่คุณเลือก—ตราบใดที่ n มีขนาดใหญ่พอ
ขั้นตอนที่ชี้ขาดคือแชนนอน หาค่าเฉลี่ยเหนือสมุดรหัสที่เป็นไปได้ทั้งหมด เพื่อหาค่าความผิดพลาดเฉลี่ย! เราจะใช้สัญลักษณ์ Av [ · ] เพื่อหมายถึงค่าเฉลี่ยเหนือเซตของสมุดรหัสสุ่มที่เป็นไปได้ทั้งหมด การหาค่าเฉลี่ยเหนือค่าคงที่ d แน่นอนว่าได้ค่าคงที่ และเราได้ เนื่องจากสำหรับค่าเฉลี่ยแต่ละเทอมจะเหมือนกับเทอมอื่นในผลรวม
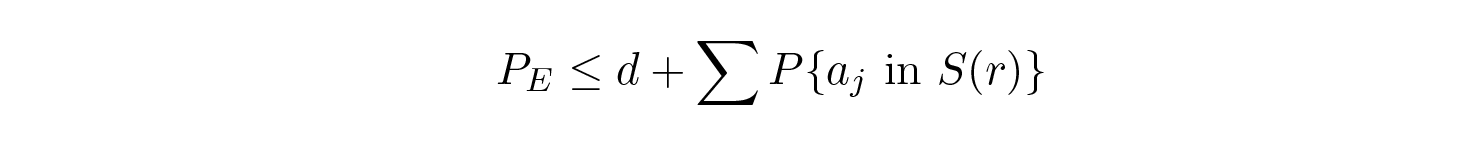
ซึ่งสามารถเพิ่มได้ ( M – 1 กลายเป็น M ) :
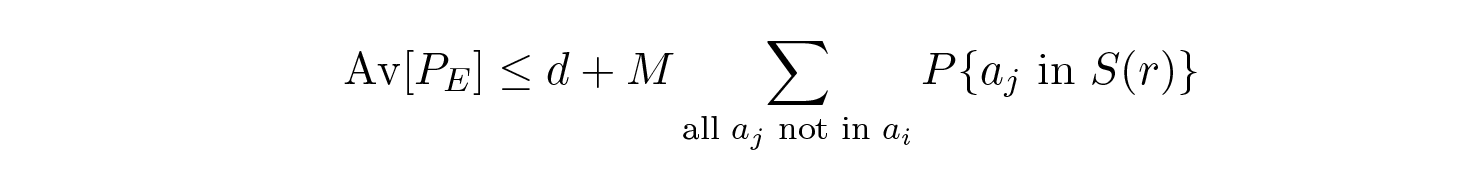
สำหรับข้อความใดข้อความหนึ่ง เมื่อเราหาค่าเฉลี่ยเหนือสมุดรหัสทั้งหมด การเข้ารหัสจะผ่านค่าที่เป็นไปได้ทั้งหมด ดังนั้นความน่าจะเป็นเฉลี่ยที่จุดหนึ่งอยู่ในทรงกลมคืออัตราส่วนของปริมาตรของทรงกลมต่อปริมาตรทั้งหมดของปริภูมิ ปริมาตรของทรงกลมคือ
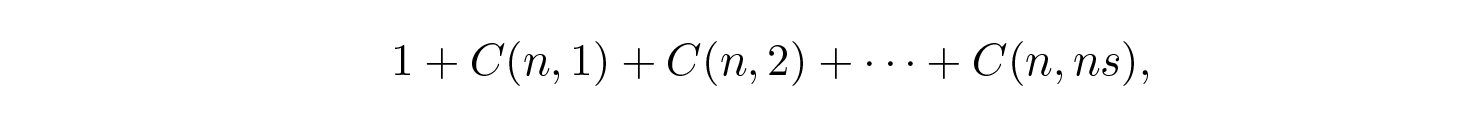
โดยที่ s = Q + e 2 < 1/2 และ ns ถือว่าเป็นจำนวนเต็ม
เทอมที่ใหญ่ที่สุดในผลรวมนี้คือเทอมสุดท้าย (ทางขวา) เราจะประมาณขนาดของมันก่อน โดยใช้ สูตรสเตอร์ลิง (Stirling's formula) สำหรับแฟกทอเรียล จากนั้นเราจะดูอัตราการลดลงไปยังเทอมก่อนหน้า สังเกตว่าอัตรานี้เพิ่มขึ้นเมื่อเราไปทางซ้าย และด้วยเหตุนี้เราจึงสามารถ: (1) ครอบงำ (dominate) ผลรวมด้วยลำดับเรขาคณิตที่มีอัตราเริ่มต้นนี้ (2) ขยายลำดับเรขาคณิตจาก ns เทอมไปจนถึงจำนวนอนันต์ (3) หาผลรวมของลำดับเรขาคณิตอนันต์ (ทั้งหมดเป็นพีชคณิตมาตรฐานที่ไม่สำคัญนัก) และสุดท้ายเราได้ (4) ขอบเขต (สำหรับ n ที่ใหญ่พอ):
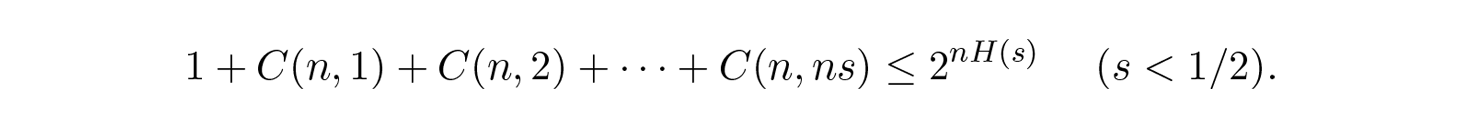
สังเกตว่าเอนโทรปี H ( s ) ปรากฏขึ้นในเอกลักษณ์ทวินาม
ตอนนี้เราต้องประกอบชิ้นส่วนทั้งหมดเข้าด้วยกัน สังเกตการกระจายแบบ Taylor series ของ H ( s ) = H ( Q + e 2 ) ให้ขอบเขตเมื่อเราหาอนุพันธ์เทอมแรกและละเลยเทอมอื่นๆ เพื่อให้ได้นิพจน์สุดท้าย
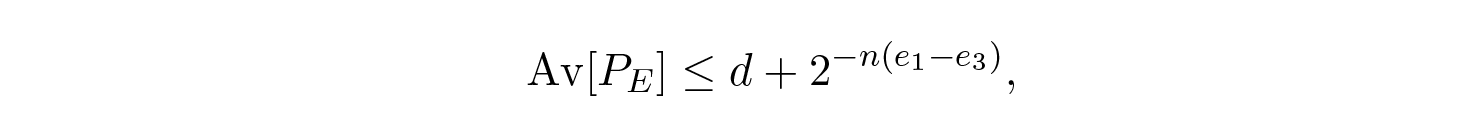
โดยที่
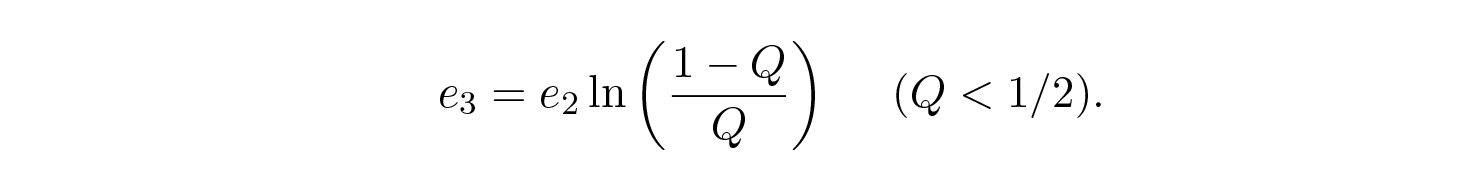
สิ่งที่เราต้องทำตอนนี้คือเลือก e 2 เพื่อให้ e 3 < e 1 และเทอมสุดท้ายจะเล็กเท่าที่คุณต้องการเมื่อ n มีขนาดใหญ่พอ ดังนั้นค่าเฉลี่ยของ P E สามารถทำให้เล็กเท่าที่คุณต้องการ ในขณะที่ยังคงเข้าใกล้ความจุของช่องสัญญาณ C ได้มากเท่าที่คุณต้องการ
ถ้าค่าเฉลี่ยเหนือรหัสทั้งหมดมีข้อผิดพลาดที่เล็กพอ ก็ต้องมีรหัสอย่างน้อยหนึ่งรหัสที่เหมาะสม—ดังนั้นจึงมีระบบการเข้ารหัสที่เหมาะสมอย่างน้อยหนึ่งระบบ นี่คือ ผลลัพธ์สำคัญของแชนนอน ซึ่งก็คือ "ทฤษฎีบทการเข้ารหัสในสัญญาณรบกวน (noisy coding theorem)" ถึงแม้ควรสังเกตว่าเขาพิสูจน์มันในรูปแบบที่ทั่วไปกว่ามาก ไม่ใช่แค่ binary symmetric channel แบบง่ายที่ผมใช้ คณิตศาสตร์ในกรณีทั่วไปยากกว่า แต่แนวคิดไม่ได้แตกต่างกันมากนัก ดังนั้นกรณีเฉพาะที่ใช้จึงเพียงพอที่จะแสดงให้คุณเห็นถึงธรรมชาติที่แท้จริงของทฤษฎีบท
มาวิพากษ์วิจารณ์ผลลัพธ์นี้กัน เราพูดซ้ำแล้วซ้ำเล่าว่า "สำหรับ n ที่ใหญ่เพียงพอ" แล้ว n ที่ว่านี้ใหญ่แค่ไหน? ใหญ่มากจริงๆ ถ้าคุณต้องการทั้งเข้าใกล้ความจุของช่องสัญญาณและมั่นใจได้อย่างสมเหตุสมผลว่าคุณถูกต้อง! ใหญ่เสียจนคุณอาจต้องรอนานมากเพื่อสะสมข้อความที่มีจำนวน bits ขนาดนั้นก่อนที่จะเข้ารหัส ยิ่งไม่ต้องพูดถึงขนาดของสมุดรหัสสุ่ม (ซึ่งเนื่องจากเป็นแบบสุ่ม จึงไม่สามารถแสดงในรูปแบบที่สั้นกว่าการแสดงรายการ Mn bits ทั้งหมดได้ โดยทั้ง M และ n ต่างก็ใหญ่มาก)
รหัสแก้ไขข้อผิดพลาด (error-correcting codes) หลีกเลี่ยงการรอข้อความยาวๆ แล้วเข้ารหัสผ่านสมุดรหัสขนาดใหญ่พร้อมกับสมุดถอดรหัสขนาดใหญ่ที่ตามมา เพราะพวกมันหลีกเลี่ยงสมุดรหัสและใช้วิธีการที่เป็นระบบ (คำนวณได้) ในทฤษฎีแบบง่าย พวกมันมักจะสูญเสียความสามารถในการเข้าใกล้ความจุของช่องสัญญาณมากและยังคงรักษาอัตราข้อผิดพลาดที่ต่ำตามอำเภอใจ แต่เมื่อข้อผิดพลาดจำนวนมากถูกแก้ไขโดยรหัส พวกมันก็สามารถทำงานได้ดี กล่าวอีกนัยหนึ่ง ถ้าคุณจัดสรรความสามารถสำหรับการแก้ไขข้อผิดพลาดในระดับหนึ่ง เพื่อประสิทธิภาพคุณต้องใช้ความสามารถนี้เกือบตลอดเวลา มิฉะนั้นคุณจะสูญเสียความสามารถไปเปล่าๆ และนี่หมายถึงจำนวนข้อผิดพลาดที่ถูกแก้ไขในแต่ละข้อความที่ส่งต้องสูง
แต่ทฤษฎีบทนี้ก็ไม่ได้ไร้ประโยชน์! มันแสดงให้เห็นว่า ตราบเท่าที่มันเกี่ยวข้อง โครงร่างการเข้ารหัสที่มีประสิทธิภาพต้องมีการเข้ารหัสที่ซับซ้อนมากของสาย bits สารสนเทศที่ยาวมาก เราเห็นสิ่งนี้เกิดขึ้นจริงในดาวเทียมที่เดินทางผ่านดาวเคราะห์ชั้นนอก พวกมันแก้ไขข้อผิดพลาดมากขึ้นเรื่อยๆ ต่อบล็อกเมื่อพวกมันอยู่ห่างจากทั้งโลกและดวงอาทิตย์มากขึ้นเรื่อยๆ (ซึ่งสำหรับดาวเทียมบางดวงก็เป็นแหล่งพลังงานแสงอาทิตย์ประมาณ 5 วัตต์สูงสุด บางดวงใช้แหล่งพลังงานนิวเคลียร์ที่มีกำลังใกล้เคียงกัน) พวกมันต้องใช้รหัสแก้ไขข้อผิดพลาดสูงเพื่อให้มีประสิทธิภาพ เมื่อพิจารณาจากกำลังส่งที่ต่ำของแหล่งกำเนิด ขนาดจานส่งสัญญาณที่เล็ก ขนาดจำกัดของจานรับสัญญาณบนโลกเมื่อมองจากตำแหน่งในอวกาศ และระยะทางมหาศาลที่สัญญาณต้องเดินทาง
เรากลับมายังปริภูมิ n มิติที่เราใช้ในการพิสูจน์ ในการอภิปรายเรื่องปริภูมิ n มิติ เราแสดงให้เห็นว่าเกือบทั้งหมดของปริมาตรของทรงกลมอยู่ใกล้พื้นผิวด้านนอก—ดังนั้นสำหรับทรงกลมที่ขยายออกเล็กน้อย (เชิงสัมพัทธ์) รอบสัญญาณที่ได้รับ จึงเกือบแน่นอนว่าสัญญาณต้นฉบับที่ส่งอยู่ในนั้น ดังนั้นการแก้ไขข้อผิดพลาดจำนวนมากตามอำเภอใจ nQ โดยแทบไม่มีข้อผิดพลาดหลังการถอดรหัสจึงไม่น่าแปลกใจ สิ่งที่น่าแปลกใจกว่าคือทรงกลม M ทั้งหมดสามารถถูกบรรจุได้โดยแทบไม่ทับซ้อนกัน—อีกครั้ง เป็นการทับซ้อนที่เล็กตามอำเภอใจ ข้อมูลเชิงลึกว่าทำไมสิ่งนี้จึงเป็นไปได้มาจากการตรวจสอบความจุของช่องสัญญาณอย่างละเอียดกว่าที่เราได้ทำไป แต่คุณเห็นแล้วว่าสำหรับรหัสแก้ไขข้อผิดพลาดแบบ Hamming ทรงกลมไม่มีการทับซ้อนเลย การมีทิศทางที่เกือบตั้งฉากกันมากมายในปริภูมิ n มิติบ่งชี้ว่าทำไมเราจึงสามารถบรรจุทรงกลม M ทั้งหมดลงในปริภูมิได้โดยมีการทับซ้อนน้อยมาก โดยการยอมให้มีการทับซ้อนเล็กน้อยตามอำเภอใจ ซึ่งอาจนำไปสู่ข้อผิดพลาดเพียงเล็กน้อยในการถอดรหัสของคุณ คุณสามารถได้รับการบรรจุที่หนาแน่นนี้ Hamming รับประกันระดับหนึ่งที่แน่นอน ส่วนแชนนอนรับประกันเพียงข้อผิดพลาดที่เล็กในเชิงความน่าจะเป็น แต่ใกล้เคียงกับความจุของช่องสัญญาณเท่าที่คุณต้องการ ซึ่งรหัส Hamming ไม่สามารถทำได้
ทฤษฎีสารสนเทศไม่ได้บอกคุณมากนักเกี่ยวกับวิธีการออกแบบ แต่มันชี้ทางไปสู่การออกแบบที่มีประสิทธิภาพ มันเป็นเครื่องมือที่มีค่าสำหรับวิศวกรรมระบบสื่อสารระหว่างสิ่งที่มีลักษณะคล้ายเครื่องจักร แต่อย่างที่สังเกตก่อนหน้านี้ มันไม่เกี่ยวข้องจริงๆ กับการสื่อสารสารสนเทศของมนุษย์ ขอบเขตที่การถ่ายทอดทางชีววิทยา (biological inheritance) มีลักษณะคล้ายเครื่องจักร ดังนั้นคุณจึงสามารถใช้ทฤษฎีสารสนเทศกับยีนได้ และขอบเขตที่มันไม่ใช่ ดังนั้นการประยุกต์ใช้จึงไม่เกี่ยวข้อง เพียงแค่ยังไม่เป็นที่รู้จักในปัจจุบัน ดังนั้นเราจึงต้องลอง และความสำเร็จจะแสดงให้เห็นถึงลักษณะคล้ายเครื่องจักร ในขณะที่ความล้มเหลวจะชี้ไปยังแง่มุมอื่นๆ ของสารสนเทศที่สำคัญ
ตอนนี้เราจะสกัดบทเรียนที่เราได้เรียนรู้ เราเห็นแล้วว่านิยามเริ่มต้นทั้งหมด ไม่มากก็น้อย ควรจะจับแก่นแท้ของความเชื่อก่อนหน้าของเรา แต่มันก็มีการบิดเบือนในระดับหนึ่งเสมอ และด้วยเหตุนี้จึงไม่สามารถใช้ได้กับสิ่งที่เราคิดว่ามันเป็นตามที่เราคิดไว้ เป็นธรรมเนียมที่จะยอมรับ ในระยะยาว ว่าคำนิยามที่เราใช้จริงๆ แล้วกำหนดสิ่งของที่ถูกนิยาม แต่แน่นอนว่ามันแค่บอกเราถึงวิธีจัดการกับสิ่งต่างๆ และไม่มีทางบอกความหมายที่แท้จริงแก่เราเลย แนวทางแบบ postulational ซึ่งเป็นที่นิยมอย่างมากในแวดวงคณิตศาสตร์ ยังคงเป็นที่ต้องการอีกมากในทางปฏิบัติ
ตอนนี้เราจะมาดูตัวอย่างที่นิยามยังคงเป็นปัญหาสำหรับเรา นั่นคือ iq มันเป็นวงจรซ้ำแล้วซ้ำเล่าเท่าที่คุณจะจินตนาการได้ มีการสร้างแบบทดสอบขึ้นมาเพื่อวัด "ความฉลาด" มันถูกปรับปรุงแก้ไขให้สอดคล้องภายในเท่าที่ทำได้ จากนั้นก็ถูกประกาศว่า เมื่อปรับเทียบด้วยวิธีการง่ายๆ แล้ว มันสามารถวัด "ความฉลาด" ซึ่งตอนนี้มีการแจกแจงแบบปกติ (ผ่านเส้นโค้งการปรับเทียบ) นิยามทั้งหมดควรถูกตรวจสอบ ไม่ใช่แค่ตอนที่ถูกเสนอครั้งแรก แต่ในภายหลัง เมื่อคุณเห็นว่ามันจะเข้าไปมีส่วนในข้อสรุปที่ได้มากน้อยแค่ไหน นิยามถูกสร้างกรอบขึ้นมาภายใต้เงื่อนไขหนึ่งมากแค่ไหน ปัจจุบันถูกนำไปใช้ภายใต้เงื่อนไขที่ต่างออกไปมากแค่ไหน? บ่อยครั้งเกินไปที่สิ่งเหล่านี้เป็นจริง! และมันอาจจะเป็นจริงมากขึ้นเรื่อยๆ เมื่อเราก้าวลึกเข้าไปในวิทยาศาสตร์ที่อ่อนลง (softer sciences) ซึ่งเป็นสิ่งที่หลีกเลี่ยงไม่ได้ในช่วงชีวิตของคุณ
ดังนั้นจุดประสงค์หนึ่งของการนำเสนอทฤษฎีสารสนเทศนี้ นอกเหนือจากประโยชน์ในตัวมันแล้ว คือการทำให้คุณตระหนักถึงอันตรายนี้ หรือถ้าคุณต้องการ วิธีใช้มันเพื่อให้ได้สิ่งที่คุณต้องการ! เป็นที่ยอมรับกันมานานแล้วว่านิยามเริ่มต้นกำหนดสิ่งที่คุณค้นพบ มากกว่าที่คนส่วนใหญ่จะเต็มใจเชื่อ นิยามเริ่มต้นต้องการความสนใจอย่างระมัดระวังจากคุณในทุกสถานการณ์ใหม่ และมันคุ้มค่าที่จะทบทวนในสาขาที่คุณทำงานมานาน เพื่อให้คุณเข้าใจว่าผลลัพธ์นั้นเป็นเพียงการซ้ำซาก (tautology) มากแค่ไหน และไม่ใช่ผลลัพธ์ที่แท้จริงเลย
มีเรื่องเล่าที่มีชื่อเสียงโดย Eddington เกี่ยวกับคนบางกลุ่มที่ไปตกปลาในทะเลด้วยอวน หลังจากตรวจสอบขนาดของปลาที่พวกเขาจับได้ พวกเขาก็สรุปว่าปลาในทะเลมีขนาดขั้นต่ำที่แน่นอน! ข้อสรุปของพวกเขาเกิดจากเครื่องมือที่ใช้ ไม่ใช่จากความเป็นจริง