ในบทนี้มีสองเรื่องที่เราจะพูดถึง เรื่องแรกคือหัวข้อหลักอย่างรหัสแก้ไขข้อผิดพลาด (error-correcting codes) และอีกเรื่องคือว่ากระบวนการค้นพบนั้นมักเกิดขึ้นได้อย่างไร—คุณทุกคนคงรู้ว่าผมเป็นผู้ค้นพบรหัสแก้ไขข้อผิดพลาดของ Hamming อย่างเป็นทางการ ดังนั้นผมคงอยู่ในฐานะที่จะเล่าได้ว่ามันถูกค้นพบได้อย่างไร แต่คุณควรระวังรายงานลักษณะใดๆ แบบนี้ด้วย ความจริงคือตอนนั้นผมสนใจกระบวนการค้นพบอยู่แล้วมาก โดยเชื่อว่าในหลายกรณี วิธีการค้นพบสำคัญกว่าสิ่งที่ค้นพบ ผมรู้ดีพอที่จะไม่คิดถึงกระบวนการตอนที่กำลังทำวิจัย เหมือนกับนักกีฬาที่ไม่คิดถึงท่าทางตอนกำลังเล่นกีฬา แต่พวกเขาฝึกท่าทางจนมันกลายเป็นอัตโนมัติไม่มากก็น้อย ผมจึงสร้างนิสัยว่า หลังจากค้นพบอะไรบางอย่างไม่ว่าจะสำคัญมากหรือน้อย ก็จะย้อนกลับไปพยายามตามรอยขั้นตอนที่ดูเหมือนจะนำไปสู่การค้นพบนั้น แต่อย่าหลงเชื่อนะครับ สิ่งที่ดีที่สุดที่ผมทำได้คือเล่าส่วนที่รู้ตัว และส่วนใต้จิตสำนึกระดับบนได้บ้าง แต่เราไม่รู้เลยว่าจิตใต้สำนึกทำงานมหัศจรรย์ของมันได้อย่างไร
ตอนนั้นผมกำลังใช้คอมพิวเตอร์รีเลย์ Model 5 ในนครนิวยอร์ก เพื่อเตรียมส่งมอบให้กับ Aberdeen Proving Grounds พร้อมกับซอฟต์แวร์ที่จำเป็น (ส่วนใหญ่เป็น routine ทางคณิตศาสตร์) เมื่อเกิด error ขึ้นซึ่งถูกตรวจพบโดย block code แบบ 2-out-of-5 เครื่องจะทำซ้ำขั้นตอนนั้นถึงสามครั้งเมื่อไม่มีคนดูแล ก่อนจะทิ้งมันแล้วหยิบโจทย์ข้อต่อไปขึ้นมาทำ โดยหวังว่าอุปกรณ์ที่เสียจะไม่เกี่ยวข้องกับโจทย์ใหม่ ตอนนั้นผมเป็นคนระดับล่างสุดในสายงาน อย่างที่เขาพูดกัน ผมได้เวลาใช้เครื่องฟรีเฉพาะวันหยุดสุดสัปดาห์—หมายถึงตั้งแต่ประมาณบ่ายวันศุกร์ 5 โมง ถึงเช้าวันจันทร์ประมาณ 8 โมง ซึ่งเป็นเวลาที่เยอะมาก! ผมจึงโหลด input tape ด้วยโจทย์จำนวนมาก และสัญญากับเพื่อนๆ ที่ Murray Hill, รัฐนิวเจอร์ซีย์ ซึ่งเป็นที่ตั้งของแผนกวิจัย ว่าจะส่งคำตอบให้พวกเขาในวันอังคาร แล้วอยู่มาวันหยุดสุดสัปดาห์หนึ่ง หลังจากที่พวกเราแยกย้ายกันกลับบ้านในคืนวันศุกร์ เครื่องก็ล้มเหลวโดยสิ้นเชิง และผมแทบไม่ได้อะไรเลยในวันจันทร์ ผมต้องขอโทษเพื่อนๆ และสัญญาว่าจะส่งคำตอบให้ในวันอังคารถัดไป อนิจจา! เหตุการณ์เดิมเกิดขึ้นอีก! ผมโกรธมาก พูดได้เลยว่าโกรธสุดๆ และพูดว่า "ถ้าเครื่องสามารถบอกได้ว่ามี error ทำไมมันถึงบอกไม่ได้ล่ะว่า error อยู่ที่ไหน แล้วแก้ไขมันโดยการเปลี่ยน bit ให้เป็นสถานะตรงข้าม" (ภาษาที่ใช้จริงอาจจะรุนแรงกว่านี้หน่อย!)
สังเกตว่าขั้นตอนสำคัญนี้เกิดขึ้นได้ก็เพราะตอนนั้นผมอยู่ภายใต้ความกดดันทางอารมณ์อย่างหนัก และนี่คือลักษณะเฉพาะของการค้นพบที่ยิ่งใหญ่ส่วนใหญ่ การทำงานอย่างใจเย็นจะช่วยให้คุณขยายความและต่อยอดสิ่งต่างๆ ได้ แต่การค้นพบครั้งสำคัญโดยทั่วไปมักเกิดขึ้นหลังจากความหงุดหงิดและการมีส่วนร่วมทางอารมณ์อย่างมาก นักวิจัยที่ใจเย็น เยือกเย็น และไม่ยึดติด มักไม่ค่อยสร้างก้าวสำคัญที่ยิ่งใหญ่จริงๆ
กลับมาเข้าเรื่องกันต่อ ผมรู้จากการพูดคุยก่อนหน้านี้ว่าแน่นอนคุณสามารถสร้างเครื่องสามชุด ใส่วงจรเปรียบเทียบ และใช้เสียงข้างมาก (majority vote)—ดังนั้นเครื่องที่แก้ไข error ได้จึงมีอยู่จริง แต่แลกกับต้นทุนที่สูงขนาดไหน! แน่นอนว่าต้องมีวิธีการที่ดีกว่านี้ ผมยังรู้ด้วย ตามที่คุยกันในบทที่แล้ว เกี่ยวกับ parity checks มากมาย ผมได้ศึกษา fundamentals ของมันอย่างละเอียดถี่ถ้วน
อีกเรื่องแทรกเล็กน้อย ปาสเตอร์กล่าวว่า "โชคเข้าข้างผู้ที่เตรียมพร้อม" คุณเห็นไหมว่าผมเตรียมพร้อมด้วยผลงานก่อนหน้านี้ที่ผมทำ ผมไม่ได้แค่คุ้นเคยกับรหัส 2-out-of-5 เท่านั้น แต่ผมเข้าใจมันในระดับพื้นฐาน และได้คิดและเข้าใจความหมายทั่วไปของ parity check

Figure 12.1—First error-correcting codes (รหัสแก้ไขข้อผิดพลาดแบบแรก)
หลังจากคิดอยู่พักหนึ่ง ผมก็ตระหนักว่าถ้าจัดเรียง message bits ของสัญลักษณ์ข้อความใดๆ เป็นรูปสี่เหลี่ยมผืนผ้า และใส่ parity checks ในแต่ละแถวและแต่ละคอลัมน์ แล้ว parity checks ที่ล้มเหลวสองตัวจะบอกพิกัดของ error เดียวให้เรา และนี่รวมถึง parity bit ที่มุมที่เพิ่มเข้ามาด้วย (ซึ่งสามารถตั้งค่าให้สอดคล้องกันได้ถ้าใช้ even parities) Figure 12.1 . ความซ้ำซ้อน (redundancy) ซึ่งก็คืออัตราส่วนระหว่างสิ่งที่ใช้จริงกับปริมาณขั้นต่ำที่ต้องการ คือ
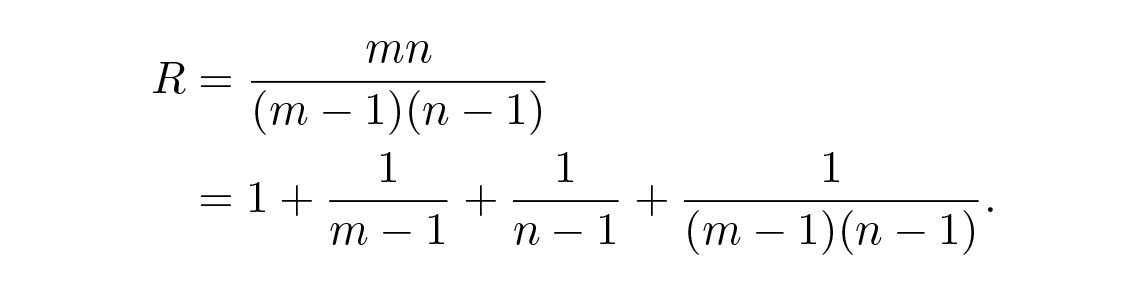
ใครก็ตามที่เคยเรียนแคลคูลัสจะเห็นได้ทันทีว่า ยิ่งสี่เหลี่ยมผืนผ้าใกล้เป็นรูปสี่เหลี่ยมจัตุรัสมากเท่าไร redundancy ก็ยิ่งต่ำลงสำหรับข้อความจำนวนเท่าเดิม และแน่นอนว่า m และ n ที่มีค่ามากย่อมดีกว่าค่าน้อย แต่ความเสี่ยงของ double error ก็อาจสูงเกินไป—อีกแล้วที่ต้องใช้ judgment ทางวิศวกรรม สังเกตว่าถ้าเกิด error สองครั้งขึ้น (1) ถ้าไม่อยู่ในคอลัมน์เดียวกันและไม่ใช่แถวเดียวกัน ก็จะมีแถวที่ล้มเหลวสองแถวและคอลัมน์ที่ล้มเหลวสองคอลัมน์ และคุณจะไม่รู้ว่าคู่ diagonal ไหนเป็นต้นเหตุ และ (2) ถ้าสองตัวอยู่ในแถวเดียวกัน (หรือคอลัมน์เดียวกัน) คุณก็จะเห็นเฉพาะคอลัมน์ (หรือแถว) ที่ล้มเหลวเท่านั้น แต่ไม่เห็นแถว (หรือคอลัมน์)
ต่อมาเราขยับเวลาถัดไปอีกสองสามสัปดาห์ การจะไปนครนิวยอร์ก ผมต้องไปที่ Murray Hill, รัฐนิวเจอร์ซีย์ ซึ่งเป็นที่ทำงานก่อนเวลาเล็กน้อย แล้วนั่งรถไปกับรถส่งจดหมายของบริษัท การขับรถผ่านนอร์ธเจอร์ซีย์ตอนเช้าตรู่ไม่ได้เป็นวิวที่สวยงามอะไรนัก ดังนั้นผมจึงทำตามนิสัยที่เคยทำ คือทบทวนความสำเร็จต่างๆ เพื่อให้มีรูปแบบติดตัวไปโดยอัตโนมัติ โดยเฉพาะอย่างยิ่งผมกำลังทบทวนรหัสรูปสี่เหลี่ยมผืนผ้าในใจ ทันใดนั้น—และผมหาเหตุผลไม่ได้—ผมก็ตระหนักว่าถ้าใช้รูปสามเหลี่ยมและวาง parity checks ไว้ตามแนวทแยง โดยแต่ละ parity check ตรวจสอบทั้งแถวและคอลัมน์ที่มันอยู่ ผมก็จะได้ redundancy ที่ดีกว่า Figure 12.2 .

Figure 12.2—Next error-correcting codes (รหัสแก้ไขข้อผิดพลาดแบบถัดไป)
ความพอใจของผมก็หายไปในทันที! คราวนี้ผมได้ code ที่ดีที่สุดหรือยัง? หลังจากคิดอยู่สองสามไมล์บนถนน (จำไว้ว่าไม่มีอะไร distracting ในวิวนอร์ธเจอร์ซีย์) ผมก็ตระหนักว่าลูกบาศก์ของ information bits ที่มี parity checks ครอบคลุมทั้งระนาบ และ parity check bit บนแกนทั้งสามแกน จะให้พิกัดสามแกนของ error โดยแลกกับ parity checks จำนวน 3 n – 2 ตัวสำหรับข้อความที่เข้ารหัสทั้งหมด n 3 ตัว ดีกว่า! แต่มันดีที่สุดหรือไม่? ไม่! ในฐานะนักคณิตศาสตร์ ผมก็ตระหนักได้ทันทีว่าลูกบาศก์สี่มิติ (ผมไม่จำเป็นต้องจัดเรียงมันแบบนั้น แค่ต่อสายให้เป็นแบบนั้นก็พอ) จะดีกว่า ดังนั้นลูกบาศก์ที่มีมิติสูงขึ้นไปอีกก็จะยิ่งดีขึ้นไปอีก ไม่นานก็เห็นชัด (ประมาณห้าไมล์) ว่าลูกบาศก์ 2 × 2 × 2 × … × 2 ที่มี parity checks n + 1 ตัวน่าจะดีที่สุด—ดูเหมือนอย่างนั้น!
แต่เพราะเคยโดนเผามาก่อน ผมเลยไม่ยอมพอใจกับสิ่งที่ดูดี—ผมเคยทำผิดพลาดแบบนั้นมาก่อน! ผมพิสูจน์ได้ไหมว่ามันดีที่สุด? จะพิสูจน์ยังไงดี? วิธีหนึ่งที่ชัดเจนคือลองใช้การนับจำนวน (counting argument) ผมมี parity checks n + 1 ตัว ซึ่งผลลัพธ์คือ string ความยาว n + 1 bits ซึ่งเป็นเลขฐานสองยาว n + 1 bits และมันสามารถแทนสิ่งต่างๆ ได้ 2 n + 1 อย่าง แต่ผมต้องการแค่ 2 n + 1 อย่าง นั่นคือ 2 n จุดในลูกบาศก์ บวกกับผลลัพธ์ที่บอกว่าข้อความถูกต้อง ผมคลาดเคลื่อนไปเกือบสองเท่า อนิจจา! ผมมาถึงหน้าประตูบริษัทพอดี และต้องเซ็นชื่อเข้าและไปประชุม เลยต้องพักแนวคิดนี้ไว้ก่อน
เมื่อผมกลับมาที่แนวคิดนี้อีกครั้งหลังจากถูก distractions หลายวัน (ยังไงก็ตาม ผมยังต้องทำงานตามหน้าที่ให้กับบริษัท) ในที่สุดผมก็ตัดสินใจว่าวิธีที่ดีคือการใช้ syndrome ของ error เป็นเลขฐานสองที่ระบุตำแหน่งของ error โดยที่ 0 ทั้งหมดหมายถึงคำตอบที่ถูกต้อง (ซึ่งทดสอบง่ายกว่าการใช้ 1 ทั้งหมดในคอมพิวเตอร์ส่วนใหญ่) สังเกตว่าความคุ้นเคยกับระบบเลขฐานสอง ซึ่งยังไม่แพร่หลายในตอนนั้น (ค.ศ. 1947–1948) มีบทบาทสำคัญในการคิดของผมซ้ำแล้วซ้ำเล่า การรู้มากกว่าที่จำเป็นในขณะนั้นให้ผลคุ้มค่า!
จะออกแบบกรณีเฉพาะของรหัสแก้ไขข้อผิดพลาดนี้ยังไง? ง่ายนิดเดียว! เขียนตำแหน่งต่างๆ ในรหัสฐานสอง:
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 1000 |
| 9 | 1001 |
| … | … |
ตอนนี้ก็เห็นได้ชัดว่า parity check ทางด้านขวาของ syndrome ต้องเกี่ยวข้องกับทุกตำแหน่งที่มี 1 อยู่ในคอลัมน์ขวาสุด ส่วนหลักที่สองจากขวาต้องเกี่ยวข้องกับตัวเลขที่มี 1 อยู่ในคอลัมน์ที่สอง ฯลฯ ดังนั้นคุณจะได้:
| Parity check #1 | 1, | 3, | 5, | 7, | 9, | 11, | 13, | 15, | … |
| Parity check #2 | 2, | 3, | 6, | 7, | 10, | 11, | 14, | 15, | … |
| Parity check #3 | 4, | 5, | 6, | 7, | 12, | 13, | 14, | 15, | … |
| Parity check #4 | 8, | 9, | 10, | 11, | 12, | 13, | 14, | 15, | … |
ดังนั้นถ้าเกิด error ขึ้นที่ตำแหน่งใดก็ตาม parity checks เฉพาะชุดนั้น (และเฉพาะชุดนั้น) จะล้มเหลวและให้ค่า 1 ใน syndrome และนี่จะสร้างค่าที่ตรงกับการแทนค่าในระบบฐานสองของตำแหน่งของ error นั้นพอดี ง่ายขนาดนั้นเอง!
เพื่อดูการทำงานของ code สมมติว่าเราใช้แค่ตำแหน่ง message สี่ตำแหน่งและ check positions สามตำแหน่ง ตัวเลขเหล่านี้เป็นไปตามเงื่อนไข
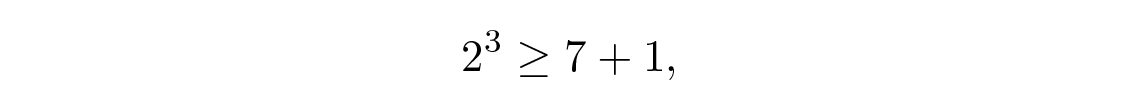
ซึ่งเป็นเงื่อนไขที่จำเป็นอย่างชัดเจน และกรณีที่เท่ากันก็เพียงพอ เราจะเลือกตำแหน่งของ check bits (เพื่อให้การตั้งค่า parity check ทำได้ง่าย) เป็นตำแหน่ง check 1 , 2 และ 4 ดังนั้นตำแหน่ง message จึงเป็น 3 , 5 , 6 และ 7 ให้ message เป็น
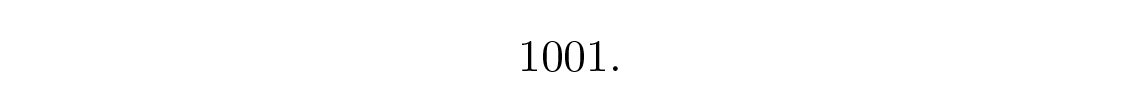
เราจะ (1) เขียน message ในบรรทัดบนสุด (2) เข้ารหัสในบรรทัดถัดไป (3) ใส่ error ที่ตำแหน่ง 6 ในบรรทัดถัดไป และ (4) ในสามบรรทัดถัดไปคำนวณ parity checks ทั้งสาม
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | position (ตำแหน่ง) |
| 1 | 0 | 0 | 1 | message (ข้อความ) | |||
| 0 | 0 | 1 | 1 | 0 | 0 | 1 | encoded message (ข้อความที่เข้ารหัสแล้ว) |
| 0 | 0 | 1 | 1 | 0 | 1 | 1 | message with error (ข้อความที่มี error) |
จากนั้นให้ใช้ parity checks กับข้อความที่ได้รับ

เลขฐานสอง 110 มีค่าเท่ากับเลขฐานสิบ 6 ดังนั้นให้เปลี่ยน digit ที่ตำแหน่ง 6 จากนั้นทิ้ง check positions 1 , 2 และ 4 คุณจะได้ message ดั้งเดิมคือ 1001 .
ถ้ามันดูเหมือนเวทมนตร์ ลองคิดถึง message ที่เป็น 0 ทั้งหมด ซึ่ง checks ทุกตัวจะเป็น 0 จากนั้นคิดถึงการเปลี่ยนแปลงของ digit เดียว แล้วคุณจะเห็นว่าเมื่อตำแหน่งของ error เปลี่ยนไป ค่า syndrome ในระบบฐานสองก็จะเปลี่ยนตาม และจะตรงกับตำแหน่งของ error พอดีเสมอ ต่อไป สังเกตว่าผลรวมของ correct messages ใดๆ สองตัวยังคงเป็น correct message (parity checks เป็นแบบบวก modulo 2 ดังนั้น correct messages จึงรวมกันเป็น additive group modulo 2 ) correct message จะให้ค่า 0 ทั้งหมด ดังนั้นผลรวมของ correct message บวกกับ error ในหนึ่งตำแหน่งจะให้ตำแหน่งของ error ไม่ว่าข้อความที่ส่งจะเป็นอะไรก็ตาม parity checks จะมุ่งไปที่ error และไม่สนใจ message
ต่อไปก็เห็นได้ทันทีว่าการสลับคอลัมน์สองคอลัมน์ขึ้นไป เมื่อตกลงกันทั้งสองฝั่งของช่องทางการสื่อสารแล้ว จะไม่มีผลสำคัญอะไร code จะ equivalent (เทียบเท่า) ในทำนองเดียวกัน การสลับ 0 และ 1 ในคอลัมน์ใดๆ (การ complement ตำแหน่งนั้น) ก็จะไม่ทำให้ code แตกต่างกันโดยสาระสำคัญ รหัส Hamming แบบเฉพาะ (ที่เรียกกัน) นั้นเป็นเพียงการจัดเรียงที่น่ารักเท่านั้น และในทางปฏิบัติคุณอาจต้องการให้ check bits มาอยู่ท้าย message แทนที่จะกระจายอยู่กลาง message
แล้ว double error ล่ะ? ถ้าเราต้องการจับ (แต่ไม่สามารถแก้ไขได้) double error เราแค่เพิ่ม parity check ใหม่ตัวเดียวครอบคลุมทั้ง message ที่เราส่ง มาดูกันว่าจะเกิดอะไรขึ้นที่ฝั่งรับ
| old syndrome (syndrome เดิม) | new parity check (parity check ใหม่) | meaning (ความหมาย) |
|---|---|---|
| 000 | 0 | right answer (คำตอบถูกต้อง) |
| 000 | 1 | new parity check wrong (parity check ใหม่ผิด) |
| xxx | 1 | old parity check works (parity check เดิมใช้ได้) |
| xxx | 0 | must be double error (ต้องเป็น double error) |
รหัสที่แก้ไข error เดี่ยวได้และตรวจจับ double error ได้ (single error correcting plus double error detecting) มักเป็นสมดุลที่ดี แน่นอนว่า redundancy ในข้อความสั้นๆ สี่บิต ที่ตอนนี้มี check สี่บิตนั้นแย่ แต่จำนวน parity bits จะเพิ่มขึ้นประมาณ log ของความยาวข้อความ ถ้าข้อความยาวเกินไปก็เสี่ยงต่อ double error ที่แก้ไขไม่ได้ (ซึ่งในรหัสที่แก้ไข error เดี่ยวได้ คุณจะ "แก้ไข" มันกลายเป็น error ที่สาม) ถ้าข้อความสั้นเกินไป redundancy ก็แพงเกินไป อีกแล้วที่ต้องใช้ judgment ทางวิศวกรรมขึ้นอยู่กับสถานการณ์เฉพาะ
จากเรขาคณิตวิเคราะห์ คุณได้เรียนรู้คุณค่าของการใช้มุมมองทั้งแบบพีชคณิตและเรขาคณิตสลับกัน การแทนค่า string ของ bits โดยธรรมชาติคือการใช้ลูกบาศก์ n มิติ โดยแต่ละ string คือจุดยอด (vertex) ของลูกบาศก์ เมื่อมีภาพนี้และสังเกตว่า error ใน message จะเลื่อน message ไปตามขอบหนึ่งครั้ง, error สองครั้งเลื่อนไปสองครั้ง ฯลฯ ผมก็ค่อยๆ ตระหนักว่าผมกำลังทำงานในปริภูมิ L 1 ระยะทางระหว่างสัญลักษณ์คือจำนวนตำแหน่งที่มันต่างกัน ดังนั้นเราจึงมี metric (การวัดระยะ) ในปริภูมินี้ และมันเป็นไปตามเงื่อนไขมาตรฐานสี่ข้อสำหรับระยะทาง (ดูบทที่ 10 ซึ่งระบุว่านี่คือระยะทาง L 1 มาตรฐาน):
- D ( x , y ) ≥ 0 (ไม่เป็นลบ, non-negativity),
- D ( x , y ) = 0 ก็ต่อเมื่อ x = y (เอกลักษณ์, identity),
- D ( x , y ) = D ( y , x ) (สมมาตร, symmetry)
- D ( x , y ) + D ( y , z ) ≥ D ( x , z ) (อสมการสามเหลี่ยม, triangle inequality).
ดังนั้นผมจึงต้องให้ความสำคัญกับสิ่งที่เคยเรียนมาในฐานะนามธรรมของฟังก์ชันระยะทางของพีทาโกรัส อย่างจริงจัง
เมื่อมีระยะทาง เราสามารถนิยาม sphere (ทรงกลม) ว่าคือจุดทั้งหมด (vertices เพราะในปริภูมิของ vertices มีแค่เท่านั้น) ที่อยู่ห่างจากจุดศูนย์กลางเป็นระยะทางคงที่ ตัวอย่างเช่น ในลูกบาศก์สามมิติซึ่งวาดง่าย Figure 12.3 จุด (0,0,1) , (0,1,0) และ (1,0,0) อยู่ห่างจาก (0,0,0) เป็นระยะทางหนึ่งหน่วย ในขณะที่จุด (1,1,0) , (1,0,1) และ (0,1,1) อยู่ห่างสองหน่วย และสุดท้ายจุด (1,1,1) อยู่ห่างจากจุดกำเนิดสามหน่วย

Figure 12.3—Cube (ลูกบาศก์)
ต่อไปเราไปที่ n มิติ และวาด sphere (ทรงกลม) รัศมีหนึ่งหน่วยรอบแต่ละจุด และ สมมติ ว่า sphere เหล่านี้ไม่ทับซ้อนกัน ชัดเจนว่าถ้าจุดศูนย์กลางของ sphere เหล่านี้คือ code points และมีแค่จุดเหล่านี้เท่านั้น แล้วที่ฝั่งรับ error เดี่ยวใดๆ ใน message จะให้ผลลัพธ์เป็นจุดที่ไม่ใช่ code point และคุณสามารถรู้ได้ว่า error มาจากไหน มันจะอยู่ในทรงกลมรอบจุดที่ผมส่งให้คุณ หรือพูดอีกแบบก็คือ อยู่ใน sphere รัศมี 1 รอบจุดที่คุณได้รับ ดังนั้นเราจึงมีรหัสแก้ไขข้อผิดพลาด ระยะทางต่ำสุดระหว่าง code points คือ 3 ถ้าเราใช้ sphere ที่ไม่ทับซ้อนกันรัศมี 2 ก็จะแก้ไข double error ได้ เพราะจุดที่ได้รับจะอยู่ใกล้ code point ดั้งเดิมมากกว่าจุดอื่นใด การแก้ไข double error ต้องใช้ระยะทางต่ำสุด 5 ตารางต่อไปนี้แสดงความเทียบเท่าระหว่างระยะทางต่ำสุดระหว่าง code points กับความสามารถในการแก้ไข error
| Min. distance (ระยะทางต่ำสุด) | Meaning (ความหมาย) |
|---|---|
| 1 | unique decoding (ถอดรหัสได้ค่าเดียว) |
| 2 | single error detecting (ตรวจจับ error เดี่ยว) |
| 3 | single error correcting (แก้ไข error เดี่ยว) |
| 4 | 1 error correct and 2 error detect (แก้ไข 1 error และตรวจจับ 2 error) |
| 5 | double error correcting (แก้ไข double error) |
| 2 k +1 | k error correction (แก้ไข k error) |
| 2 k +2 | k error correction and k + 1 error detection (แก้ไข k error และตรวจจับ k + 1 error) |
ดังนั้นการหารหัสแก้ไขข้อผิดพลาดก็คือการหา set ของ code points ในปริภูมิ n มิติที่มีระยะทางต่ำสุดตามที่ต้องการระหว่างข้อความที่ถูกต้อง (legal messages) เพราะเงื่อนไขข้างต้นเป็นทั้งเงื่อนไขจำเป็นและเพียงพอ และควรชัดเจนด้วยว่าเราสามารถแลกความสามารถในการแก้ไข error บางส่วนเพื่อเพิ่มความสามารถในการตรวจจับ error ได้อีก ยกเลิกการแก้ไข error หนึ่งครั้ง จะได้การตรวจจับ error เพิ่มอีกสองครั้ง
ผมได้แสดงวิธีออกแบบ code ให้เป็นไปตามเงื่อนไขในกรณีที่ระยะทางต่ำสุดคือ 1 , 2 , 3 หรือ 4 แล้ว รหัสสำหรับระยะทางต่ำสุดที่สูงกว่านั้นไม่ใช่เรื่องง่ายที่จะหา และเราจะไม่ไปไกลกว่านั้นในทิศทางนี้ มันง่ายที่จะให้ upper bound ว่ารหัสที่มีระยะทางสูงกว่านั้นจะมีขนาดใหญ่ได้แค่ไหน ชัดเจนว่าจำนวนจุดใน sphere รัศมี k คือ
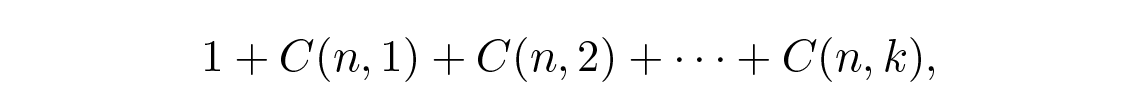
โดยที่ C( n,k ) คือสัมประสิทธิ์ทวินาม (binomial coefficient)
ดังนั้นถ้าเราหารขนาดของปริมาตรของปริภูมิทั้งหมด 2 n ด้วยปริมาตรของ sphere ผลหารจะเป็น upper bound ของจำนวน sphere ที่ไม่ทับซ้อนกัน ซึ่งก็คือ code points ในปริภูมินั้น การเพิ่มความสามารถในการตรวจจับ error ทำได้ง่ายๆ เหมือนก่อนหน้านี้ โดยเพิ่ม overall parity check เข้าไป ซึ่งจะเพิ่มระยะทางต่ำสุดจาก 2 k + 1 เป็น 2 k + 2 (เพราะจุดสองจุดใดๆ ที่มีระยะทางต่ำสุดจะมี overall parity check ที่ตั้งค่าต่างกัน ซึ่งเพิ่มระยะทางต่ำสุดขึ้น 1 )
มาสรุปกันว่าตอนนี้เราอยู่ตรงไหน เราจะเห็นว่าด้วยการออกแบบ code ที่เหมาะสม เราสามารถสร้างระบบจากชิ้นส่วนที่ไม่น่าเชื่อถือ (unreliable parts) และได้เครื่องจักรที่เชื่อถือได้มากกว่ามาก และเราจะเห็นว่าเราต้องจ่ายเท่าไหร่ในแง่ของอุปกรณ์ แม้ว่าเราจะไม่ได้พิจารณาต้นทุนในแง่ความเร็วในการคำนวณถ้าเราสร้างคอมพิวเตอร์ที่มีระดับการแก้ไข error แบบนั้นฝังอยู่ก็ตาม แต่ผมเคยเน้นย้ำถึงข้อดีอีกอย่างมาก่อนแล้ว นั่นคือการบำรุงรักษาในภาคสนาม (field maintenance) และผมอยากพูดถึงมันซ้ำแล้วซ้ำเล่า ยิ่งอุปกรณ์ซับซ้อนมากเท่าไร—และเราก็กำลังมุ่งหน้าไปในทิศทางนั้นอย่างชัดเจน—การบำรุงรักษาในภาคสนามยิ่งมีความสำคัญมากขึ้น และรหัสแก้ไขข้อผิดพลาดไม่เพียงหมายถึงในภาคสนามอุปกรณ์จะให้คำตอบ (ที่อาจจะ) ถูกต้องเท่านั้น แต่มันยังสามารถบำรุงรักษาได้สำเร็จโดยผู้เชี่ยวชาญระดับล่างอีกด้วย
การใช้รหัสตรวจจับและแก้ไขข้อผิดพลาด (error-detecting and error-correcting codes) เพิ่มขึ้นอย่างต่อเนื่องในสังคมของเรา ในการส่งข้อความจากยานอวกาศที่เราส่งไปยังดาวเคราะห์นอกระบบ เรามักมีกำลังส่งเพียง 20 วัตต์หรือน้อยกว่านั้น (อาจต่ำถึง 5 วัตต์) และต้องใช้ codes ที่แก้ไข error ได้หลายร้อยตัวใน block เดียวของข้อความ—แน่นอนว่าการแก้ไขเกิดขึ้นบนโลก เมื่อคุณไม่พร้อมที่จะเอาชนะสัญญาณรบกวน (noise) เช่นในสถานการณ์ข้างต้น หรือในกรณีของ " deliberate jamming" รหัสเหล่านี้เป็นคำตอบเดียวที่รู้จักสำหรับสถานการณ์นั้น
ในช่วงปลายฤดูร้อนปี ค.ศ. 1961 ผมกำลังขับรถข้ามประเทศจาก sabbatical ที่ Stanford, California ไปยัง Bell Telephone Laboratories ในรัฐนิวเจอร์ซีย์ และผมนัดแวะที่ Morris, รัฐอิลลินอยส์ ที่ซึ่งบริษัทโทรศัพท์กำลังติดตั้ง central office แบบอิเล็กทรอนิกส์แห่งแรกที่ไม่ใช่รุ่นทดลอง ผมรู้ว่ามันใช้ Hamming codes อย่างแพร่หลาย และแน่นอน ผมได้รับการต้อนรับเป็นอย่างดี พวกเขาบอกว่าไม่เคยมีการติดตั้งภาคสนามที่ราบรื่นเท่านี้มาก่อน ผมพูดกับตัวเองว่า "แน่นอน นั่นคือสิ่งที่ผมเทศน์สอนมาตลอดสิบปี" เมื่อระหว่างการติดตั้งเริ่มต้น ทุก unit ถูกตั้งค่าและทำงานได้อย่างถูกต้อง (และคุณพอจะรู้ว่ามันทำงานได้เพราะคุณสมบัติการตรวจสอบและแก้ไขตัวเอง) และเมื่อคุณหันหลังให้มันเพื่อไปทำส่วนต่อไป ถ้าหน่วยที่คุณละเลยเกิดข้อบกพร่องขึ้น มันจะบอกคุณ! ความง่ายในการติดตั้งเริ่มต้น รวมถึงการบำรุงรักษาในภายหลัง กำลังถูกพิสูจน์ให้เห็นต่อหน้าต่อตาพวกเขา! ผมพูดได้ไม่ดังพอว่ารหัสแก้ไขข้อผิดพลาดไม่เพียงให้คำตอบที่ถูกต้องเมื่อทำงานเท่านั้น แต่ด้วยการออกแบบที่เหมาะสมมันยังช่วยในการติดตั้งและบำรุงรักษาภาคสนามได้อย่างมาก และยิ่งอุปกรณ์ซับซ้อนมากเท่าไร สองสิ่งนี้ก็ยิ่งจำเป็นมากขึ้นเท่านั้น
ตอนนี้ผมอยากเปลี่ยนไปพูดถึงอีกส่วนของบทนี้ ผมได้เล่ารายละเอียดให้คุณฟังพอสมควรว่าผมเผชิญอะไรบ้างในแต่ละขั้นตอนของการค้นพบรหัสแก้ไขข้อผิดพลาด และผมทำอะไรไปบ้าง ผมทำไปด้วยเหตุผลสองประการ ประการแรก ผมอยากซื่อสัตย์กับคุณและแสดงให้เห็นว่ามันง่ายแค่ไหน ถ้าคุณทำตาม กฎของปาสเตอร์ที่ว่า "โชคเข้าข้างผู้ที่เตรียมพร้อม" การประสบความสำเร็จก็แค่เตรียมตัวเองให้พร้อมที่จะสำเร็จ ใช่ มันมีองค์ประกอบของโชคในการค้นพบนี้ แต่ก็มีคนอื่นอีกมากมายที่อยู่ในสถานการณ์คล้ายๆ กัน และพวกเขาไม่ได้ทำมัน! ทำไมถึงเป็นผม? โชคแน่นอน แต่ผมยังเตรียมตัวเองด้วยการพยายามเข้าใจสิ่งที่เกิดขึ้น—มากกว่าคนอื่นๆ รอบข้างที่แค่ตอบสนองต่อสิ่งที่เกิดขึ้น และไม่ได้คิดอย่างลึกซึ้งถึงสิ่งที่อยู่เบื้องหลังปรากฏการณ์บนพื้นผิว
ผมขอท้าคุณตอนนี้ สิ่งที่ผมเขียนในไม่กี่หน้านี้ทำขึ้นในช่วงประมาณสามถึงหกเดือน โดยส่วนใหญ่ทำงานในช่วงเวลาว่างขณะที่ยังทำงานหลักให้บริษัท (สิทธิ์ในสิทธิบัตรทำให้การตีพิมพ์ล่าช้าไปกว่าหนึ่งปี) ใครกล้าพูดไหมว่าถ้าอยู่ในตำแหน่งของผมแล้วพวกเขาจะทำไม่ได้? ใช่ คุณก็มีความสามารถเท่ากับผมที่จะทำมัน— ถ้า คุณอยู่ที่นั่น และ คุณเตรียมตัวเองให้พร้อมเช่นกัน!
แน่นอนว่าเมื่อคุณดำเนินชีวิต คุณไม่รู้ว่าคุณกำลังเตรียมตัวเพื่ออะไร—แค่คุณต้องการทำสิ่งที่สำคัญ และไม่อยากใช้ชีวิตทั้งชีวิตเป็น "ภารโรงของวิทยาศาสตร์" หรือไม่ว่าคุณจะประกอบอาชีพอะไรก็ตาม แน่นอนว่าโชคมีบทบาทสำคัญ แต่เท่าที่ผมเห็น ชีวิตมอบโอกาสมากมายให้คุณทำสิ่งที่ยิ่งใหญ่ (นิยามตามที่คุณต้องการ) และคนที่เตรียมพร้อมมักจะประสบความสำเร็จหนึ่งครั้งหรือมากกว่า ส่วนคนที่ไม่เตรียมพร้อมจะพลาดแทบทุกครั้ง
ความคิดเห็นข้างต้นไม่ได้มีพื้นฐานมาจากประสบการณ์นี้เพียงอย่างเดียว หรือจากประสบการณ์ของผมเองเท่านั้น มันเป็นผลจากการศึกษาชีวิตของนักวิทยาศาสตร์ผู้ยิ่งใหญ่หลายคน ผมอยากเป็นนักวิทยาศาสตร์ ดังนั้นผมจึงศึกษาพวกเขา และผมมองดูการค้นพบที่เกิดขึ้นในที่ที่ผมอยู่ และถามคำถามกับคนที่ทำการค้นพบเหล่านั้น ความคิดเห็นนี้ยังมีพื้นฐานมาจากสามัญสำนึกอีกด้วย คุณสร้างรูปแบบ (style) การทำสิ่งที่ยิ่งใหญ่ในตัวเอง และเมื่อโอกาสมาถึง คุณก็ตอบสนองด้วยความยิ่งใหญ่ในการกระทำของคุณเกือบจะอัตโนมัติ คุณได้ฝึกฝนตัวเองให้คิดและทำในวิธีที่ถูกต้อง
แต่มีเรื่องน่าเจ็บปวดอย่างหนึ่งที่ต้องกล่าวถึง นั่นคือสิ่งที่ทำให้คุณยิ่งใหญ่ในยุคหนึ่ง ไม่ใช่สิ่งที่จำเป็นในยุคถัดไป ดังนั้นคุณในการเตรียมตัวเพื่อความยิ่งใหญ่ในอนาคต (และความเป็นไปได้ของความยิ่งใหญ่นั้นพบได้ทั่วไปและง่ายกว่าที่คุณคิด เพราะมันไม่ใช่เรื่องธรรมดาที่จะรับรู้ถึงความยิ่งใหญ่เมื่อมันเกิดขึ้นตรงหน้าคุณ) คุณต้องคิดถึงธรรมชาติของอนาคตที่คุณจะอาศัยอยู่ อดีตเป็นแนวทางบางส่วน และสิ่งเดียวที่คุณมีนอกจากประวัติศาสตร์คือการใช้จินตนาการของคุณอย่างสม่ำเสมอ อีกครั้ง การเดินแบบสุ่ม (random walk) ของการตัดสินใจแบบสุ่มจะไม่พาคุณไปไกลเท่ากับการตัดสินใจที่นำพาด้วยวิสัยทัศน์ของคุณเองว่าอนาคตของคุณควรเป็นอย่างไร
ผมได้ทั้งบอกและแสดงให้คุณเห็นแล้วว่าจะยิ่งใหญ่ได้อย่างไร ต่อไปนี้คุณไม่มีข้ออ้างที่จะไม่ทำตาม!