ตัวอย่างของการคำนวณในหนังสือเล่มนี้ล้วนเป็นตัวอย่างขนาดเล็ก ซึ่งดีสำหรับการอธิบายแนวคิดและหลักการ แต่มันสามารถขยายขนาด (scale up) ได้หรือไม่? คำถามเกี่ยวกับความสามารถในการขยายขนาด (scalability) เกิดขึ้นในหลายบริบท
ประการแรก มีคำถามว่าอัลกอริทึมสามารถทำงานกับอินพุตขนาดใหญ่ได้หรือไม่ ปัญหานี้ได้รับการแก้ไขโดยการวิเคราะห์ความซับซ้อนด้านเวลาและพื้นที่ (runtime and space complexity) ของอัลกอริทึม ซึ่งได้กล่าวถึงในส่วนแรกของหนังสือเล่มนี้ โดยเฉพาะใน บทที่ 2 , 4 , 5 , 6 , และ 7 . ในขณะที่อัลกอริทึมบางตัวสามารถขยายขนาดได้ดี (การเดินตามเส้นทาง การชงกาแฟ การค้นหา และการเรียงลำดับ) แต่อัลกอริทึมอื่นๆ ก็ไม่สามารถทำได้ (การปรับOptimizeการเลือกอาหารกลางวันด้วยงบประมาณจำกัด) ดังที่อธิบายไว้ใน บทที่ 7 , เวลาทำงานของอัลกอริทึมแบบ exponential ทำให้ไม่สามารถแก้ปัญหาบางอย่างได้
ประการที่สอง มีคำถามเกี่ยวกับวิธีการสร้าง ทำความเข้าใจ และบำรุงรักษาระบบซอฟต์แวร์ขนาดใหญ่ การออกแบบและเขียนโปรแกรมขนาดเล็กนั้นค่อนข้างง่าย แต่การผลิตระบบซอฟต์แวร์ขนาดใหญ่ยังคงเป็นความท้าทายหลักสำหรับวิศวกรซอฟต์แวร์
เพื่อให้เห็นว่าปัญหาคืออะไร ลองนึกภาพแผนที่ของเมืองหรือประเทศที่คุณอาศัยอยู่ มาตราส่วนเท่าใดจึงจะเหมาะสม? ดังที่ Lewis Carroll อธิบายไว้ในนวนิยายเรื่องสุดท้ายของเขา Sylvie and Bruno Concluded , มาตราส่วนหนึ่งต่อหนึ่งนั้นไร้ประโยชน์ เพราะถ้าแผนที่ถูกคลี่ออก "มันจะคลุมทั้งประเทศและบดบังแสงอาทิตย์!" ดังนั้นแผนที่ที่มีประโยชน์ใดๆ จะต้องมีขนาดเล็กกว่าสิ่งที่มันแสดงเป็นอย่างมาก และด้วยเหตุนี้จึงต้องละเว้นรายละเอียดมากมาย คำถามสำคัญในการสร้างแผนที่คือ มาตราส่วนเท่าใดจึงจะเล็กพอที่จะจัดการได้ แต่ใหญ่พอที่จะแสดงรายละเอียดที่เพียงพอ? ยิ่งไปกว่านั้น รายละเอียดใดควรถูกละเว้นและรายละเอียดใดควรคงไว้? คำตอบสำหรับคำถามหลังมักขึ้นอยู่กับบริบทที่ใช้แผนที่ บางครั้งเราต้องการเห็นถนนและที่จอดรถ ในบางสถานการณ์เราสนใจเส้นทางจักรยานและร้านกาแฟ นั่นหมายความว่าแผนที่ควรปรับแต่งได้ตามความต้องการของแต่ละบุคคล
คำอธิบายใดๆ ที่สั้นกว่าสิ่งที่มันพูดถึงต้องเผชิญกับความท้าทายในการหาระดับ generalization ที่เหมาะสมและจัดหาวิธีการปรับแต่ง คำอธิบายดังกล่าวเรียกว่า abstractions (สิ่งที่เป็นนามธรรม) วิทยาการคอมพิวเตอร์ส่วนใหญ่เกี่ยวข้องกับคำถามเกี่ยวกับวิธีการกำหนดและใช้ abstractions อย่างมีประสิทธิภาพ โดยเฉพาะอย่างยิ่ง อัลกอริทึมคือ abstraction ของการคำนวณที่แตกต่างกันมากมาย และพารามิเตอร์ (parameters) ของมันเป็นตัวกำหนดว่าการคำนวณเฉพาะใดจะเกิดขึ้นเมื่ออัลกอริทึมถูกดำเนินการ อัลกอริทึมจัดการกับ representations (สิ่งที่ใช้แทนข้อมูล) ซึ่งก็เป็น abstractions ที่เก็บรักษารายละเอียดที่จะถูกใช้โดยอัลกอริทึมและละเว้นสิ่งอื่น ระดับของ abstraction ในอัลกอริทึมและอาร์กิวเมนต์ (arguments) ของมันมีความสัมพันธ์กัน การหาระดับทั่วไปที่เหมาะสมสำหรับอัลกอริทึมมักเกี่ยวข้องกับการแลกเปลี่ยน (trade-off) ระหว่างความเป็นทั่วไป (generality) และประสิทธิภาพ (efficiency) การจัดการกับอินพุตที่หลากหลายมากขึ้นมักต้องการระดับ abstraction ที่สูงขึ้นสำหรับอินพุต ซึ่งหมายความว่าอัลกอริทึมมีรายละเอียดให้นำไปใช้น้อยลง
อัลกอริทึมถูกแสดงออกผ่านภาษาและถูกดำเนินการโดยคอมพิวเตอร์ แนวคิดทั้งหมดนี้ก็ใช้ abstractions เช่นกัน และสุดท้าย การทำให้เป็น abstraction จากการคำนวณแต่ละอย่างที่ทำได้โดยอัลกอริทึมก็ต้องการ abstraction สำหรับแนวคิดเรื่องประสิทธิภาพด้านเวลาและพื้นที่เช่นกัน เนื่องจากการระบุลักษณะประสิทธิภาพของอัลกอริทึมอย่างมีประสิทธิผลจำเป็นต้องเป็นอิสระจากขนาดของอินพุตต่างๆ
บทนี้แสดงให้เห็นว่า abstraction แทรกซึมอยู่ในแนวคิดหลักทั้งหมดของวิทยาการคอมพิวเตอร์ อันดับแรก ผมจะพูดถึงประเด็นที่เกิดขึ้นในการกำหนดและใช้ abstractions โดยพิจารณา abstraction สำหรับเรื่องราวที่ใช้ในหนังสือเล่มนี้ จากนั้นผมจะอธิบายว่า abstraction นำไปใช้กับอัลกอริทึม สิ่งที่ใช้แทนข้อมูล เวลาทำงาน คอมพิวเตอร์ และภาษาได้อย่างไร
To Make a Long Story Short (สรุปเรื่องให้สั้น)
มีเรื่องราวหลากหลายที่ถูกกล่าวถึงในหนังสือเล่มนี้: นิทานพื้นบ้าน เรื่องสืบสวน เรื่องผจญภัย แฟนตาซีดนตรี โรแมนติกคอมเมดี้ ตลกวิทยาศาสตร์ และนวนิยายแฟนตาซี แม้ว่าเรื่องราวเหล่านี้จะแตกต่างกันมาก แต่ก็มีหลายสิ่งที่เหมือนกัน ตัวอย่างเช่น ล้วนมีตัวเอกหนึ่งคนหรือมากกว่าที่ต้องเผชิญและเอาชนะความท้าทาย และทั้งหมดมีตอนจบที่มีความสุข เกือบทั้งหมดมีอยู่ในรูปแบบหนังสือ และเกือบทั้งหมดเกี่ยวข้องกับเวทมนตร์หรือพลังเหนือธรรมชาติในรูปแบบใดรูปแบบหนึ่ง ถึงแม้ว่าคำอธิบายสั้นๆ เหล่านี้จะละเว้นรายละเอียดจากแต่ละเรื่อง แต่ก็ยังให้ข้อมูลบางอย่างที่ช่วยแยกแยะเรื่องราวออกจาก รายงานกีฬา เป็นต้น อย่างไรก็ตาม มีการแลกเปลี่ยนที่ชัดเจนระหว่างระดับรายละเอียดที่คำอธิบายเปิดเผยกับจำนวนตัวอย่างที่它可以ใช้ได้ นอกจากนี้ยังดูเหมือนมีการแลกเปลี่ยนระหว่างปริมาณรายละเอียดที่ให้กับเวลาที่ต้องใช้ในการทำความเข้าใจคำอธิบาย เนื่องจากรายละเอียดมากขึ้นนำไปสู่คำอธิบายที่ยาวขึ้น ปัญหานี้สามารถแก้ไขได้โดยการตั้งชื่อสำหรับคำอธิบายเฉพาะ เช่น detective story (เรื่องสืบสวน) ซึ่งตัวเอกเป็นนักสืบที่สืบสวนอาชญากรรม แท็กไลน์ ตัวอย่างหนัง และบทสรุปสั้นๆ อื่นๆ มีความสำคัญเพราะเป็นวิธีที่มีประสิทธิภาพในการส่งมอบข้อมูลที่เกี่ยวข้องเกี่ยวกับสิ่งที่คาดหวังจากเรื่องใดเรื่องหนึ่ง และช่วยให้เราตัดสินใจได้เร็วขึ้น ตัวอย่างเช่น ถ้าคุณไม่ชอบเรื่องสืบสวน คุณก็สามารถคาดการณ์ได้ว่าคุณคงจะไม่สนุกกับการอ่าน The Hound of the Baskervilles.
คุณจะสร้างข้อความสรุปสำหรับกลุ่มเรื่องราวได้อย่างไร? คุณอาจเริ่มต้นด้วยการเปรียบเทียบสองเรื่องและจดจำแง่มุมทั้งหมดที่เหมือนกัน จากนั้นคุณก็เปรียบเทียบผลลัพธ์กับสิ่งที่อยู่ในเรื่องที่สาม และเก็บสิ่งที่ทั้งสามเรื่องมีเหมือนกัน และทำเช่นนี้ต่อไป กระบวนการนี้จะกรองแง่มุมที่ใช้ไม่ได้กับเรื่องใดเรื่องหนึ่งออกทีละขั้น และเก็บแง่มุมที่เหมือนกันทั้งหมดไว้ การกำจัดรายละเอียดที่แตกต่างนี้ออกไปเรียกว่า abstraction (การทำให้เป็นนามธรรม) และบางครั้งก็เรียกว่า "การสกัดจากรายละเอียด" (abstraction from details) 1
ในวิทยาการคอมพิวเตอร์ คำอธิบายที่เป็นผลลัพธ์ของ abstraction ก็เรียกว่า abstraction เช่นกัน และตัวอย่างต่างๆ เรียกว่า instances (อินสแตนซ์) ของ abstraction การใช้ชื่อเดียวกันคือ abstraction สำหรับทั้งกระบวนการและผลลัพธ์อาจทำให้สับสน ทำไมเราไม่ใช้คำที่คล้ายกันอย่าง generalization ล่ะ? ดูเหมือนจะเหมาะสม เพราะ generalization ก็คือบทสรุปที่ตรงกับตัวอย่างเฉพาะจำนวนหนึ่งเช่นกัน อย่างไรก็ตาม คำว่า abstraction ในวิทยาการคอมพิวเตอร์มีความหมายมากกว่า generalization นอกเหนือจากคำอธิบายที่เป็นบทสรุปแล้ว โดยทั่วไปแล้วมันจะมีชื่อและมีพารามิเตอร์หนึ่งตัวหรือมากกว่าที่สามารถระบุด้วยค่าที่เป็นรูปธรรมใน instances ชื่อและพารามิเตอร์เรียกว่า interface (อินเทอร์เฟซ) ของ abstraction interface จัดหากลไกสำหรับการใช้ abstraction และพารามิเตอร์จะเชื่อมโยงองค์ประกอบสำคัญของ instances เข้ากับ abstraction ในขณะที่ generalization ขับเคลื่อนโดย instances เพียงอย่างเดียว ความจำเป็นในการกำหนด interface ทำให้ abstraction เป็นกระบวนการที่ต้องไตร่ตรองมากขึ้น ซึ่งเกี่ยวข้องกับการตัดสินใจว่ารายละเอียดใดควรละเว้น ตัวอย่างเช่น เราสามารถยกระดับ generalization ของเรื่องราว "How protagonists overcome a challenge" (ตัวเอกเอาชนะความท้าทายได้อย่างไร) ให้เป็น story abstraction โดยตั้งชื่อว่า Story และระบุพารามิเตอร์ protagonist และ challenge :
Story( protagonist , challenge ) = How protagonist ( s ) solve(s) the problem of challenge
เช่นเดียวกับพารามิเตอร์ของอัลกอริทึม พารามิเตอร์ของ Story abstraction ถูกใช้ในคำอธิบายเป็นตัวยึดตำแหน่ง (placeholders) ที่จะถูกแทนที่ด้วยอาร์กิวเมนต์ใดก็ตามที่ Story จะถูกนำไปใช้ (การใช้รูปพจน์เอกพจน์/พหูพจน์ใน protagonist (s) และ solve ( s ) มีไว้เพื่อให้คำอธิบายตรงกับทั้งตัวเอกเดี่ยวและหลายคน และการแทนที่ "overcome a" ด้วย "solve(s) the problem of" ทำให้ตัวอย่างต่อไปนี้อ่านง่ายขึ้น)
ในเรื่องของฮันเซลกับเกรเทล ตัวเอกคือฮันเซลและเกรเทล และความท้าทายคือการหาทางกลับบ้าน เราสามารถแสดงข้อเท็จจริงนี้ผ่านการประยุกต์ใช้ Story abstraction กับค่าที่สอดคล้องกันสำหรับพารามิเตอร์:
Story(Hansel and Gretel, finding their way home)
การประยุกต์ใช้นี้หมายถึงเรื่องราวของตัวเอกสองคน คือ ฮันเซลและเกรเทล ที่แก้ปัญหาในการหาทางกลับบ้าน
ควรค่าแก่การไตร่ตรองถึงสิ่งที่เราได้ทำสำเร็จที่นี่ สมมติว่าคุณต้องการอธิบายใจความสำคัญของเรื่องฮันเซลกับเกรเทลให้ใครสักคนฟังอย่างรวดเร็ว คุณสามารถทำได้โดยเริ่มจากการบอกว่ามันเป็นเรื่องราว นั่นคือ การอ้างถึง Story abstraction วิธีนี้จะได้ผลก็ต่อเมื่ออีกฝ่ายรู้ว่าเรื่องราวคืออะไร นั่นคือ ถ้าพวกเขาเข้าใจ Story abstraction ในกรณีนั้น การอ้างถึง abstraction จะทำให้อีกฝ่ายนึกถึงคำอธิบายว่าเรื่องราวคืออะไร จากนั้นคุณก็ให้รายละเอียดเพื่อเติมเต็มบทบาทที่แสดงโดยพารามิเตอร์ protagonist และ challenge ซึ่งเปลี่ยนคำอธิบายทั่วไปของเรื่องราวให้เป็นคำอธิบายที่เฉพาะเจาะจงมากขึ้น
ในทางเทคนิคแล้ว การประยุกต์ใช้ Story abstraction นำไปสู่การแทนที่ชื่อ abstraction ด้วยนิยามของมัน และการแทนที่ค่า "Hansel and Gretel" และ "finding their way home" สำหรับพารามิเตอร์ทั้งสองในนิยาม (ดู บทที่ 2 ) การแทนที่นี้ทำให้เกิด instance ดังต่อไปนี้:
How Hansel and Gretel solve(s) the problem of finding their way home
ความสัมพันธ์ระหว่าง instance และ abstraction แสดงไว้ใน รูปที่ 15.1 .
เมื่อเราได้ให้บทสรุปสำหรับเรื่องราวของฮันเซลกับเกรเทลในรูปของ Story abstraction แล้ว เราอาจต้องการอ้างถึงมันอย่างกระชับยิ่งขึ้นโดยกำหนดชื่อให้มัน ในกรณีนี้ ชื่อของเรื่องบังเอิญเป็นชื่อเดียวกับตัวเอก:
Hansel and Gretel = Story(Hansel and Gretel, finding their way home)
สมการนี้บอกว่าฮันเซลกับเกรเทลคือเรื่องราวของฮันเซลและเกรเทลที่แก้ปัญหาในการหาทางกลับบ้าน การที่ชื่อเรื่องและชื่อตัวเอกตรงกันนั้นเป็นเรื่องบังเอิญล้วนๆ แม้ว่าสิ่งนี้จะเกิดขึ้นบ่อยครั้งก็ตาม นี่คือตัวอย่างที่ไม่เกิดขึ้น:
Groundhog Day = Story(Phil Connors, escaping an endlessly repeating day)
เช่นเดียวกัน instance ที่แสดงโดยการประยุกต์ใช้ abstraction สามารถหาได้โดยการแทนที่ชื่อ abstraction ด้วยนิยามของมัน และแทนที่ค่าลงในพารามิเตอร์:
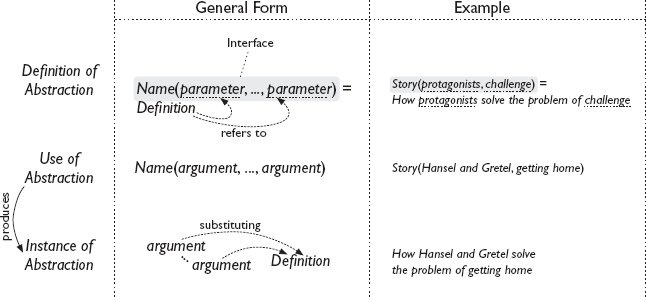
รูปที่ 15.1 นิยามและการใช้ abstractions นิยามของ abstraction กำหนดชื่อให้มันและระบุพารามิเตอร์ที่อ้างถึงโดยนิยามของมัน ชื่อและพารามิเตอร์คือ interface ของ abstraction ซึ่งกำหนดวิธีใช้ abstraction: ผ่านชื่อของมัน และโดยการส่งอาร์กิวเมนต์สำหรับพารามิเตอร์ของมัน การใช้งานดังกล่าวจะสร้าง instance ของ abstraction ซึ่งได้มาจากการแทนที่อาร์กิวเมนต์สำหรับพารามิเตอร์ในนิยามของ abstraction
Groundhog Day = How Phil Connors solve(s) the problem of escaping an endlessly repeating day
ในเรื่องของฮันเซลกับเกรเทล การหาทางกลับบ้านไม่ใช่ความท้าทายเดียวที่พวกเขาเผชิญ อีกส่วนสำคัญของเรื่องคือพวกเขาต้องหนีจากแม่มดที่พยายามจะกินพวกเขา ดังนั้นเรื่องราวจึงสามารถอธิบายได้ด้วยวิธีต่อไปนี้:
Story(Hansel and Gretel, escaping the witch)
คำอธิบายนี้ใช้ Story abstraction เดียวกัน เพียงเปลี่ยนอาร์กิวเมนต์สำหรับพารามิเตอร์ตัวที่สองเท่านั้น ข้อเท็จจริงนี้ทำให้เกิดคำถามหลายข้อเกี่ยวกับ abstractions ประการแรก เราจะจัดการกับความคลุมเครือใน abstractions อย่างไร? เนื่องจากเรื่องของฮันเซลกับเกรเทลสามารถถูกมองว่าเป็น instance ของ Story abstraction ได้ในหลายวิธี และเนื่องจากทั้งสอง instances ที่แสดงให้เห็นต่างก็ให้ข้อมูลที่ถูกต้องเกี่ยวกับเรื่อง จึงไม่อาจกล่าวได้ว่าอันใดอันหนึ่งถูกต้องมากกว่าอันอื่น นี่หมายความว่านิยามของ abstraction มีข้อบกพร่องหรือไม่? ประการที่สอง Story abstraction ไม่เพียงแค่ สกัด (abstract) ออกจากรายละเอียดของความท้าทายเฉพาะหนึ่งเท่านั้น แต่ยัง มุ่งเน้น (focuses) ไปที่ความท้าทายเฉพาะหนึ่งด้วย (อย่างน้อยสำหรับเรื่องราวที่มีหลายความท้าทาย) ตัวอย่างเช่น การอธิบายฮันเซลกับเกรเทลด้วย Story abstraction ทำให้มีความท้าทายอย่างน้อยหนึ่งอย่างที่ไม่ถูกกล่าวถึง ซึ่งทำให้เกิดคำถามว่าเราสามารถนิยาม Story abstraction ให้ครอบคลุมหลายความท้าทายในเรื่องเดียวได้หรือไม่ ซึ่งก็ไม่ยาก แต่ระดับรายละเอียดที่เหมาะสมสำหรับ abstraction ดังกล่าวคืออะไร?
Say When (เมื่อใดจึงจะพอ)
เมื่อใด abstraction จึงจะทั่วไปพอที่จะครอบคลุม instances ได้เพียงพอ? เมื่อใดที่มันละเว้นรายละเอียดมากเกินไปและขาดความแม่นยำ? เมื่อใดก็ตามที่เราสร้าง abstraction เราต้องตัดสินใจว่ามันควรจะทั่วไปแค่ไหนและควรให้รายละเอียดมากน้อยเพียงใด ตัวอย่างเช่น เราสามารถใช้คำอธิบาย "sequence of events" (ลำดับของเหตุการณ์) แทน Story abstraction เพื่อระบุลักษณะของเรื่องราวในหนังสือเล่มนี้ ซึ่งจะแม่นยำ แต่มันจะละเว้นแง่มุมสำคัญบางอย่างและมีความแม่นยำน้อยลง ในทางกลับกัน เราสามารถใช้ abstractions ที่เฉพาะเจาะจงมากขึ้น เช่น "fairy tale" หรือ "comedy" อย่างไรก็ตาม แม้ว่าสิ่งเหล่านี้จะให้รายละเอียดมากกว่า Story abstraction แต่มันก็ไม่ทั่วไปพอที่จะใช้กับทุกเรื่องราว อันที่จริง แม้แต่ Story abstraction ที่ค่อนข้างทั่วไปก็ยังไม่ครอบคลุมถึงเรื่องราวที่ตัวเอกไม่สามารถแก้ปัญหาได้ เราสามารถแก้ไขข้อบกพร่องนี้โดยการเพิ่มพารามิเตอร์อีกตัวที่สามารถแทนที่ด้วย "solve" หรือ "don't solve" ขึ้นอยู่กับสถานการณ์ การทำให้ Story มีลักษณะทั่วไปขึ้นในลักษณะนี้เป็นความคิดที่ดีหรือไม่นั้นขึ้นอยู่กับการใช้งานของ abstraction หากกรณี "don't solve" ไม่เคยเกิดขึ้น ก็ไม่จำเป็นต้องมีความทั่วไปเพิ่มเติม และนิยามที่เรียบง่ายกว่าในปัจจุบันก็ดีกว่า อย่างไรก็ตาม บริบทการใช้งานของ abstractions อาจเปลี่ยนแปลงได้ ดังนั้นเราจึงไม่มีทางมั่นใจได้อย่างสมบูรณ์เกี่ยวกับระดับความทั่วไปที่เลือก
นอกจากหาระดับความทั่วไปที่เหมาะสมแล้ว ปัญหาอีกประการในการกำหนด abstraction คือการตัดสินใจว่าจะให้รายละเอียดในคำอธิบายมากเท่าใดและจะใช้พารามิเตอร์จำนวนเท่าใด ตัวอย่างเช่น เราสามารถเพิ่มพารามิเตอร์ให้กับ Story abstraction ที่สะท้อนว่าความท้าทายถูกเอาชนะโดยตัวเอกได้อย่างไร ในแง่หนึ่ง การเพิ่มพารามิเตอร์ให้กับ abstraction ทำให้มันสื่อความหมายได้มากขึ้น เนื่องจากมันมีกลไกในการเปิดเผยความแตกต่างที่ละเอียดอ่อนระหว่าง instances ที่ต่างกัน ในอีกแง่หนึ่ง มันทำให้ interface ของ abstraction ซับซ้อนขึ้นและต้องการอาร์กิวเมนต์มากขึ้นเมื่อใช้ abstraction interface ที่ซับซ้อนขึ้นไม่เพียงทำให้ abstraction ใช้งานยากขึ้นเท่านั้น แต่ยังทำให้การประยุกต์ใช้ abstraction เข้าใจยากขึ้นด้วย เนื่องจากต้องแทนที่อาร์กิวเมนต์สำหรับพารามิเตอร์ในหลายที่มากขึ้น ซึ่งเป็นการขัดกับเหตุผลหลักประการหนึ่งในการใช้ abstractions นั่นคือการให้บทสรุปที่กระชับและเข้าใจง่าย
การสร้างสมดุลระหว่างความซับซ้อนของ interfaces และความแม่นยำของ abstractions เป็นหนึ่งในปัญหาหลักของวิศวกรรมซอฟต์แวร์ อันที่จริง เราสามารถอธิบายสภาพอันเลวร้ายของโปรแกรมเมอร์ผ่าน instance ของ Story abstraction:
Software Engineering = Story(Programmers, finding the right level of abstraction)
แน่นอนว่ามีความท้าทายอื่นๆ อีกมากมายสำหรับโปรแกรมเมอร์ และบางอย่างก็สามารถสรุปได้อย่างเรียบร้อยโดยใช้ Story abstraction เช่นกัน นี่คืออีกหนึ่งการต่อสู้ที่โปรแกรมเมอร์ทุกคนเห็นใจ:
Correct Software = Story(Programmers, finding and eliminating bugs)
การหาระดับ abstraction ที่เหมาะสมก็เป็นปัญหาสำหรับ Story abstraction เช่นกัน มีสองวิธีที่แตกต่างกันในการกำหนดให้ Hansel and Gretel เป็น instance ของ Story abstraction การเลือก instance ที่มุ่งเน้นไปที่ความท้าทายหนึ่งหมายถึงการสกัด (ละเว้น) อีกความท้าทายหนึ่ง แต่ถ้าเราต้องการให้ทั้งสอง instances ให้คำอธิบายที่ครอบคลุมมากขึ้นของเรื่องฮันเซลกับเกรเทลล่ะ? ซึ่งสามารถทำได้หลายวิธี วิธีแรก เราสามารถกล่าวถึงทั้งสอง instances ควบคู่กัน:
Story(Hansel and Gretel, finding their way home) and
Story(Hansel and Gretel, escaping the witch)
วิธีนี้ดูค่อนข้างเทอะทะ โดยเฉพาะอย่างยิ่ง การกล่าวถึงตัวเอกและ Story abstraction ซ้ำๆ ดูซ้ำซ้อน ซึ่งจะเห็นได้ชัดเมื่อเราทำการแทนที่และสร้าง instance ดังต่อไปนี้:
How Hansel and Gretel solve(s) the problem of finding their way home, and how Hansel and Gretel solve(s) the problem of escaping the witch
อีกทางเลือกหนึ่ง เราสามารถรวมทั้งสองความท้าทายเป็นอาร์กิวเมนต์เดียวสำหรับพารามิเตอร์ challenge :
Story(Hansel and Gretel, finding their way home and escaping the witch)
วิธีนี้ใช้ได้ค่อนข้างดี คุณอาจสังเกตเห็นว่าสิ่งเดียวกันนี้ทำกับตัวเอก: ฮันเซลและเกรเทลถูกจัดกลุ่มเข้าด้วยกันและแทนที่เป็นหน่วยข้อความเดียวสำหรับพารามิเตอร์ protagonist แต่เราก็เห็นได้ว่าความยืดหยุ่นในการใช้ตัวเอกเดี่ยวหรือหลายตัวไม่ได้มาฟรีๆ ในนิยามของ Story abstraction การใช้ protagonist ( s ) และ solve ( s ) ต้องทำงานถูกต้องตามหลักไวยากรณ์ทั้งกับประธานเอกพจน์และพหูพจน์ (เพื่อให้รองรับหลายความท้าทาย ก็ต้องทำเช่นเดียวกันกับ problem ( s )) คงจะดีถ้า Story abstraction สามารถสร้าง instances ที่ถูกต้องตามหลักไวยากรณ์แยกกันสำหรับแต่ละกรณีได้
สิ่งนี้สามารถทำได้โดยการกำหนด Story abstraction ให้พารามิเตอร์ตัวแรกเป็นรายการ (list) ของตัวเอก จากนั้นให้คำจำกัดความที่แตกต่างกันเล็กน้อยสองแบบ ขึ้นอยู่กับว่าพารามิเตอร์เป็นตัวเอกเดี่ยวหรือรายการของสองคน: 2
Story( protagonist , challenge ) = How protagonist solves the problem of challenge
Story( protagonist 1 → protagonist 2 , challenge ) = How protagonist 1 and protagonist 2 solve the problem of challenge
ตอนนี้ถ้า Story ถูกใช้กับตัวเอกเดี่ยว เช่น Phil Connors คำจำกัดความแรกที่ใช้กริยาเอกพจน์จะถูกเลือก ในขณะที่เมื่อ Story ถูกใช้กับรายการของตัวเอกสองคน เช่น Hansel→Gretel คำจำกัดความที่สองที่มีกริยาพหูพจน์จะถูกเลือก ในกรณีนั้น คำจำกัดความที่สองจะแยกรายการออกเป็นสององค์ประกอบและแทรก and ระหว่างพวกมัน
ดูเหมือนว่า Story abstraction จะเป็นเครื่องมือในการสร้างประโยคภาษาอังกฤษ ใน บทที่ 8 ผมได้สาธิตไวยากรณ์ (grammars) ในฐานะกลไกในการทำสิ่งนั้น เราไม่สามารถกำหนดไวยากรณ์สำหรับบทสรุปเรื่องราวแทนได้หรือ? ได้ นี่คือไวยากรณ์หนึ่งที่สอดคล้องกับนิยามล่าสุดของ Story: 3 นอกเหนือจากความแตกต่างด้านสัญกรณ์เล็กน้อย เช่น การใช้ลูกศรแทนเครื่องหมายเท่ากับ หรือการใช้กล่องจุดเพื่อทำเครื่องหมาย nonterminals แทนเส้นประเพื่อทำเครื่องหมายพารามิเตอร์ ทั้งสองกลไกโดยพื้นฐานแล้วทำงานในลักษณะเดียวกัน โดยการแทนที่ค่า (หรือ terminals) สำหรับพารามิเตอร์ (หรือ nonterminals)
story | → | How protagonist solves the problem of challenge |
story | → | How protagonists solve the problem of challenge |
protagonists | → | protagonist and protagonist |
ตาราง 8.1 ใน บทที่ 8 เปรียบเทียบไวยากรณ์ สมการ และอัลกอริทึม มันแสดงบทบาทร่วมของส่วนประกอบต่างๆ ของรูปแบบการเขียนที่แตกต่างกัน และเน้นว่าไวยากรณ์ สมการ และอัลกอริทึมเป็นกลไกที่แตกต่างแต่คล้ายคลึงกันสำหรับการอธิบาย abstractions
การอภิปรายข้างต้นแสดงให้เห็นว่าการออกแบบ abstraction ไม่ใช่เรื่องตรงไปตรงมา เมื่อพบกรณีการใช้งานใหม่ เราอาจรับรู้ถึงความต้องการที่เปลี่ยนแปลงไปซึ่งบังคับให้ต้องเปลี่ยนแปลงนิยามของ abstraction การเปลี่ยนแปลงดังกล่าวสามารถนำไปสู่ abstraction ที่ทั่วไปมากขึ้น หรือนำไปสู่สิ่งที่เปิดเผยรายละเอียดที่แตกต่างกัน ในบางกรณี สิ่งนี้อาจทำให้เกิดการเปลี่ยนแปลงใน interface เช่น เมื่อมีการเพิ่มพารามิเตอร์ใหม่หรือเมื่อประเภทของมันเปลี่ยนไป ตัวอย่างคือการเปลี่ยนแปลงของพารามิเตอร์ protagonist จากค่าเดียวเป็นรายการ เมื่อ interface ของ abstraction เปลี่ยนแปลง การใช้งานที่มีอยู่ทั้งหมดของ abstraction ก็ต้องเปลี่ยนแปลงตามไปด้วยเพื่อให้สอดคล้องกับ interface ใหม่ ซึ่งอาจเป็นงานมากและอาจมีผลกระทบเป็นลูกโซ่ทำให้เกิดการเปลี่ยนแปลงกับ interfaces อื่นๆ เช่นกัน ดังนั้น วิศวกรซอฟต์แวร์จึงพยายามหลีกเลี่ยงการเปลี่ยนแปลง interfaces เมื่อใดก็ตามที่เป็นไปได้ และมักจะพิจารณาให้เป็นทางเลือกสุดท้ายเท่านั้น
A Run of Abstractions (ห้วงของ Abstractions)
พิจารณานิยามสุดท้ายของ Story ที่ใช้รายการของตัวเอก ในขณะที่สมการทำงานเฉพาะกับรายการที่มีหนึ่งหรือสององค์ประกอบ นิยามสามารถขยายให้ทำงานกับรายการที่มีจำนวนองค์ประกอบตามอำเภอใจได้โดยใช้ลูปหรือ recursion ดังที่สาธิตใน บทที่ 10 และ 12 การใช้สมการแยกกันเพื่อแยกความแตกต่างระหว่างกรณีต่างๆ และแนวคิดการประมวลผลรายการ บ่งชี้ว่า Story abstraction อาจเป็นอัลกอริทึมสำหรับสร้างคำอธิบายเรื่องราวสั้นๆ ก็ได้ ปรากฏว่ายังมีอะไรอีกมากมายเกินกว่าที่เห็น และผมจะพูดถึงความสัมพันธ์ระหว่างอัลกอริทึมและ abstractions ในรายละเอียดเพิ่มเติมต่อไป
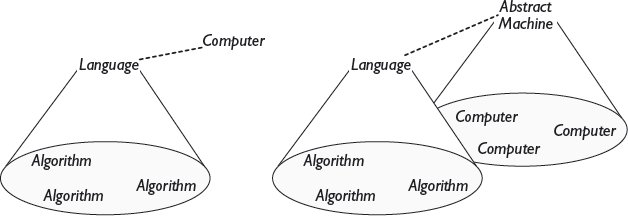
เมื่อพิจารณาถึงความสำคัญของ abstraction ในวิทยาการคอมพิวเตอร์ ก็ไม่น่าแปลกใจที่หนึ่งในแนวคิดหลักของมัน นั่นคือ อัลกอริทึม ก็เป็นตัวอย่างของ abstraction เช่นกัน อัลกอริทึมอธิบายความเหมือนกันของการคำนวณที่คล้ายคลึงกันหลายอย่าง ไม่ว่าจะเป็นการเดินตามก้อนกรวดหรือการเรียงลำดับรายการ ดู รูปที่ 15.2 . 4 ผลลัพธ์การคำนวณที่แตกต่างกันเกิดขึ้นเมื่ออัลกอริทึมถูกดำเนินการด้วยอาร์กิวเมนต์ต่างๆ ที่แทนที่ในพารามิเตอร์ของมัน
Story abstraction ดูเหมือนจะเป็น generalization แบบ post hoc (เกิดขึ้นภายหลัง) กล่าวคือ คำอธิบายสรุปถูกสร้างขึ้นหลังจากได้เห็นเรื่องราวที่มีอยู่มากมายแล้ว ซึ่งอาจเกิดขึ้นกับอัลกอริทึมเป็นบางครั้งเช่นกัน ตัวอย่างเช่น หลังจากที่คุณเตรียมอาหารบางอย่างซ้ำๆ เปลี่ยนส่วนผสมและปรับเปลี่ยนวิธีการเพื่อปรับปรุงผลลัพธ์ ในที่สุดคุณอาจตัดสินใจเขียนสูตรอาหารลงไปเพื่อให้แน่ใจว่าประสบการณ์การทำอาหารสามารถทำซ้ำได้ในอนาคต อย่างไรก็ตาม ในหลายกรณีอื่นๆ อัลกอริทึมคือคำตอบของปัญหาที่ยังไม่ถูกแก้ และถูกสร้างขึ้นก่อนที่จะมีการคำนวณใดๆ เกิดขึ้น และนี่คือสิ่งที่ทำให้ abstraction ของอัลกอริทึมทรงพลังมาก นอกเหนือจากการอธิบายการคำนวณที่เกิดขึ้นแล้ว อัลกอริทึมยังสามารถสร้างการคำนวณใหม่ทั้งหมดตามต้องการได้ อัลกอริทึมมีพลังในการแก้ปัญหาใหม่ที่ไม่เคยพบมาก่อน ในบริบทของ Story abstraction ลองนึกถึงตัวเอกตามอำเภอใจและปัญหาเฉพาะ แล้วคุณก็จะมีจุดเริ่มต้นของเรื่องราวใหม่
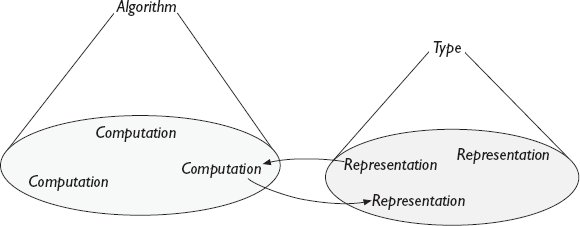
รูปที่ 15.2 อัลกอริทึมคือ abstraction จากการคำนวณแต่ละอย่าง อัลกอริทึมแต่ละตัวเปลี่ยนรูป representations ประเภท (type) ทำให้เป็น abstraction จาก representations แต่ละตัว ถ้า Input คือประเภทของ representations ที่อัลกอริทึมรับ และ Output คือประเภทของ representations ที่อัลกอริทึมสร้างขึ้น แล้วอัลกอริทึมจะมีประเภทเป็น Input → Output.
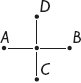
การเปรียบเทียบต่อไปนี้ช่วยอธิบายประเด็นนี้เพิ่มเติม พิจารณาเครือข่ายถนนง่ายๆ และสมมติว่ามีการสร้างถนนสองสายเพื่อเชื่อมต่อเมือง A และ B และ C และ D ตามลำดับ บังเอิญว่าถนนทั้งสองสายตัดกันและมีทางแยกถูกสร้างขึ้นด้วย ทันใดนั้น การเชื่อมต่อใหม่ก็เป็นไปได้ และเราสามารถเดินทางจาก A ไปยัง C จาก B ไปยัง D และอื่นๆ เครือข่ายถนนไม่เพียงอำนวยความสะดวกในการเดินทางที่มันถูกสร้างขึ้นมาเท่านั้น แต่ยังรวมถึงการเดินทางอื่นๆ อีกมากมายที่ไม่ได้คาดการณ์ไว้
การสังเกตว่าอัลกอริทึมคือ abstractions สามารถเข้าใจได้สองวิธี ประการแรก การออกแบบและการใช้อัลกอริทึมได้รับประโยชน์ทั้งหมดของ abstractions แต่ก็ต้องแบกรับต้นทุนทั้งหมดด้วย โดยเฉพาะอย่างยิ่ง ปัญหาการหาระดับ abstraction ที่เหมาะสมนั้นเกี่ยวข้องกับการออกแบบอัลกอริทึม เนื่องจากประสิทธิภาพของอัลกอริทึมมักได้รับผลกระทบจากความเป็นทั่วไปของมัน ตัวอย่างเช่น mergesort ใช้เวลา linearithmic (O(n log n)) Mergesort ทำงานกับรายการองค์ประกอบใดๆ และต้องการเพียงว่าองค์ประกอบต่างๆ สามารถเปรียบเทียบกันได้ ดังนั้นมันจึงเป็นวิธีการเรียงลำดับที่ทั่วไปที่สุดเท่าที่จะจินตนาการได้และสามารถนำไปใช้ได้อย่างกว้างขวาง อย่างไรก็ตาม ถ้าองค์ประกอบของรายการที่จะเรียงลำดับมาจากโดเมนขนาดเล็ก ก็สามารถใช้ bucket sort ได้ (ดู บทที่ 6 ) ซึ่งทำงานเร็วกว่าในเวลาเชิงเส้น (linear time) ดังนั้น นอกจากการแลกเปลี่ยนที่อาจเกิดขึ้นระหว่างความเป็นทั่วไปและความแม่นยำแล้ว อัลกอริทึมยังมีการแลกเปลี่ยนระหว่างความเป็นทั่วไปและประสิทธิภาพอีกด้วย
ประการที่สอง เราสามารถใช้ประโยชน์จากองค์ประกอบของอัลกอริทึมในการออกแบบ abstractions ได้ Story abstraction เป็นตัวอย่างที่ดีของเรื่องนี้ จุดประสงค์เดียวของมันคือเพื่อสร้างคำอธิบายเรื่องราว ไม่ได้มุ่งหมายให้มีการคำนวณใดๆ อย่างไรก็ตาม เนื่องจาก abstraction ที่ออกแบบมาอย่างดีระบุแง่มุมสำคัญของเรื่องราวแต่ละเรื่องผ่านการใช้พารามิเตอร์ เราจึงสังเกตเห็นความจำเป็นในการจัดการกับรายการของตัวเอกและความท้าทายในวิธีที่ยืดหยุ่นมากขึ้น โดยเฉพาะอย่างยิ่ง การแยกความแตกต่างระหว่างรายการที่มีจำนวนองค์ประกอบต่างกันนั้นมีประโยชน์ในการสร้างคำอธิบายเรื่องราวที่เฉพาะเจาะจง
เนื่องจากการดำเนินการของอัลกอริทึมนั้นเทียบเท่ากับพฤติกรรมเชิงฟังก์ชัน (functional behavior) อัลกอริทึมจึงถูกเรียกว่า functional abstractions (สิ่งที่เป็นนามธรรมเชิงฟังก์ชัน) แต่อัลกอริทึมไม่ใช่ตัวอย่างเดียวของ functional abstractions คาถาใน Harry Potter คือ functional abstractions ของเวทมนตร์ เมื่อถูกใช้โดยพ่อมด คาถาจะก่อให้เกิดเวทมนตร์ ทุกครั้งที่ถูกใช้ มันจะก่อให้เกิดผลลัพธ์ที่แตกต่างกัน ขึ้นอยู่กับว่ามันถูกใช้กับใครหรืออะไร และคาถาถูกใช้ได้ดีเพียงใด คล้ายกับอัลกอริทึมซึ่งแสดงในภาษาบางภาษาและสามารถดำเนินการได้โดยคอมพิวเตอร์ที่เข้าใจภาษานั้นเท่านั้น คาถาถูกแสดงในภาษาของเวทมนตร์ ซึ่งรวมถึงการสวดมนต์ การเคลื่อนไม้กายสิทธิ์ และอื่นๆ และมันสามารถใช้ได้โดยพ่อมดผู้ชำนาญที่รู้วิธีใช้คาถานั้นเท่านั้น ยาวิเศษ (Potions) เป็น abstraction ของเวทมนตร์อีกประเภทหนึ่ง พวกมันแตกต่างจากคาถาตรงที่การใช้งานนั้นง่ายกว่ามาก ไม่จำเป็นต้องเป็นพ่อมดเพื่อปลดปล่อยผลของยาวิเศษ ใครก็ได้ แม้แต่มักเกิ้ล ก็สามารถทำได้
เครื่องจักรหลายชนิดก็เป็น functional abstractions เช่นกัน ตัวอย่างเช่น เครื่องคิดเลขพกพาคือ abstraction ของการดำเนินการทางคณิตศาสตร์ เช่นเดียวกับยาวิเศษที่ขยายการเข้าถึงเวทมนตร์ไปไกลกว่าพ่อมด เครื่องคิดเลขก็ขยายการเข้าถึงการคำนวณทางคณิตศาสตร์ไปยังผู้คนที่ไม่มีทักษะที่จำเป็นในการคำนวณ นอกจากนี้ยังสามารถขยายการเข้าถึงโดยการเร่งกระบวนการแม้กระทั่งสำหรับผู้ที่มีทักษะเหล่านั้น ตัวอย่างอื่นๆ ได้แก่ เครื่องชงกาแฟและนาฬิกาปลุก ซึ่งเป็นเครื่องจักรที่สามารถปรับแต่งให้ทำงานเฉพาะได้อย่างน่าเชื่อถือ ประวัติศาสตร์ของยานพาหนะขนส่งแสดงให้เห็นว่าเครื่องจักรช่วยเพิ่มประสิทธิภาพของวิธีการที่ถูกทำให้เป็นนามธรรม (ในกรณีนี้คือการเดินทาง) และบางครั้งก็ทำให้ interface ง่ายขึ้นเพื่อขยายการเข้าถึงไปยังผู้คนมากขึ้น รถม้าต้องใช้ม้าและค่อนข้างช้า รถยนต์เป็นการปรับปรุงครั้งใหญ่แต่ก็ยังต้องมีทักษะการขับขี่ ระบบเกียร์อัตโนมัติ เข็มขัดนิรภัย ระบบนำทาง — ทั้งหมดนี้ทำให้การใช้รถยนต์เป็นวิธีการเดินทางเข้าถึงได้ง่ายขึ้นและปลอดภัยขึ้น เราสามารถคาดหวังการเข้าถึงที่ขยายออกไปอีกในปีต่อๆ ไปกับการมาของรถยนต์ไร้คนขับ
One Type Fits All (ประเภทเดียวครอบคลุมทุกอย่าง)
อัลกอริทึมและเครื่องจักร (และคาถาและยาวิเศษ) เป็นตัวอย่างของ functional abstractions เนื่องจากพวกมันห่อหุ้มฟังก์ชันการทำงานบางรูปแบบไว้ ส่วน representations (สิ่งที่ใช้แทนข้อมูล) แบบพาสซีฟที่ถูกเปลี่ยนรูปในการคำนวณก็อยู่ภายใต้ abstraction เช่นกัน ซึ่งเรียกว่า data abstraction (การทำให้ข้อมูลเป็นนามธรรม) อันที่จริงแล้ว แนวคิดของ representation เป็น abstraction โดยเนื้อแท้ เนื่องจากมันระบุลักษณะบางอย่างของสัญลักษณ์เพื่อใช้แทนบางสิ่ง (ดู บทที่ 3 ) และการทำเช่นนั้นก็ละเว้นลักษณะอื่นๆ อย่างแข็งขัน นั่นคือ มันทำให้เป็นนามธรรมจากลักษณะเหล่านั้น
เมื่อฮันเซลกับเกรเทลหาทางกลับบ้านโดยการวางก้อนกรวด ขนาดและสีของก้อนกรวดไม่สำคัญ การใช้ก้อนกรวดเป็น representation สำหรับตำแหน่งที่ตั้งสร้าง abstraction ที่ละเว้นความแตกต่างในขนาดและสี และมุ่งเน้นไปที่ลักษณะของมันที่สะท้อนแสงจันทร์แทน เมื่อเราบอกว่าแฮร์รี่ พอตเตอร์เป็นพ่อมด เราเน้นย้ำถึงความจริงที่ว่าเขาสามารถใช้เวทมนตร์ได้ ในทางตรงกันข้าม เราไม่สนใจเกี่ยวกับอายุของเขา หรือว่าเขาสวมแว่นตาหรือไม่ หรือข้อมูลที่น่าสนใจอื่นๆ เกี่ยวกับตัวเขา การเรียกแฮร์รี่ พอตเตอร์ว่าพ่อมด เราทำให้เป็นนามธรรมจากรายละเอียดทั้งหมดเหล่านั้น เช่นเดียวกันเมื่อเราชี้ให้เห็นว่าเชอร์ล็อค โฮล์มส์เป็นนักสืบ หรือด็อก บราวน์เป็นนักวิทยาศาสตร์ เราเน้นย้ำลักษณะที่มักเกี่ยวข้องกับคำเหล่านั้น และละเว้นทุกอย่างอื่นเกี่ยวกับบุคคลนั้นชั่วคราว
คำศัพท์เช่น wizard (พ่อมด), detective (นักสืบ) และ scientist (นักวิทยาศาสตร์) ก็คือประเภท (types) พวกมันมีนัยของลักษณะเฉพาะที่โดยทั่วไปคิดว่าเป็นจริงสำหรับสมาชิกแต่ละคนของประเภทนั้น แนวคิดของตัวเอก (protagonist) และความท้าทาย (challenge) ใน Story abstraction ก็เป็น types เช่นกัน เนื่องจากพวกมันกระตุ้นจินตภาพเฉพาะที่จำเป็นสำหรับ Story abstraction ในการสื่อความหมาย ดูเหมือนว่า protagonist เป็น type ที่ทั่วไปกว่า wizard หรือ detective เพราะมันให้รายละเอียดน้อยกว่า ความจริงที่ว่าสองอย่างหลังสามารถแทนที่อย่างแรกได้ก็สนับสนุนมุมมองนี้เช่นกัน แต่นี่เป็นเพียงส่วนหนึ่งของเรื่องเท่านั้น ตัวอย่างเช่น ลอร์ดโวลเดอมอร์ เขาเป็นพ่อมด แต่เขาไม่ใช่ตัวเอก ตรงกันข้าม เขาเป็นศัตรูตัวสำคัญในเรื่อง Harry Potter เนื่องจากทั้งแฮร์รี่ พอตเตอร์ซึ่งเป็นตัวเอก และโวลเดอมอร์ซึ่งเป็นศัตรู ต่างก็เป็นพ่อมด จึงดูเหมือนว่า type wizard จะทั่วไปมากกว่าเพราะมันละเว้นรายละเอียดที่การแยกแยะระหว่างตัวเอกและศัตรูต้องพึ่งพา ดังนั้น ทั้ง protagonist และ wizard จึงไม่สามารถถือว่าเป็นนามธรรมมากกว่าโดยทั่วไป ซึ่งก็ไม่น่าแปลกใจนัก เพราะ types เหล่านี้มาจากโดเมนที่ต่างกัน คือ เรื่องราวและเวทมนตร์
ภายในโดเมนเดียวกัน types มักถูกจัดเรียงอย่างชัดเจนมากขึ้นโดยการวางไว้ในลำดับชั้น (hierarchies) ตัวอย่างเช่น แฮร์รี่ พอตเตอร์, เดรโก มัลฟอย, และเซเวอร์รัส สเนป ล้วนเป็นสมาชิกของฮอกวอตส์ แต่มีเพียงแฮร์รี่และเดรโกเท่านั้นที่เป็นนักเรียนที่ฮอกวอตส์ ถ้าคุณเป็นนักเรียนที่ฮอกวอตส์ คุณก็เป็นสมาชิกของฮอกวอตส์ด้วยอย่างชัดเจน ซึ่งหมายความว่า type member of Hogwarts (สมาชิกของฮอกวอตส์) เป็น abstraction ที่ทั่วไปกว่า student at Hogwarts (นักเรียนที่ฮอกวอตส์) ยิ่งไปกว่านั้น เนื่องจากแฮร์รี่ (แต่ไม่ใช่เดรโก) เป็นสมาชิกของบ้านกริฟฟินดอร์ type student at Hogwarts จึงเป็น abstraction ที่ทั่วไปกว่า student in the house of Gryffindor (นักเรียนในบ้านกริฟฟินดอร์) ในทำนองเดียวกัน เวทมนตร์ (magic) เป็นนามธรรมมากกว่าคาถา ซึ่งในทางกลับกันก็เป็นนามธรรมมากกว่าคาถาเทเลพอร์ตหรือมนต์เสน่ห์ผู้พิทักษ์ (patronus charm)
Types ที่พบในภาษาโปรแกรมมิ่งน่าจะเป็นรูปแบบของ data abstraction ที่ชัดเจนที่สุด เลข 2 และ 6 แตกต่างกัน แต่พวกมันก็มีหลายสิ่งที่เหมือนกัน เราสามารถหารพวกมันด้วย 2 เราสามารถบวกพวกมันกับตัวเลขอื่นๆ และอื่นๆ ดังนั้นเราจึงสามารถละเว้นความแตกต่างของพวกมันและจัดกลุ่มพวกมันร่วมกับตัวเลขอื่นๆ ใน type Number type นี้ทำให้เป็นนามธรรมจากคุณสมบัติของตัวเลขแต่ละตัวและเปิดเผยความเหมือนกันระหว่างสมาชิกทั้งหมด โดยเฉพาะอย่างยิ่ง type สามารถใช้เพื่อระบุลักษณะของพารามิเตอร์ในอัลกอริทึม ซึ่งจากนั้นสามารถนำไปใช้ตรวจสอบความสอดคล้องของอัลกอริทึมกับ type checker ได้ (ดู บทที่ 14 ) ดังนั้น data abstraction จึงไปด้วยกันกับ functional abstraction: อัลกอริทึมทำให้เป็นนามธรรมจากค่าแต่ละค่าโดยใช้พารามิเตอร์ อย่างไรก็ตาม ในหลายกรณี พารามิเตอร์ไม่สามารถแทนที่ด้วยอะไรก็ได้ตามจินตนาการ แต่ต้องการ representations ที่สามารถจัดการโดยอัลกอริทึมเป็นอาร์กิวเมนต์ ตัวอย่างเช่น พารามิเตอร์ที่ถูกคูณด้วย 2 จะต้องเป็นตัวเลข ซึ่งเป็นจุดที่ types ในฐานะ data abstraction เข้ามามีบทบาท type Number ยังถือว่าเป็นนามธรรมมากกว่า types ตัวเลขที่เฉพาะเจาะจงกว่าหลายๆ ชนิด เช่น type ของเลขคู่ทั้งหมด
สุดท้ายนี้ นอกเหนือจาก types (ธรรมดา) เช่น Number แล้ว data abstraction ยังใช้เฉพาะกับ data types ด้วย (ดู บทที่ 4 ) data type ถูกกำหนดโดยการดำเนินการ (operations) ที่มันมีให้และคุณสมบัติของมันเท่านั้น รายละเอียดของ representation ถูกละเว้น นั่นคือ ถูกทำให้เป็นนามธรรม ซึ่งหมายความว่า data type เป็นนามธรรมมากกว่า data structure ที่นำไปใช้งาน ตัวอย่างเช่น stack สามารถถูก implement ได้ด้วย list หรือ array แต่รายละเอียดของโครงสร้างเหล่านั้น และด้วยเหตุนี้ความแตกต่างระหว่างโครงสร้างเหล่านั้นจึงไม่ปรากฏให้เห็นเมื่อพวกมันถูกใช้ในการ implement stacks
data abstraction ที่เลือกมาอย่างดีจะเน้นย้ำลักษณะของ representation ที่สนับสนุนการคำนวณกับพวกมัน ยิ่งไปกว่านั้น abstraction ดังกล่าวจะละเว้นและซ่อนลักษณะที่อาจรบกวนการคำนวณ
Time to Abstract (ถึงเวลาที่จะทำให้เป็นนามธรรม)
ดังที่อธิบายไว้ใน บทที่ 2 , เวลาทำงานของอัลกอริทึมไม่ได้ถูกรายงานในลักษณะเดียวกับที่เครื่องติดตามฟิตเนสรายงานเวลาของการวิ่งหกไมล์ล่าสุดของคุณ การรายงานเวลาทำงานเป็นวินาที (หรือนาทีหรือชั่วโมง) จะไม่ใช่ข้อมูลที่เป็นประโยชน์นัก เนื่องจากมันขึ้นอยู่กับคอมพิวเตอร์เฉพาะเครื่อง เมื่ออัลกอริทึมเดียวกันถูกเรียกใช้บนคอมพิวเตอร์ที่เร็วหรือช้ากว่า เวลาทำงานของอัลกอริทึมเดียวกันก็จะแตกต่างกัน การเปรียบเทียบเวลาของคุณในการวิ่งหกไมล์กับเวลาของเพื่อนนั้นสมเหตุสมผล เนื่องจากมันให้ข้อมูลเกี่ยวกับประสิทธิภาพสัมพัทธ์ของคอมพิวเตอร์สองเครื่อง นั่นคือ นักวิ่งสองคน อย่างไรก็ตาม เวลาไม่ได้บอกอะไรที่มีความหมายเกี่ยวกับประสิทธิภาพของอัลกอริทึมที่กำลังทำงาน เพราะทั้งคุณและเพื่อนของคุณต่างก็กำลังเรียกใช้อัลกอริทึมเดียวกัน
ดังนั้นจึงเป็นความคิดที่ดีที่จะทำให้เป็นนามธรรมจากเวลาที่เป็นรูปธรรม และวัดความซับซ้อนของอัลกอริทึมด้วยจำนวนขั้นตอน (steps) ที่ดำเนินการ การวัดเช่นนี้ไม่ขึ้นอยู่กับความเร็วของคอมพิวเตอร์ และดังนั้นจึงไม่ได้รับผลกระทบจากการพัฒนาเทคโนโลยี สมมติว่าช่วงก้าวของคุณในการวิ่งค่อนข้างคงที่ คุณจะใช้จำนวนก้าวโดยประมาณเท่าเดิมเสมอสำหรับการวิ่งหกไมล์ โดยไม่ขึ้นอยู่กับสถานการณ์เฉพาะ การใช้จำนวนก้าวของช่วงก้าวที่คงที่ทำให้เป็นนามธรรมจากลักษณะเฉพาะของนักวิ่ง และด้วยเหตุนี้จึงให้ลักษณะเฉพาะของการวิ่งที่มั่นคงกว่า อันที่จริง การระบุจำนวนก้าวก็เป็นเพียงวิธีบอกว่าระยะทางวิ่งยาวหกไมล์เท่านั้น ความยาวของการวิ่งเป็นตัววัดความซับซ้อนได้ดีกว่าระยะเวลา เนื่องจากมันทำให้เป็นนามธรรมจากความเร็วที่แตกต่างกันของนักวิ่งต่างๆ หรือแม้แต่นักวิ่งคนเดียวกันในเวลาที่ต่างกัน
อย่างไรก็ตาม จำนวนขั้นตอนหรือการดำเนินการ แม้จะเป็นนามธรรมมากกว่าเวลา แต่ก็ยังเป็นตัววัดความซับซ้อนของอัลกอริทึมที่ยังเป็นรูปธรรมเกินไป เนื่องจากตัวเลขนี้แปรผันตามอินพุตของอัลกอริทึม ตัวอย่างเช่น ยิ่งรายการยาวเท่าไหร่ ก็ยิ่งใช้เวลาในการหาค่าต่ำสุดหรือเรียงลำดับนานขึ้นเท่านั้น ในทำนองเดียวกัน การวิ่งหกไมล์ต้องใช้จำนวนก้าวมากกว่าการวิ่งห้าไมล์ โปรดจำไว้ว่าเป้าหมายคือการระบุลักษณะความซับซ้อนของอัลกอริทึมโดยทั่วไป ไม่ใช่ประสิทธิภาพสำหรับอินพุตเฉพาะ ดังนั้นจึงไม่ชัดเจนว่าสำหรับอินพุตใดที่เราควรรายงานจำนวนขั้นตอน เราสามารถสร้างตารางแสดงจำนวนขั้นตอนสำหรับหลายๆ กรณีตัวอย่างได้ แต่ก็ไม่ชัดเจนว่าควรเลือกตัวอย่างใด
ดังนั้น การทำให้เวลาเป็นนามธรรม (time abstraction) สำหรับอัลกอริทึมจึงไปไกลกว่านั้นและละเว้นจำนวนขั้นตอนที่เกิดขึ้นจริง แต่รายงานว่าจำนวนขั้นตอนเพิ่มขึ้นอย่างไรเมื่ออินพุตใหญ่ขึ้น ตัวอย่างเช่น ถ้าอัลกอริทึมต้องการจำนวนขั้นตอนเป็นสองเท่าเมื่อขนาดของอินพุตเพิ่มขึ้นเป็นสองเท่า มันก็เติบโตในอัตราเดียวกัน ดังที่อธิบายไว้ใน บทที่ 2 , พฤติกรรมเวลาทำงานเช่นนี้เรียกว่า เชิงเส้น (linear) ซึ่งเป็นสิ่งที่เกิดขึ้นกับการหาค่าต่ำสุดของรายการหรือกับการวิ่ง 5 แม้ว่าเวลาทำงานจะเติบโตด้วยปัจจัยที่สูงกว่า 2 ความซับซ้อนของอัลกอริทึมก็ยังถือว่าเป็นเชิงเส้น เนื่องจากความสัมพันธ์ระหว่างขนาดของอินพุตและจำนวนขั้นตอนที่ดำเนินการแสดงออกโดยการคูณด้วยค่าคงที่ (constant factor) นี่เป็นกรณีของจำนวนขั้นตอนที่ฮันเซลกับเกรเทลใช้ในการหาทางกลับบ้าน เวลาทำงานเติบโตในอัตราที่มากกว่า 2 เนื่องจากก้อนกรวดถูกวางกระจายห่างกันหลายก้าว หมวดหมู่เวลาทำงานของอัลกอริทึมเชิงเส้นทำให้เป็นนามธรรมจากปัจจัยนี้เช่นกัน และดังนั้นอัลกอริทึมของฮันเซลกับเกรเทลจึงยังคงถือว่าเป็นเชิงเส้น
ประโยชน์ที่สำคัญที่สุดสองประการของ time abstraction คือความสามารถในการบอกเราว่าปัญหาใดสามารถแก้ไขได้ (tractable) และควรเลือกอัลกอริทึมใดสำหรับปัญหาเฉพาะ ตัวอย่างเช่น อัลกอริทึมที่มีเวลาทำงานแบบ exponential ทำงานได้เฉพาะกับอินพุตที่เล็กมากเท่านั้น และปัญหาที่รู้จักเฉพาะอัลกอริทึมแบบ exponential จึงถือว่าแก้ไม่ได้ (intractable) (ดู บทที่ 7 ) ในทางกลับกัน ถ้าเรามีอัลกอริทึมหลายตัวให้เลือกใช้เพื่อแก้ปัญหาเดียวกัน เราควรเลือกตัวที่มีความซับซ้อนด้านเวลาทำงานที่ดีกว่า ตัวอย่างเช่น โดยทั่วไปเราจะเลือก mergesort แบบ linearithmic มากกว่า insertion sort แบบ quadratic (ดู บทที่ 6 ) รูปที่ 15.3 สรุป time abstraction
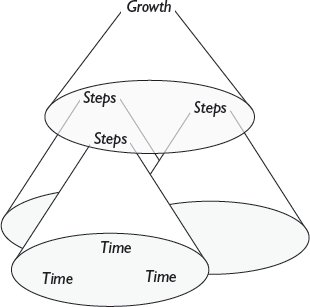
รูปที่ 15.3 Time abstraction (การทำให้เวลาเป็นนามธรรม) เพื่อทำให้เป็นนามธรรมจากความเร็วที่แตกต่างกันของคอมพิวเตอร์ เราใช้จำนวนขั้นตอนที่อัลกอริทึมต้องการระหว่างการดำเนินการเป็นตัววัดเวลาทำงานของมัน เพื่อทำให้เป็นนามธรรมจากจำนวนขั้นตอนที่แตกต่างกันที่จำเป็นสำหรับอินพุตที่แตกต่างกัน เราวัดเวลาทำงานของอัลกอริทึมในแง่ของความเร็วที่มันเติบโตสำหรับอินพุตที่ใหญ่ขึ้น
The Language in the Machine (ภาษาในเครื่องจักร)
อัลกอริทึมไม่สามารถสร้างการคำนวณได้ด้วยตัวเอง ดังที่อธิบายไว้ใน บทที่ 2 , อัลกอริทึมต้องถูกดำเนินการโดยคอมพิวเตอร์ที่เข้าใจภาษาที่อัลกอริทึมเขียนขึ้น คำสั่งทุกคำที่ใช้ในอัลกอริทึมต้องอยู่ในชุดคำสั่ง (repertoire) ที่คอมพิวเตอร์สามารถประมวลผลได้
การผูกโยงอัลกอริทึมกับคอมพิวเตอร์เฉพาะผ่านภาษาเป็นปัญหาด้วยหลายสาเหตุ ประการแรก คอมพิวเตอร์ที่ออกแบบอย่างอิสระกันมักจะเข้าใจภาษาที่แตกต่างกัน ซึ่งหมายความว่าอัลกอริทึมที่เขียนด้วยภาษาที่คอมพิวเตอร์เครื่องหนึ่งเข้าใจและดำเนินการได้ อาจไม่ถูกเข้าใจและดำเนินการโดยอีกเครื่องหนึ่ง ตัวอย่างเช่น ถ้าฮันเซลหรือเกรเทลใช้ภาษาเยอรมันในการเขียนอัลกอริทึมสำหรับการหาทางกลับบ้านโดยใช้ก้อนกรวด เด็กที่เติบโตในฝรั่งเศสหรืออังกฤษก็ไม่สามารถดำเนินการตามได้หากไม่ได้รับการสอนภาษาเยอรมัน ประการที่สอง เมื่อเวลาผ่านไป ภาษาที่คอมพิวเตอร์ใช้ก็เปลี่ยนแปลง ซึ่งอาจไม่ใช่ปัญหาสำหรับมนุษย์ที่ยังคงสามารถเข้าใจรูปแบบภาษาที่เก่าและล้าสมัยได้อย่างน่าเชื่อถือ แต่มันเป็นปัญหาสำหรับเครื่องจักรอย่างแน่นอน ซึ่งอาจไม่สามารถดำเนินการอัลกอริทึมได้เลยหากแม้แต่คำสั่งเดียวถูกเปลี่ยนแปลงเล็กน้อย การผูกโยงระหว่างภาษาของอัลกอริทึมและคอมพิวเตอร์ที่เปราะบางนี้ดูเหมือนจะทำให้การแบ่งปันอัลกอริทึมเป็นเรื่องยาก โชคดีที่ซอฟต์แวร์ไม่จำเป็นต้องถูกเขียนใหม่ทุกครั้งที่มีคอมพิวเตอร์เครื่องใหม่เข้าสู่ตลาด abstraction สองรูปแบบสามารถให้เครดิตสำหรับสิ่งนี้: language translation (การแปลภาษา) และ abstract machines (เครื่องจักรนามธรรม).
เพื่ออธิบายแนวคิดของ abstract machine ลองพิจารณาอัลกอริทึมสำหรับการขับรถ คุณอาจเคยเรียนรู้วิธีขับรถรุ่นหนึ่ง แต่คุณก็ยังสามารถขับรถได้หลากหลายรุ่น ทักษะการขับรถที่คุณได้รับไม่ได้ผูกติดกับรุ่นและยี่ห้อเฉพาะ แต่เป็นนามธรรมมากกว่า และสามารถอธิบายได้โดยใช้แนวคิด เช่น พวงมาลัย คันเร่ง และเบรก แบบจำลองรถยนต์นามธรรม (abstract car model) ถูกรับรู้โดยรถยนต์จริงต่างๆ ที่แตกต่างกันในรายละเอียด แต่ให้การเข้าถึงฟังก์ชันการทำงานของมันโดยใช้ภาษาทั่วไปของการขับรถ
Abstraction ใช้ได้กับเครื่องจักรทุกประเภท ตัวอย่างเช่น เราสามารถทำให้เป็นนามธรรมจากรายละเอียดของเครื่องชงกาแฟ แฟรนช์เพรส หรือเอสเพรสโซ่แมชชีน โดยกล่าวว่าเครื่องจักรสำหรับทำกาแฟต้องการความสามารถในการผสมน้ำร้อนกับผงกาแฟเป็นระยะเวลาหนึ่ง จากนั้นแยกอนุภาคออกจากของเหลว อัลกอริทึมสำหรับการทำกาแฟสามารถอธิบายได้ในรูปของ coffee-making abstraction นี้ ซึ่งยังคงเป็นรูปธรรมพอที่จะถูก instantiate ด้วยเครื่องทำกาแฟที่แตกต่างกัน แน่นอนว่า machine abstraction มีข้อจำกัดของมัน เราไม่สามารถใช้เครื่องชงกาแฟเพื่อดำเนินการอัลกอริทึมการขับรถ และเราไม่สามารถทำกาแฟโดยใช้รถยนต์ ถึงกระนั้น abstract machines ก็เป็นวิธีสำคัญในการแยกภาษาออกจากสถาปัตยกรรมคอมพิวเตอร์เฉพาะ (ดู รูปที่ 15.4 )
abstract machine ที่มีชื่อเสียงที่สุดสำหรับการคำนวณคือ Turing machine (เครื่องจักรทัวริง) ซึ่งตั้งชื่อตามนักคณิตศาสตร์และผู้บุกเบิกวิทยาการคอมพิวเตอร์ชาวอังกฤษผู้โด่งดัง Alan Turing ผู้คิดค้นมันขึ้นในปี ค.ศ. 1936 และใช้มันเพื่อทำให้แนวคิดของการคำนวณและอัลกอริทึมเป็นทางการ Turing machine ประกอบด้วยเทปที่แบ่งออกเป็นเซลล์ แต่ละเซลล์มีสัญลักษณ์ เทปถูกเข้าถึงผ่านหัวอ่าน/เขียนที่สามารถเคลื่อนเทปไปข้างหน้าและข้างหลังได้ เครื่องจักรจะอยู่ในสถานะ (state) ใดสถานะหนึ่งเสมอและถูกควบคุมโดยโปรแกรม ซึ่งกำหนดโดยชุดของกฎที่บอกว่าควรเขียนสัญลักษณ์ใดบนเซลล์ปัจจุบันของเทป ควรเคลื่อนเทปไปในทิศทางใด และควรเปลี่ยนไปอยู่ในสถานะใหม่ใด ขึ้นอยู่กับสัญลักษณ์ที่มองเห็นได้ในขณะนั้นและสถานะปัจจุบันคืออะไร Turing machine ถูกใช้เพื่อพิสูจน์ความไม่สามารถแก้ได้ (unsolvability) ของปัญหาการหยุดทำงาน (halting problem) (ดู บทที่ 11 ) โปรแกรมใดๆ สามารถแปลเป็นโปรแกรม Turing machine ได้ ซึ่งหมายความว่า Turing machine คือ abstraction ของคอมพิวเตอร์ (อิเล็กทรอนิกส์) ที่มีอยู่ในปัจจุบันทั้งหมด ความสำคัญของข้อมูลเชิงลึกนี้คือ ไม่ว่าคุณสมบัติทั่วไปใดๆ ที่เราสามารถพิสูจน์ได้สำหรับ Turing machine ก็จะเป็นจริงสำหรับคอมพิวเตอร์อื่นๆ ที่มีอยู่ด้วยเช่นกัน
กลยุทธ์อีกประการหนึ่งสำหรับการทำให้เป็นนามธรรมจากคอมพิวเตอร์เฉพาะคือการใช้การแปลภาษา (language translation) ตัวอย่างเช่น เราสามารถแปลอัลกอริทึมการวางก้อนกรวดจากภาษาเยอรมันเป็นฝรั่งเศสหรืออังกฤษ ซึ่งช่วยขจัดอุปสรรคด้านภาษาและทำให้อัลกอริทึมเข้าถึงได้สำหรับผู้คนที่หลากหลายมากขึ้น แน่นอนว่าสิ่งเดียวกันนี้ใช้ได้กับภาษาคอมพิวเตอร์ อันที่จริงแล้ว โปรแกรมเกือบทั้งหมดที่เขียนในปัจจุบันถูกแปลในบางรูปแบบก่อนที่จะถูกดำเนินการโดยเครื่องจักร ซึ่งหมายความว่าแทบไม่มีภาษาโปรแกรมมิ่งใดๆ ที่ใช้ในปัจจุบันที่คอมพิวเตอร์เข้าใจโดยตรง และอัลกอริทึมทุกตัวต้องถูกแปล ภาษาโปรแกรมมิ่งทำให้เป็นนามธรรมจากรายละเอียดของคอมพิวเตอร์เฉพาะ และให้การเข้าถึงที่เป็นหนึ่งเดียวสำหรับการเขียนโปรแกรมบนคอมพิวเตอร์หลากหลายประเภทด้วยภาษาเดียว ภาษาโปรแกรมมิ่งจึงเป็น abstraction ของคอมพิวเตอร์ และทำให้การออกแบบอัลกอริทึมเป็นอิสระจากคอมพิวเตอร์เฉพาะ ถ้าคอมพิวเตอร์ใหม่ถูกผลิตขึ้น สิ่งที่ต้องทำเพื่อให้รันอัลกอริทึมที่มีอยู่บนคอมพิวเตอร์ใหม่นี้ก็คือการปรับ translator เพื่อสร้างโค้ดที่เปลี่ยนไปสำหรับคอมพิวเตอร์นั้น abstraction ของการแปลทำให้การออกแบบภาษาโปรแกรมมิ่งเป็นอิสระจากคอมพิวเตอร์ที่จะรันภาษาเหล่านั้นในระดับสูง
รูปที่ 15.4 abstract machine คือ abstraction จากคอมพิวเตอร์ที่เป็นรูปธรรม การให้ interface ที่เรียบง่ายและทั่วไปมากขึ้น abstract machine ทำให้ภาษาเชิงอัลกอริทึมเป็นอิสระจากสถาปัตยกรรมคอมพิวเตอร์เฉพาะ และขยายช่วงของคอมพิวเตอร์ที่สามารถดำเนินการภาษาเหล่านั้นได้
มีหลายวิธีในการกำหนด Translate abstraction เช่นเดียวกับ abstraction อื่นๆ คำถามคือรายละเอียดใดที่จะทำให้เป็นนามธรรมและรายละเอียดใดที่จะเปิดเผยเป็นพารามิเตอร์ใน interface นิยามต่อไปนี้ทำให้เป็นนามธรรมจากโปรแกรมที่จะแปล ภาษาต้นทางที่โปรแกรมถูกเขียนในนั้น และภาษาเป้าหมายที่ควรจะแปลเป็น:
Translate( program , source , target ) = "Translate program from source into target "
สังเกตว่าผมใช้เครื่องหมายคำพูดล้อมรอบ " Translate … " เพราะการแปลเป็นอัลกอริทึมที่ซับซ้อน ยาวและซับซ้อนเกินกว่าจะนำเสนอที่นี่ ตัวอย่างเช่น การแปลภาษาธรรมชาติโดยอัตโนมัติยังคงเป็นปัญหาที่ยังไม่ได้รับการแก้ไข ในทางตรงกันข้าม การแปลภาษาคอมพิวเตอร์เป็นปัญหาที่เข้าใจและแก้ไขได้ดีแล้ว ถึงกระนั้น translators ก็เป็นอัลกอริทึมที่ยาวและซับซ้อน ซึ่งเป็นเหตุผลที่ไม่แสดงรายละเอียดที่นี่
เป็นตัวอย่างวิธีใช้ Translate abstraction นี่คือวิธีการแปลคำสั่งเพื่อหาก้อนกรวดจากภาษาเยอรมันเป็นอังกฤษ:
Translate(Finde Kieselstein, German, English)
คำสั่ง Finde Kieselstein เป็นองค์ประกอบของภาษาต้นทางคือภาษาเยอรมัน และผลลัพธ์ของการแปลคือคำสั่ง Find pebble ซึ่งเป็นองค์ประกอบของภาษาเป้าหมายคือภาษาอังกฤษ
ใน Harry Potter ภาษาของคาถาและมนต์เสน่ห์ต้องใช้พ่อมดในการดำเนินการ คาถาบางอย่างสามารถแปลเป็นยาวิเศษที่สอดคล้องกัน ซึ่งจากนั้นสามารถดำเนินการได้โดยมักเกิ้ลเช่นกัน ตัวอย่างเช่น ผลของคาถาแปลงร่างบางอย่างสามารถถูกบันทึกไว้ใน Polyjuice Potion ซึ่งช่วยให้ผู้ดื่มเปลี่ยนรูปลักษณ์ของตนเองได้ ในขณะที่ Polyjuice Potion นั้นยากที่จะผลิต แม้กระทั่งสำหรับพ่อมดที่มีประสบการณ์ คาถาอื่นๆ บางอย่างก็มีการแปลที่ตรงไปตรงมา ตัวอย่างเช่น คำสาปสังหาร Avada Kedavra แปลเป็นยาพิษร้ายแรงทั่วไป
เนื่องจาก Translate abstraction ทุกตัวเป็นอัลกอริทึมด้วยตัวของมันเอง เราจึงสามารถทำให้เป็นนามธรรมจากการแปลทั้งหมดผ่านภาษาที่สามารถแสดงออกได้ เช่นเดียวกับที่เราทำให้เป็นนามธรรมจากอัลกอริทึมทั้งหมดโดยใช้ภาษา ส่วนบนซ้ายของ รูปที่ 15.5 แสดงกรณีนี้ เนื่องจากทุกภาษาสอดคล้องกับคอมพิวเตอร์หรือ abstract machine ที่สามารถดำเนินการโปรแกรมในภาษานั้นได้ นั่นหมายความว่าภาษาสามารถทำให้เป็นนามธรรมจากคอมพิวเตอร์ได้ ดังที่แสดงในส่วนบนขวาของ รูปที่ 15.5 .
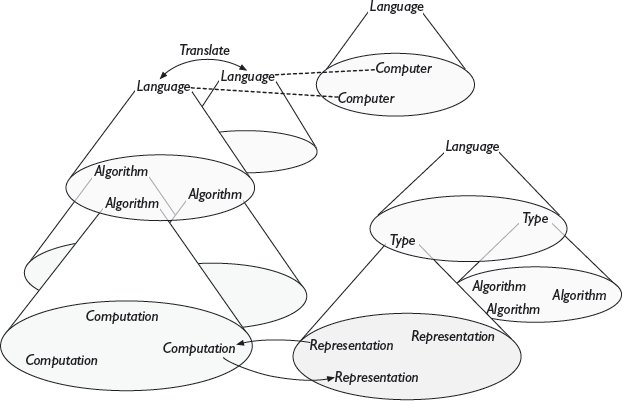
รูปที่ 15.5 หอคอยแห่ง abstractions (The tower of abstractions) อัลกอริทึมคือ (functional) abstraction จากการคำนวณ อัลกอริทึมเปลี่ยนรูป representations ซึ่ง (data) abstractions ของมันคือ types อินพุตและเอาต์พุตที่ยอมรับได้สำหรับอัลกอริทึมก็แสดงเป็น types เช่นกัน อัลกอริทึมแต่ละตัวถูกแสดงในภาษา ซึ่งเป็น abstraction จากอัลกอริทึม อัลกอริทึมการแปลสามารถเปลี่ยนรูปอัลกอริทึมจากภาษาหนึ่งไปยังอีกภาษาหนึ่ง และดังนั้นทำให้อัลกอริทึมเป็นอิสระจากคอมพิวเตอร์เฉพาะหรือ abstract machine ที่เข้าใจภาษาที่มันถูกเขียนขึ้น ภาษายังเป็น abstraction ของคอมพิวเตอร์ เนื่องจากการแปลสามารถกำจัดความแตกต่างระหว่างคอมพิวเตอร์ได้อย่างมีประสิทธิภาพ Types ก็ถูกแสดงเป็นส่วนหนึ่งของภาษา ลำดับชั้นของ abstraction แสดงให้เห็นว่า abstractions ทั้งหมดในวิทยาการคอมพิวเตอร์ถูกแสดงในภาษาบางภาษา
เช่นเดียวกับที่ Turing machine เป็น abstraction สูงสุดของเครื่องจักรคำนวณใดๆ lambda calculus (แคลคูลัสแลมบ์ดา) ก็เป็น abstraction สูงสุดของภาษาโปรแกรมมิ่งใดๆ Lambda calculus ถูกประดิษฐ์ขึ้นในช่วงเวลาเดียวกับ Turing machine โดยนักคณิตศาสตร์ชาวอเมริกัน Alonzo Church มันประกอบด้วยโครงสร้างเพียงสามแบบสำหรับการกำหนด abstractions การอ้างอิงพารามิเตอร์ในนิยาม และการสร้าง instances ของ abstractions โดยการส่งอาร์กิวเมนต์ให้พารามิเตอร์ ซึ่งคล้ายกับที่แสดงใน รูปที่ 15.1 มาก โปรแกรมใดๆ ในภาษาเชิงอัลกอริทึมใดๆ สามารถแปลเป็นโปรแกรม lambda calculus ได้ ตอนนี้ดูเหมือนว่าเรามี abstractions สูงสุดสองแบบที่แตกต่างกันจากคอมพิวเตอร์: lambda calculus และ Turing machine เป็นไปได้อย่างไร? ปรากฏว่า abstractions ทั้งสองนี้เทียบเท่ากัน ซึ่งหมายความว่าโปรแกรมใดๆ สำหรับ Turing machine สามารถแปลเป็นโปรแกรม lambda calculus ที่เทียบเท่าได้ และในทางกลับกัน ยิ่งไปกว่านั้น ทุกรูปแบบการเขียน (formalism) ที่รู้จักสำหรับการแสดงอัลกอริทึม 6 ได้รับการพิสูจน์แล้วว่ามีความสามารถในการแสดงออกไม่มากไปกว่า Turing machines หรือ lambda calculus ดังนั้น ดูเหมือนว่าอัลกอริทึมใดๆ สามารถแสดงเป็น Turing machine หรือโปรแกรม lambda calculus ได้ การสังเกตนี้เป็นที่รู้จักในชื่อ Church-Turing thesis (วิทยานิพนธ์เชิร์ช-ทัวริง) ซึ่งตั้งชื่อตามผู้บุกเบิกวิทยาการคอมพิวเตอร์ทั้งสองคน Church-Turing thesis เกี่ยวข้องกับการแสดงออกและการเข้าถึงของอัลกอริทึม เนื่องจากนิยามของอัลกอริทึมมีพื้นฐานอยู่บนแนวคิดของคำสั่งที่มีประสิทธิผล (effective instruction) ซึ่งเป็นแนวคิดที่เข้าใจได้โดยสัญชาตญาณ tied กับความสามารถของมนุษย์ อัลกอริทึมจึงไม่สามารถทำให้เป็นทางการทางคณิตศาสตร์ได้ Church-Turing thesis ไม่ใช่ทฤษฎีบทที่สามารถพิสูจน์ได้ แต่เป็นการสังเกตเกี่ยวกับแนวคิดโดยสัญชาตญาณของอัลกอริทึม Church-Turing thesis มีความสำคัญมากเพราะมันหมายความว่าทุกสิ่งที่สามารถรู้ได้เกี่ยวกับอัลกอริทึมสามารถค้นพบได้โดยการศึกษา Turing machines และ lambda calculus Church-Turing thesis เป็นที่ยอมรับโดยนักวิทยาการคอมพิวเตอร์ส่วนใหญ่

การคำนวณถูกใช้สำหรับการแก้ปัญหาอย่างเป็นระบบ แม้ว่าคอมพิวเตอร์อิเล็กทรอนิกส์จะอำนวยความสะดวกในการเติบโตและการเข้าถึงของการคำนวณอย่างที่ไม่เคยมีมาก่อน แต่มันก็เป็นเพียงเครื่องมือหนึ่งของการคำนวณเท่านั้น แนวคิดของการคำนวณเป็นทั่วไปและสามารถประยุกต์ใช้ได้กว้างขวางกว่า ดังที่เราได้เห็น ฮันเซลและเกรเทลรู้วิธีดำเนินการอัลกอริทึมและรู้วิธีใช้ abstractions ในการแทนที่เส้นทางผ่านก้อนกรวดได้สำเร็จ เชอร์ล็อค โฮล์มส์เป็นผู้เชี่ยวชาญด้านสัญลักษณ์และสิ่งที่ใช้แทนข้อมูล และเขาจัดการ data structures เพื่อแก้ปัญหาอาชญากรรม และอินเดียน่า โจนส์ไม่ได้ใช้คอมพิวเตอร์อิเล็กทรอนิกส์ในการค้นหาที่น่าตื่นเต้นของเขาเลย ภาษาของดนตรีอาจไม่ได้แก้ปัญหาใดๆ โดยตรง แต่มันก็มีไวยากรณ์และความหมาย (semantics) ครบถ้วนเท่าที่คุณจะจินตนาการได้ ฟิล คอนเนอร์สอาจไม่รู้จักวิทยาการคอมพิวเตอร์เชิงทฤษฎีใดๆ แต่เขาก็เผชิญกับปัญหาเดียวกันที่แสดงให้เห็นถึงข้อจำกัดพื้นฐานของการคำนวณ: ความไม่สามารถแก้ได้ของปัญหาการหยุดทำงาน (unsolvability of the halting problem) มาร์ตี้ แม็คฟลายและด็อก บราวน์ใช้ชีวิตกับ recursion และแฮร์รี่ พอตเตอร์เปิดเผยให้เราเห็นถึงพลังวิเศษของ types และ abstraction
วีรบุรุษของเรื่องราวเหล่านี้อาจไม่ใช่วีรบุรุษของการคำนวณ แต่เรื่องราวของพวกเขาได้บอกเราเกี่ยวกับสิ่งที่การคำนวณเป็นมากมาย เมื่อหนังสือเล่มนี้จบลง ผมอยากจะฝากเรื่องราวอีกเรื่องหนึ่งไว้กับคุณ— เรื่องราวของวิทยาการคอมพิวเตอร์ (the story of computer science) นี่คือเรื่องราวเกี่ยวกับ abstractions สำหรับการพิชิตแนวคิดของการคำนวณ ตัวเอกหลักของมันคือ อัลกอริทึม (algorithm) ซึ่งสามารถแก้ ปัญหา (problems) อย่างเป็นระบบผ่านการเปลี่ยนรูปของ สิ่งที่ใช้แทนข้อมูล (representations) มันทำเช่นนั้นโดยการใช้เครื่องมือพื้นฐานของมันอย่างชำนาญ นั่นคือ โครงสร้างควบคุม (control structures) และ recursion แม้ว่าปัญหาสามารถแก้ไขได้หลายวิธี แต่อัลกอริทึมก็ไม่ยอมจำนนต่อวิธีแก้ปัญหาเฉพาะใดๆ แต่มุ่งมั่นที่จะเป็นทั่วไปมากที่สุดเท่าที่จะเป็นไปได้โดยใช้อาวุธลับของมัน นั่นคือ พารามิเตอร์ (parameter) อย่างไรก็ตาม ภารกิจที่เป็นรูปธรรมใดๆ ของมันคือการต่อสู้ที่ไม่สิ้นสุด เนื่องจากอัลกอริทึมมักเผชิญกับการต่อต้านอย่างรุนแรงจากศัตรูตัวฉกาจของมัน ความซับซ้อน (complexity) :
Computation = Story(algorithm, solving problems)
เรื่องราวดำเนินไปเมื่อปัญหาใหม่และใหญ่ขึ้นผลักดันอัลกอริทึมไปถึงขีดจำกัดของมัน แต่ในการต่อสู้ของมัน มันได้รับมิตรภาพและการสนับสนุนจากญาติของมันในตระกูล abstraction : พี่สาวของมัน efficiency (ประสิทธิภาพ) ผู้ให้คำปรึกษาเกี่ยวกับการใช้ทรัพยากรอันมีค่าอย่างรอบคอบ; พี่ชายของมัน type (ประเภท) ผู้ปกป้องมันอย่างไม่ลดละจากข้อผิดพลาดในการเขียนโปรแกรมและอินพุตที่ไม่ถูกต้อง; และคุณยายที่ชาญฉลาดของมัน language (ภาษา) ผู้มอบความสามารถในการแสดงออกและทำให้แน่ใจว่ามันเป็นที่เข้าใจโดยสหายที่ไว้ใจได้ของมัน คอมพิวเตอร์ (computer) ซึ่งมันพึ่งพาในการดำเนินการตามแผนใดๆ ของมัน:
Computer Science = Story(abstractions, capturing computation)
อัลกอริทึมไม่ได้มีอำนาจทุกอย่างและไม่สามารถแก้ปัญหาทั้งหมดได้ และมันก็เสี่ยงต่อความไร้ประสิทธิภาพและข้อผิดพลาดเป็นพิเศษ แต่มันตระหนักดีถึงข้อเท็จจริงนี้ และความรู้เกี่ยวกับข้อจำกัดของตัวเองนี้เองที่ทำให้มันแข็งแกร่งและมั่นใจเกี่ยวกับการผจญภัยที่รออยู่ข้างหน้า