การจัดเรียงข้อมูล (Sorting) เป็นตัวอย่างสำคัญของการคำนวณ นอกเหนือจากการมีประโยชน์ในหลายด้านแล้ว การจัดเรียงข้อมูลยังช่วยอธิบายแนวคิดพื้นฐานบางประการของวิทยาการคอมพิวเตอร์ ประการแรก อัลกอริทึมการจัดเรียงข้อมูลที่แตกต่างกันซึ่งมี runtime และความต้องการพื้นที่ต่างกัน แสดงให้เห็นถึงผลกระทบของประสิทธิภาพในการตัดสินใจว่าจะแก้ปัญหาเชิงคำนวณอย่างไร ประการที่สอง การจัดเรียงข้อมูลเป็นปัญหาที่เราทราบขอบเขตความซับซ้อนขั้นต่ำ กล่าวอีกนัยหนึ่ง เราทราบ lower bound หรือขอบเขตล่างของจำนวนขั้นตอนที่อัลกอริทึมการจัดเรียงข้อมูลใด ๆ จะต้องใช้ การจัดเรียงข้อมูลจึงแสดงให้เห็นว่าวิทยาการคอมพิวเตอร์ในฐานะสาขาวิชาหนึ่งได้ระบุข้อจำกัดพื้นฐานเกี่ยวกับความเร็วของการคำนวณ ความรู้เกี่ยวกับข้อจำกัดเหล่านี้ช่วยเสริมพลังเพราะมันช่วยให้เรากำกับทิศทางการวิจัยได้อย่างมีประสิทธิภาพมากขึ้น ประการที่สาม ความแตกต่างระหว่างความซับซ้อนของปัญหากับความซับซ้อนของคำตอบของปัญหาช่วยให้เราเข้าใจแนวคิดของ optimal solution หรือคำตอบที่เหมาะสมที่สุด สุดท้าย อัลกอริทึมการจัดเรียงข้อมูลหลายตัวเป็นตัวอย่างของอัลกอริทึม divide-and-conquer หรือแบ่งแยกแล้วเอาชนะ อัลกอริทึมแบบนี้จะแบ่งอินพุตออกเป็นส่วนย่อย ๆ ซึ่งถูกประมวลผลแบบเรียกซ้ำ (recursively) และนำคำตอบของส่วนย่อยมาประกอบกันเป็นคำตอบของปัญหาเดิม ความสง่างามของหลักการ divide-and-conquer มาจากธรรมชาติแบบเรียกซ้ำและความสัมพันธ์กับแนวคิดที่ใกล้ชิดอย่างการอุปนัยทางคณิตศาสตร์ (mathematical induction) ซึ่งเป็นแนวทางที่มีประสิทธิภาพมากในการแก้ปัญหาและแสดงให้เห็นถึงพลังของการย่อยปัญหา (problem decomposition)
ดังที่ได้กล่าวถึงใน บทที่ 5 หนึ่งในการประยุกต์ใช้การจัดเรียงข้อมูลคือการสนับสนุนและเพิ่มความเร็วในการค้นหา ตัวอย่างเช่น การค้นหาองค์ประกอบใน array หรือ list ที่ไม่ได้จัดเรียงต้องใช้เวลาแบบ linear (linear time) ในขณะที่ใน array ที่จัดเรียงแล้วสามารถทำได้ในเวลาแบบ logarithmic (logarithmic time) ผ่านการค้นหาแบบ binary search ดังนั้นการคำนวณ (ในที่นี้คือการจัดเรียงข้อมูล) ที่ใช้ไปในช่วงเวลาหนึ่งสามารถถูกเก็บรักษาไว้ (ในรูปแบบของ array ที่จัดเรียงแล้ว) เพื่อใช้ในภายหลังในการเร่งความเร็วของการคำนวณอื่น ๆ (เช่น การค้นหา) โดยทั่วไปแล้ว การคำนวณเป็นทรัพยากรที่สามารถบันทึกและนำกลับมาใช้ใหม่ผ่าน data structures ปฏิสัมพันธ์ระหว่าง data structures และ algorithms นี้แสดงให้เห็นว่าทั้งสองสิ่งนี้เกี่ยวข้องกันอย่างใกล้ชิดเพียงใด
First Things First (สิ่งสำคัญต้องมาก่อน)
ในงานประจำวันของเขา Indiana Jones ทำงานเป็นศาสตราจารย์ในมหาวิทยาลัย ซึ่งหมายความว่าเขาต้องเผชิญกับปัญหาเกี่ยวกับการตรวจให้คะแนนข้อสอบ ดังนั้นการจัดเรียงข้อมูลจึงเกี่ยวข้องกับเขา ยิ่งไปกว่านั้น ในฐานะนักโบราณคดี เขาต้องเก็บสะสมวัตถุโบราณทางกายภาพและจัดระเบียบบันทึกและข้อสังเกตที่ทำขึ้นระหว่างการเดินทางสำรวจของเขา เช่นเดียวกับเอกสารในสำนักงาน สิ่งเหล่านี้จะได้รับประโยชน์อย่างมากจากการถูกจัดเรียง เพราะความเป็นระเบียบทำให้การค้นหาสิ่งของเฉพาะมีประสิทธิภาพมากขึ้น การผจญภัยของ Indiana Jones แสดงให้เห็นถึงการประยุกต์ใช้อีกอย่างของการจัดเรียงข้อมูล ซึ่งเกิดขึ้นเมื่อใดก็ตามที่เขาวางแผนว่าจะทำงานที่ซับซ้อนให้สำเร็จได้อย่างไร แผนคือการจัดเรียงชุดของการกระทำในลำดับที่ถูกต้อง
ภารกิจของ Indiana Jones ใน Raiders of the Lost Ark คือการหาหีบพันธสัญญาที่บรรจุบัญญัติสิบประการ (Ten Commandments) มีข่าวลือว่าหีบนี้ถูกฝังอยู่ในห้องลับภายในเมืองโบราณ Tanis เพื่อหาหีบ Indiana Jones ต้องหาห้องลับนี้ซึ่งเรียกว่า Well of Souls ตำแหน่งของห้องสามารถค้นพบได้จากแบบจำลองของ Tanis ซึ่งตั้งอยู่ในห้องแผนที่ (map room) โดยการวางจานทองคำพิเศษที่ตำแหน่งหนึ่งในห้องแผนที่ แสงอาทิตย์จะส่องไปยังตำแหน่งของ Well of Souls ในแบบจำลองของ Tanis ซึ่งจะเผยให้เห็นสถานที่ที่สามารถพบ Well of Souls ได้ เดิมทีจานทองคำนั้นอยู่ในความครอบครองของอาจารย์เก่าและที่ปรึกษาของ Indiana Jones คือ Professor Ravenwood แต่ต่อมาได้ถูกมอบให้กับ Marion Ravenwood ลูกสาวของเขา ดังนั้นในการหาหีบ Indiana Jones จึงต้องทำงานหลายอย่าง รวมถึง:
- ค้นหา Well of Souls (Well)
- หาห้องแผนที่ (Map)
- ได้จานทองคำ (Disc)
- ใช้จานเพื่อโฟกัสลำแสงอาทิตย์ (Sunbeam)
- หาผู้ครอบครองจานทองคำ (Marion)
นอกเหนือจากการทำงานเหล่านี้แล้ว Indiana Jones ยังต้องเดินทางระหว่างสถานที่ต่าง ๆ: ไปยังเนปาลเพื่อตามหา Marion Ravenwood และไปยังเมือง Tanis ในอียิปต์ ซึ่งเป็นที่ซ่อนของหีบใน Well of Souls
การหาลำดับที่ถูกต้องสำหรับชุดของงานนี้ไม่ใช่เรื่องยาก คำถามที่น่าสนใจจากมุมมองเชิงคำนวณคือ มีอัลกอริทึมใดบ้างที่แตกต่างกันสำหรับการแก้ปัญหานี้ และ runtime ของอัลกอริทึมเหล่านี้เป็นเท่าใด มีสองวิธีที่คนส่วนใหญ่จะใช้เมื่อถูกขอให้จัดเรียงลำดับ ทั้งสองวิธีเริ่มต้นด้วย list ที่ยังไม่ได้จัดเรียงและย้ายองค์ประกอบไปมาจนกว่า list จะถูกจัดเรียง ความแตกต่างระหว่างสองวิธีนี้สามารถอธิบายได้ดีที่สุดโดยการอธิบายวิธีการย้ายองค์ประกอบจาก list ที่ยังไม่ได้จัดเรียงไปยัง list ที่จัดเรียงแล้ว

รูป 6.1 Selection sort ค้นหาองค์ประกอบที่เล็กที่สุดใน list ที่ยังไม่ได้จัดเรียงซ้ำ ๆ ( ซ้ายของเส้นแนวตั้ง ) และต่อท้ายลงใน list ที่จัดเรียงแล้ว ( ขวา ) องค์ประกอบต่าง ๆ จะถูกจัดเรียงไม่ตามชื่อ แต่ตามลำดับความขึ้นต่อกันของงานที่พวกมันแทน
วิธีแรก ดังที่แสดงใน รูป 6.1 คือการค้นหาองค์ประกอบที่เล็กที่สุดใน list ที่ยังไม่ได้จัดเรียงซ้ำ ๆ และต่อท้ายลงใน list ที่จัดเรียงแล้ว ในการเปรียบเทียบการกระทำ การกระทำหนึ่งจะถือว่าเล็กกว่าอีกการกระทำหนึ่งถ้ามันสามารถเกิดขึ้นก่อนได้ ดังนั้น การกระทำที่เล็กที่สุดคือการกระทำที่ไม่จำเป็นต้องมีสิ่งใดมาก่อน ในตอนแรก องค์ประกอบทั้งหมดยังรอการประมวลผล และ list ที่จัดเรียงแล้วว่างเปล่า เนื่องจากงานแรกคือการเดินทางไปเนปาล นั่นหมายความว่าเนปาลเป็นองค์ประกอบที่เล็กที่สุด และเป็นองค์ประกอบแรกที่ถูกเลือกและต่อท้ายใน list ที่จัดเรียงแล้ว ขั้นตอนถัดไปคือการหาผู้ครอบครองจาน นั่นคือการตามหา Marion ถัดไป Indiana Jones ต้องได้จานทองคำ เดินทางไป Tanis และค้นพบห้องแผนที่ ซึ่งสะท้อนให้เห็นในบรรทัดรองสุดท้ายใน รูป 6.1 สุดท้าย Indiana Jones ต้องโฟกัสลำแสงอาทิตย์โดยใช้จานทองคำเพื่อเปิดเผยตำแหน่งของ Well of Souls ซึ่งเขาสามารถหาหีบได้ list ที่จัดเรียงแล้วที่ได้คือแผนสำหรับการผจญภัยของ Indiana Jones
ดังที่รูปแสดง อัลกอริทึมจะเสร็จสิ้นเมื่อ list ขององค์ประกอบที่ยังไม่ได้จัดเรียงว่างเปล่า เนื่องจากในกรณีนั้น องค์ประกอบทั้งหมดได้ถูกย้ายไปยัง list ที่จัดเรียงแล้ว อัลกอริทึมการจัดเรียงนี้เรียกว่า selection sort เพราะมันอาศัยการเลือกองค์ประกอบจาก list ที่ยังไม่ได้จัดเรียงซ้ำ ๆ โปรดสังเกตว่าวิธีนี้ทำงานได้ดีเช่นเดียวกันถ้าทำในทางกลับกัน นั่นคือค้นหาองค์ประกอบที่ ใหญ่ที่สุด ซ้ำ ๆ และเพิ่มไปยัง จุดเริ่มต้น ของ list ที่จัดเรียงแล้ว

รูป 6.2 Insertion sort แทรกองค์ประกอบถัดไปจาก list ที่ยังไม่ได้จัดเรียง ( ซ้ายของเส้นแนวตั้ง ) เข้าไปใน list ที่จัดเรียงแล้ว ( ขวา )
อาจดูเหมือนชัดเจน แต่เราจะหาองค์ประกอบที่เล็กที่สุดใน list ได้อย่างไร? วิธีง่าย ๆ คือการจดจำค่าขององค์ประกอบแรกและเปรียบเทียบกับค่าที่สอง สาม และต่อไปเรื่อย ๆ จนกว่าเราจะพบองค์ประกอบที่เล็กกว่า ในกรณีนั้น เราจะนำค่าขององค์ประกอบนั้นมาและเปรียบเทียบต่อ พร้อมจดจำองค์ประกอบที่เล็กที่สุดในปัจจุบันจนกระทั่งถึงจุดสิ้นสุดของ list วิธีนี้ใช้เวลาแบบ linear (linear time) ในกรณีเลวร้ายที่สุดตามความยาวของ list เนื่องจากองค์ประกอบที่เล็กที่สุดอาจอยู่ที่ปลาย list
ความพยายามส่วนใหญ่ใน selection sort ใช้ไปกับการค้นหาองค์ประกอบที่เล็กที่สุดใน list ที่ยังไม่ได้จัดเรียง แม้ว่า list ที่ยังไม่ได้จัดเรียงจะหดลงทีละหนึ่งองค์ประกอบในแต่ละขั้นตอน แต่ runtime โดยรวมของอัลกอริทึมการจัดเรียงนี้ยังคงเป็น quadratic เนื่องจากเราต้อง遍历 list ที่โดยเฉลี่ยแล้วมีองค์ประกอบครึ่งหนึ่งของทั้งหมด เราเห็นรูปแบบเดียวกันเมื่อวิเคราะห์อัลกอริทึมของ Hansel ใน บทที่ 2 สำหรับการหยิบก้อนกรวดถัดไปจากบ้าน: ผลรวมของจำนวน n ตัวแรกเป็นสัดส่วนกับกำลังสองของ n 1
วิธีที่ได้รับความนิยมอีกวิธีสำหรับการจัดเรียงคือการนำองค์ประกอบใด ๆ (โดยปกติคือตัวแรก) จาก list ที่ยังไม่ได้จัดเรียงและวางไว้ในตำแหน่งที่ถูกต้องใน list ที่จัดเรียงแล้ว องค์ประกอบจะถูกแทรก หลัง องค์ประกอบที่ใหญ่ที่สุดใน list ที่จัดเรียงแล้วที่ เล็กกว่า องค์ประกอบที่จะถูกแทรก กล่าวอีกนัยหนึ่ง ขั้นตอนการแทรกจะ遍历 list ที่จัดเรียงแล้วเพื่อหาองค์ประกอบสุดท้ายที่ต้องอยู่ก่อนองค์ประกอบที่จะถูกแทรก
ความพยายามในวิธีนี้ใช้ไปกับการแทรกองค์ประกอบ ไม่ใช่การเลือก ซึ่งทำให้วิธีนี้มีชื่อว่า insertion sort (ดู รูป 6.2 ) Insertion sort เป็นวิธีการจัดเรียงที่คนเล่นไพ่หลายคนนิยม เมื่อมีไพ่ที่ถูกแจกวางอยู่ข้างหน้าพวกเขา พวกเขาจะหยิบขึ้นมาทีละใบและสอดเข้าไปในมือที่จัดเรียงไว้แล้ว
ความแตกต่างระหว่าง insertion sort และ selection sort สามารถเห็นได้ดีที่สุดเมื่อย้ายองค์ประกอบ Sunbeam จาก list ที่ยังไม่ได้จัดเรียงไปยัง list ที่จัดเรียงแล้ว ดังที่ รูป 6.2 แสดง องค์ประกอบจะถูกเอาออกจาก list ที่ยังไม่ได้จัดเรียง โดยไม่ต้องค้นหาใด ๆ และถูกแทรกเข้าไปใน list ที่จัดเรียงแล้วโดย遍历 list จนกว่าจะพบตำแหน่งที่เหมาะสมระหว่าง Map และ Well
ตัวอย่างนี้ยังแสดงให้เห็นความแตกต่างเล็กน้อยใน runtime ของทั้งสองอัลกอริทึม ในขณะที่ selection sort ต้อง遍历 list ใด list หนึ่งทั้งหมดทุกครั้งที่เลือกองค์ประกอบ insertion sort ต้องทำเช่นนี้ก็ต่อเมื่อองค์ประกอบที่จะแทรกมีขนาดใหญ่กว่าองค์ประกอบทั้งหมดใน list ที่จัดเรียงแล้วในขณะนั้น ในกรณีเลวร้ายที่สุด เมื่อ list ที่จะจัดเรียงถูกจัดเรียงอยู่แล้วตั้งแต่ต้น ทุกองค์ประกอบจะถูกแทรกที่ท้าย list ที่จัดเรียงแล้ว ในกรณีนี้ insertion sort มี runtime เท่ากับ selection sort ในทางตรงกันข้าม เมื่อ list ถูกเรียงแบบย้อนกลับ นั่นคือ จากใหญ่ไปเล็กที่สุด ทุกองค์ประกอบจะถูกแทรกที่ด้านหน้าของ list ที่จัดเรียงแล้ว ซึ่งนำไปสู่ runtime แบบ linear สำหรับ insertion sort เราสามารถแสดงได้ว่าโดยเฉลี่ยแล้ว insertion sort ยังคงมี runtime แบบ quadratic อยู่ดี Insertion sort อาจเร็วกว่า selection sort มากในบางกรณี และไม่มีทางที่แย่กว่าได้
ทำไม insertion sort ถึงมี runtime ที่ดีกว่า selection sort ในบางกรณี ทั้งที่ทั้งคู่ทำงานคล้ายกัน? ความแตกต่างสำคัญคือ insertion sort ใช้ประโยชน์จากผลลัพธ์ของการคำนวณของตัวเอง เนื่องจากองค์ประกอบใหม่ถูกแทรกเข้าไปใน list ที่จัดเรียงไว้แล้ว การแทรกจึงไม่จำเป็นต้อง遍历ทั้ง list เสมอไป ในทางตรงกันข้าม selection sort มักจะต่อท้าย list ที่จัดเรียงไว้แล้วเสมอ และเนื่องจากกระบวนการเลือกไม่สามารถใช้ประโยชน์จากการจัดเรียงได้ มันจึงต้องสแกน list ที่ยังไม่ได้จัดเรียงทั้งหมดเสมอ การเปรียบเทียบนี้แสดงให้เห็นหลักการออกแบบที่สำคัญในวิทยาการคอมพิวเตอร์ที่เรียกว่า reuse หรือการนำกลับมาใช้ใหม่
นอกเหนือจากประสิทธิภาพแล้ว อัลกอริทึมการจัดเรียงทั้งสองแบบแตกต่างกันในเรื่องความเหมาะสมกับปัญหาการจัดเรียงการกระทำเป็นแผนหรือไม่? ทั้งสองวิธีไม่เหมาะ เนื่องจากความยากลำบากเฉพาะในปัญหาตัวอย่างนี้ไม่ใช่กระบวนการจัดเรียง แต่เป็นการตัดสินใจว่าการกระทำใดมาก่อนการกระทำอื่น หากมีความไม่แน่นอนเกี่ยวกับลำดับที่แน่นอนขององค์ประกอบ selection sort ดูจะน่าสนใจน้อยที่สุด เพราะในขั้นตอนแรกสุด เราต้องตัดสินใจแล้วว่าองค์ประกอบที่เล็กที่สุดในเบื้องต้นนั้นเปรียบเทียบกับองค์ประกอบอื่นทั้งหมดอย่างไร Insertion sort ดีกว่า เพราะเราสามารถเลือกองค์ประกอบใดก็ได้ในขั้นแรกโดยไม่ต้องเปรียบเทียบใด ๆ และได้ list ที่มีองค์ประกอบเดียวที่จัดเรียงแล้ว อย่างไรก็ตาม ในขั้นตอนต่อ ๆ มา แต่ละองค์ประกอบที่เลือกจะต้องถูกเปรียบเทียบกับองค์ประกอบที่มากขึ้นเรื่อย ๆ ใน list ที่จัดเรียงที่กำลังเติบโตเพื่อหาตำแหน่งที่ถูกต้อง แม้ว่าในช่วงแรก จำนวนการเปรียบเทียบที่ยากอาจน้อยกว่าสำหรับ insertion sort เมื่อเทียบกับ selection sort แต่อัลกอริทึมอาจบังคับให้ตัดสินใจในสิ่งที่เรายังไม่สามารถตัดสินใจได้ มีวิธีใดที่ให้ผู้จัดเรียงควบคุมได้มากขึ้นว่าจะเปรียบเทียบองค์ประกอบใด?
Split as You Please (แบ่งตามที่คุณต้องการ)
วิธีจัดเรียงที่ดีควรช่วยให้เราสามารถเลื่อนการตัดสินใจที่ยากออกไป และเริ่มต้นด้วยการตัดสินใจที่ง่ายก่อน ในกรณีของแผนของ Indiana Jones สำหรับการหาหีบพันธสัญญา ตัวอย่างเช่น เป็นที่ชัดเจนว่า Well of Souls และห้องแผนที่อยู่ใน Tanis ดังนั้นทุกการกระทำที่เกี่ยวข้องกับสองสถานที่นี้ต้องเกิดขึ้นหลังจากขั้นตอนการเดินทางไป Tanis และทุกสิ่งอื่นต้องมาก่อน
โดยการแบ่งองค์ประกอบของ list ออกเป็นพวกที่มาก่อนและพวกที่มาหลังองค์ประกอบที่ใช้แบ่ง ซึ่งเรียกว่า pivot เราได้แยก list ที่ไม่ได้จัดเรียงหนึ่ง list ออกเป็นสอง list ที่ไม่ได้จัดเรียง เราได้อะไรจากการทำเช่นนี้? แม้ว่าจะยังไม่ได้จัดเรียงอะไร แต่เราบรรลุเป้าหมายสำคัญสองประการ ประการแรก เราได้ย่อยปัญหาจากการจัดเรียง list ยาวหนึ่ง list เป็นการจัดเรียง list ที่สั้นกว่าสอง list การทำให้ปัญหาง่ายขึ้นมักเป็นขั้นตอนสำคัญในการแก้ปัญหา ประการที่สอง เมื่อปัญหาย่อยทั้งสองได้รับการแก้ไข นั่นคือ หลังจากที่ list ที่ไม่ได้จัดเรียงสอง list ถูกจัดเรียงแล้ว เราสามารถต่อ list ทั้งสองเข้าด้วยกันเพื่อให้ได้ list ที่จัดเรียงแล้ว กล่าวอีกนัยหนึ่ง การย่อยเป็นปัญหาย่อยช่วยอำนวยความสะดวกในการสร้างคำตอบสำหรับปัญหาโดยรวมจากปัญหาย่อยทั้งสอง
นี่เป็นผลลัพธ์จากการที่ list ที่ไม่ได้จัดเรียงสอง list ถูกสร้างขึ้นอย่างไร ให้เราใช้สัญลักษณ์ S แทน list ขององค์ประกอบที่เล็กกว่า Tanis และ L แทน list ขององค์ประกอบที่ใหญ่กว่า Tanis เราจะรู้ว่าองค์ประกอบทั้งหมดใน S เล็กกว่าองค์ประกอบทั้งหมดใน L (แต่ S และ L ยังไม่ได้ถูกจัดเรียง) เมื่อ list S และ L ถูกจัดเรียงแล้ว list ที่เกิดจากการต่อ S , Tanis, และ L ก็จะถูกจัดเรียงด้วย ดังนั้น งานสุดท้ายคือการจัดเรียง list S และ L เมื่อทำเสร็จแล้ว เราสามารถนำผลลัพธ์มาต่อกันได้ list ที่เล็กกว่าเหล่านี้จะถูกจัดเรียงอย่างไร? เราสามารถเลือกวิธีใดก็ได้ เราสามารถใช้วิธีการแบ่งและต่อแบบเรียกซ้ำ หรือถ้า list มีขนาดเล็กพอ เราก็สามารถใช้วิธีง่าย ๆ เช่น selection sort หรือ insertion sort
ในปี 1960 นักวิทยาการคอมพิวเตอร์ชาวอังกฤษ Tony Hoare (ชื่อเต็ม Sir Charles Antony Richard Hoare) เป็นผู้คิดค้นวิธีการจัดเรียงนี้ ซึ่งเรียกว่า quicksort รูป 6.3 แสดงให้เห็นว่า quicksort ทำงานอย่างไรในการสร้างแผนของ Indiana Jones สำหรับการหาหีบพันธสัญญา ในขั้นแรก list ที่ยังไม่ได้จัดเรียงถูกแบ่งออกเป็นสอง list โดยคั่นด้วย pivot ซึ่งก็คือ Tanis ในขั้นตอนถัดไป list ที่ยังไม่ได้จัดเรียงสอง list ต้องถูกจัดเรียง เนื่องจากแต่ละ list มีเพียงสามองค์ประกอบ จึงสามารถทำได้ง่ายโดยใช้อัลกอริทึมใดก็ได้
เพื่อเป็นตัวอย่าง มาจัดเรียง list ย่อยขององค์ประกอบที่เล็กกว่า Tanis โดยใช้ quicksort ถ้าเราเลือก Nepal เป็นองค์ประกอบแบ่งแยก เราจะได้ list ที่ยังไม่ได้จัดเรียง Disc → Marion เมื่อรวบรวมองค์ประกอบที่ใหญ่กว่า Nepal ในทำนองเดียวกัน list ขององค์ประกอบที่เล็กกว่า Nepal จะว่างเปล่า ซึ่งจัดเรียงแล้วโดยปริยาย ในการจัดเรียง list สององค์ประกอบนี้ เราก็แค่เปรียบเทียบทั้งสององค์ประกอบและสลับตำแหน่ง ซึ่งจะได้ list ที่จัดเรียงแล้ว Marion → Disc จากนั้นเราก็ต่อ list ว่าง, Nepal, และ Marion → Disc และได้ list ย่อยที่จัดเรียงแล้ว Nepal → Marion → Disc การจัดเรียงจะทำงานในลักษณะเดียวกันถ้าเราเลือกองค์ประกอบอื่นเป็น pivot ถ้าเลือก Disc เราจะได้ list ว่างอีกครั้งและ list สององค์ประกอบที่ต้องจัดเรียง และถ้าเลือก Marion เราจะได้ list องค์ประกอบเดียวสอง list ที่จัดเรียงแล้วทั้งคู่ การจัดเรียง list ย่อยขององค์ประกอบที่ใหญ่กว่า Tanis ก็เป็นไปในลักษณะเดียวกัน

รูป 6.3 Quicksort แบ่ง list ออกเป็นสอง list ย่อยขององค์ประกอบที่เล็กกว่าและใหญ่กว่า ตามลำดับ เมื่อเทียบกับ pivot ที่เลือก จากนั้น list ทั้งสองจะถูกจัดเรียง และผลลัพธ์จะถูกนำมาต่อกับ pivot เพื่อสร้าง list ที่จัดเรียงแล้วที่สมบูรณ์
เมื่อ list ย่อยถูกจัดเรียงแล้ว เราสามารถต่อเข้าด้วยกันโดยมี Tanis อยู่ตรงกลางและได้ผลลัพธ์สุดท้าย ดังที่ รูป 6.3 แสดง quicksort ลู่เข้าหาคำตอบอย่างรวดเร็วน่าประหลาดใจ แต่มันเป็นเช่นนี้เสมอไปหรือไม่? runtime ของ quicksort โดยทั่วไปเป็นเท่าใด? ดูเหมือนว่าเราโชคดีที่เลือก Tanis เป็น pivot ในขั้นแรก เพราะ Tanis แบ่ง list ออกเป็นสอง list ที่มีขนาดเท่ากัน ถ้าเราสามารถเลือก pivot ที่มีคุณสมบัตินี้ได้เสมอ list ย่อยจะถูกแบ่งครึ่งเสมอ ซึ่งหมายความว่าจำนวนระดับของการแบ่งจะเป็นสัดส่วนกับลอการิทึมของความยาวของ list เดิม สิ่งนี้หมายความว่าอย่างไรสำหรับ runtime โดยรวมของ quicksort ในกรณีนี้และในกรณีทั่วไป?
การวนซ้ำครั้งแรก ซึ่งเราแบ่ง list หนึ่งเป็นสอง ใช้เวลาแบบ linear เพราะเราต้องตรวจสอบองค์ประกอบทั้งหมดใน list ในการวนซ้ำครั้งถัดไป เราต้องแบ่ง list ย่อยสอง list ซึ่งอีกครั้งใช้เวลาแบบ linear โดยรวม เนื่องจากจำนวนองค์ประกอบทั้งหมดในทั้งสอง list น้อยกว่า list เดิมหนึ่งองค์ประกอบ 2 ไม่ว่าเราจะแบ่งที่ใดและไม่ว่า list ย่อยแต่ละอันจะยาวเท่าใด และรูปแบบนี้ดำเนินต่อไป: แต่ละระดับมีองค์ประกอบไม่มากกว่าระดับก่อนหน้า และดังนั้นจึงใช้เวลาแบบ linear ในการแบ่ง โดยรวมแล้วเราสะสมเวลาแบบ linear สำหรับแต่ละระดับ ซึ่งหมายความว่า runtime ของ quicksort ขึ้นอยู่กับจำนวนระดับที่จำเป็นสำหรับการแบ่ง list ย่อย เมื่อ list เดิมถูกย่อยสลายเป็นองค์ประกอบเดี่ยวทั้งหมด กระบวนการแบ่งทำให้แน่ใจว่าองค์ประกอบทั้งหมดเหล่านี้อยู่ในลำดับที่ถูกต้อง และสามารถนำมาต่อกันเป็น list ผลลัพธ์ที่จัดเรียงแล้ว ซึ่งใช้ความพยายามแบบ linear อีกครั้ง ดังนั้น runtime ทั้งหมดสำหรับ quicksort จึงเท่ากับผลรวมของเวลาแบบ linear ในทุกระดับ
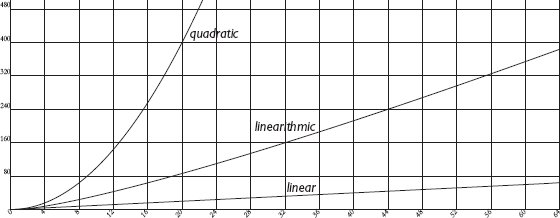
รูป 6.4 การเปรียบเทียบ runtime แบบ linearithmic, linear, และ quadratic
ในกรณีดีที่สุด เมื่อเราสามารถแบ่งแต่ละ list ย่อยออกเป็นครึ่งประมาณเท่า ๆ กัน เราจะได้จำนวนระดับแบบ logarithmic ตัวอย่างเช่น list ที่มี 100 องค์ประกอบนำไปสู่ 7 ระดับ list ที่มี 1,000 องค์ประกอบนำไปสู่ 10 ระดับ และ list ที่มี 1,000,000 องค์ประกอบสามารถย่อยสลายได้สมบูรณ์ในเพียง 20 ระดับ 3 สำหรับ runtime ทั้งหมดนี่หมายความว่า ในกรณีของ 1,000,000 องค์ประกอบ เราต้องใช้ความพยายามแบบ linear ในการสแกน list ของ 1,000,000 องค์ประกอบเพียง 20 ครั้งเท่านั้น สิ่งนี้นำไปสู่ runtime ในระดับหลายสิบล้านขั้นตอน ซึ่งดีกว่า runtime แบบ quadratic มาก ซึ่งหมายถึงหลักแสนล้านถึงล้านล้านขั้นตอน พฤติกรรม runtime นี้ ซึ่งเติบโตตามสัดส่วนของขนาดของอินพุตคูณด้วยลอการิทึมของขนาด เรียกว่า linearithmic มันไม่ดีเท่ารันไทม์แบบ linear แต่ดีกว่า runtime แบบ quadratic มาก (ดู รูป 6.4 )
Quicksort มี runtime แบบ linearithmic ในกรณีดีที่สุด อย่างไรก็ตาม ถ้าเราเลือก pivot อย่างไม่ฉลาด สถานการณ์จะแตกต่างออกไปมาก ตัวอย่างเช่น ถ้าเราเลือก Nepal แทน Tanis เป็น pivot ตัวแรก list ย่อยขององค์ประกอบที่เล็กกว่าจะว่างเปล่า และ list ย่อยขององค์ประกอบที่ใหญ่กว่าจะมีองค์ประกอบทั้งหมดยกเว้น Nepal ถ้าต่อไปเราเลือก Marion เป็น pivot ของ list ย่อยนั้น เราจะเจอสถานการณ์เดียวกันที่ list หนึ่งว่างและอีก list สั้นกว่า list ที่ถูกแบ่งเพียงหนึ่งองค์ประกอบ เราจะเห็นว่าในสถานการณ์นี้ quicksort มีพฤติกรรมเหมือน selection sort ซึ่งก็เอาองค์ประกอบที่เล็กที่สุดออกจาก list ที่ยังไม่ได้จัดเรียงซ้ำ ๆ เช่นกัน และเช่นเดียวกับ selection sort quicksort จะมี runtime แบบ quadratic ในกรณีนี้ด้วย ประสิทธิภาพของ quicksort ขึ้นอยู่กับการเลือก pivot: ถ้าเราสามารถหาองค์ประกอบที่อยู่ตรงกลางได้เสมอ กระบวนการแบ่งจะให้ list ที่ถูกแบ่งเท่า ๆ กัน แต่เราจะหา pivot ที่ดีได้อย่างไร? แม้จะไม่ใช่เรื่องง่ายที่จะรับประกัน pivot ที่ดี แต่ปรากฎว่าการเลือกองค์ประกอบแบบสุ่มหรือค่ามัธยฐานขององค์ประกอบแรก กลาง และสุดท้ายนั้นใช้ได้ดีในทางปฏิบัติ
ความสำคัญและผลกระทบของ pivot มีความเกี่ยวข้องอย่างใกล้ชิดกับแนวคิดของขอบเขต (boundary) ที่ใช้ใน บทที่ 5 เพื่ออธิบายแก่นแท้ของการค้นหาที่มีประสิทธิภาพ ในกรณีของการค้นหา จุดประสงค์ของขอบเขตคือการแบ่งพื้นที่ค้นหาออกเป็นภายนอกและภายใน เพื่อให้พื้นที่ภายในเล็กที่สุดเท่าที่จะเป็นไปได้ และทำให้การค้นหาส่วนที่เหลือง่ายขึ้น ในกรณีของการจัดเรียง ขอบเขตควรแบ่งพื้นที่การจัดเรียงออกเป็นส่วนเท่า ๆ กัน เพื่อให้การจัดเรียงแต่ละส่วนง่ายขึ้นอย่างเพียงพอผ่านการย่อยปัญหา ดังนั้น ถ้า pivot ไม่ถูกเลือกอย่างดี runtime ของ quicksort ก็จะแย่ลง แต่ในขณะที่ quicksort มี runtime แบบ quadratic ในกรณีเลวร้ายที่สุด มันมี runtime แบบ linearithmic โดยเฉลี่ย และมันทำงานได้ดีในทางปฏิบัติ
The Best Is Yet to Come (สิ่งที่ดีที่สุดยังมาไม่ถึง)
มีวิธีการจัดเรียงที่เร็วกว่า quicksort อีกไหม ตัวอย่างเช่น อัลกอริทึมที่มี runtime แบบ linearithmic หรือดีกว่าในกรณีเลวร้ายที่สุด? มี หนึ่งในอัลกอริทึมดังกล่าวคือ mergesort ซึ่งถูกคิดค้นโดยนักคณิตศาสตร์ชาวฮังการี-อเมริกัน John von Neumann ในปี 1945 4 Mergesort แบ่ง list ที่ยังไม่ได้จัดเรียงออกเป็นสองส่วนและทำงานโดยการย่อยปัญหาเป็นส่วนย่อย ๆ คล้ายกับ quicksort อย่างไรก็ตาม mergesort ไม่ได้เปรียบเทียบองค์ประกอบในขั้นตอนนี้ มันแค่แบ่ง list ออกเป็นสองส่วนเท่า ๆ กัน เมื่อ list ย่อยทั้งสองนี้ถูกจัดเรียงแล้ว พวกมันสามารถถูกรวม (merge) เข้าเป็น list ที่จัดเรียงแล้วได้โดย traversing ทั้งสอง list ในแบบขนานและเปรียบเทียบองค์ประกอบจากทั้งสอง list ทีละตัว วิธีนี้ทำงานโดยการเปรียบเทียบองค์ประกอบแรกของทั้งสอง list ซ้ำ ๆ และนำองค์ประกอบที่เล็กกว่า เนื่องจาก list ย่อยทั้งสองถูกจัดเรียงแล้ว จึงมั่นใจได้ว่า list ที่ถูกรวมแล้วก็ถูกจัดเรียงเช่นกัน แต่ list ย่อยสอง list ที่เกิดจากขั้นตอนการแบ่งจะถูกจัดเรียงได้อย่างไร? ทำได้โดยการใช้ mergesort แบบเรียกซ้ำกับทั้งสอง list Mergesort แสดงไว้ใน รูป 6.5
ในขณะที่ quicksort และ mergesort เป็นอัลกอริทึมที่ยอดเยี่ยมสำหรับการเขียนโปรแกรมบนคอมพิวเตอร์อิเล็กทรอนิกส์ แต่มันไม่สะดวกนักสำหรับความทรงจำของมนุษย์ที่ไม่มีเครื่องช่วย เพราะพวกมันต้องการการจดบันทึกจำนวนมาก โดยเฉพาะอย่างยิ่ง สำหรับ list ที่ใหญ่กว่า อัลกอริทึมทั้งสองต้องรักษากลุ่มของ list เล็ก ๆ ที่อาจมีจำนวนมาก ในกรณีของ quicksort list เหล่านั้นยังต้องถูกเก็บไว้ในลำดับที่ถูกต้อง ดังนั้น Indiana Jones เช่นเดียวกับพวกเราส่วนใหญ่ อาจจะใช้การจัดเรียงแบบ insertion sort บางรูปแบบ ซึ่งอาจเสริมด้วยการเลือกองค์ประกอบอย่างชาญฉลาด เว้นแต่ขนาดของ list ที่จะจัดเรียงจะต้องการอัลกอริทึมที่มีประสิทธิภาพมากกว่า ตัวอย่างเช่น เมื่อใดก็ตามที่ฉันสอนชั้นเรียนระดับปริญญาตรีขนาดใหญ่ ฉันใช้รูปแบบหนึ่งของ bucket sort สำหรับการจัดเรียงข้อสอบตามชื่อ ฉันวางข้อสอบลงในกองต่าง ๆ (เรียกว่า buckets หรือถัง) ตามตัวอักษรแรกของนามสกุลของนักเรียน และรักษาแต่ละกองให้เรียงลำดับโดยใช้ insertion sort หลังจากข้อสอบทั้งหมดถูกวางใน buckets ของตนแล้ว buckets จะถูกต่อตามลำดับตัวอักษรเพื่อสร้าง list ที่เรียงลำดับแล้ว Bucket sort คล้ายกับ counting sort (ซึ่งจะกล่าวถึงในภายหลัง)

รูป 6.5 Mergesort แบ่ง list ออกเป็นสอง list ย่อยที่มีขนาดเท่ากัน จัดเรียงพวกมัน และรวมผลลัพธ์ที่จัดเรียงแล้วเข้าเป็น list ที่จัดเรียงแล้วหนึ่ง list วงเล็บแสดงลำดับที่ list ต้องถูกรวม ในบรรทัดที่ 4 การย่อยสลายเสร็จสมบูรณ์เมื่อได้ list ที่มีองค์ประกอบเดี่ยวเท่านั้น ในบรรทัดที่ 5 list องค์ประกอบเดี่ยวสามคู่ถูกรวมเป็น list สององค์ประกอบที่จัดเรียงแล้วสาม list และในบรรทัดที่ 6 list เหล่านั้นถูกรวมอีกครั้งเป็น list สี่องค์ประกอบหนึ่ง list และ list สามองค์ประกอบหนึ่ง list ซึ่งถูกรวมในขั้นตอนสุดท้ายเพื่อให้ได้ผลลัพธ์สุดท้าย
เมื่อมองแวบแรก mergesort ดูซับซ้อนกว่า quicksort แต่นี่อาจเป็นเพราะว่าบางขั้นตอนถูกข้ามไปในคำอธิบายของ quicksort ถึงกระนั้นก็ดูเหมือนว่าการรวม list ที่ยาวขึ้นเรื่อย ๆ ซ้ำ ๆ นั้นไม่มีประสิทธิภาพ อย่างไรก็ตาม สัญชาตญาณนี้เป็นการหลอกลวง เนื่องจากการย่อยสลายเป็นระบบและลดขนาดของ list ลงครึ่งหนึ่งในทุกขั้นตอน ประสิทธิภาพ runtime โดยรวมจึงค่อนข้างดี: ในกรณีเลวร้ายที่สุด runtime ของ mergesort เป็นแบบ linearithmic ซึ่งสามารถเห็นได้ดังนี้ ประการแรก เนื่องจากเราแบ่ง list ครึ่งหนึ่งเสมอ จำนวนครั้งที่ list ต้องถูกแบ่งจึงเป็นแบบ logarithmic ประการที่สอง การรวมในแต่ละระดับใช้เวลาแบบ linear เท่านั้นเพราะเราต้องประมวลผลแต่ละองค์ประกอบหนึ่งครั้ง (ดู รูป 6.5 ) สุดท้าย เนื่องจากการรวมเกิดขึ้นในแต่ละระดับหนึ่งครั้ง โดยรวมแล้วเราจึงได้ runtime แบบ linearithmic
Mergesort มีความคล้ายคลึงกับ quicksort โดยเฉพาะอย่างยิ่ง อัลกอริทึมทั้งสองมีขั้นตอนสำหรับการแบ่ง list ตามด้วยขั้นตอนการจัดเรียงแบบเรียกซ้ำสำหรับแต่ละ list ที่เล็กกว่า และสุดท้ายคือขั้นตอนสำหรับการรวม list ย่อยที่จัดเรียงแล้วเป็น list ที่จัดเรียงที่ยาวขึ้น อันที่จริง ทั้ง quicksort และ mergesort เป็นตัวอย่างของอัลกอริทึม divide-and-conquer ซึ่งทั้งหมดเป็นตัวอย่างของรูปแบบทั่วไปต่อไปนี้:
ถ้าปัญหาเป็นเรื่องเล็กน้อย ให้แก้ไขโดยตรง
มิฉะนั้น
(1) ย่อยปัญหาออกเป็นปัญหาย่อย
(2) แก้ปัญหาย่อย
(3) รวมคำตอบของปัญหาย่อยเป็นคำตอบของปัญหา
กรณีของการแก้ปัญหาที่ไม่ใช่เรื่องเล็กน้อยแสดงให้เห็นว่า divide-and-conquer ทำงานอย่างไร ขั้นแรกคือขั้นตอน divide หรือการแบ่ง ซึ่งลดความซับซ้อนของปัญหา ขั้นตอนที่สองคือการประยุกต์ใช้วิธีแบบเรียกซ้ำกับปัญหาย่อย ถ้าปัญหาย่อยที่ได้มีขนาดเล็กพอ ก็สามารถแก้ไขได้โดยตรง มิฉะนั้น พวกมันจะถูกย่อยต่อไปจนกว่าจะเล็กพอที่จะแก้ไขโดยตรง ขั้นตอนที่สามคือขั้นตอน merge หรือการรวม ซึ่งเป็นการประกอบคำตอบของปัญหาจากคำตอบของปัญหาย่อย
Quicksort ทำงานส่วนใหญ่ในขั้นตอน divide ซึ่งการเปรียบเทียบองค์ประกอบทั้งหมดเกิดขึ้น: โดยการทำให้แน่ใจว่าองค์ประกอบในสอง list ถูกแยกออกจากกันด้วย pivot มันทำให้ขั้นตอน merge เป็นเพียงการต่อ list อย่างง่าย ในทางตรงกันข้าม ขั้นตอน divide ของ mergesort นั้นง่ายมากและไม่มีการเปรียบเทียบองค์ประกอบใด ๆ งานส่วนใหญ่ของ mergesort เกิดขึ้นในขั้นตอน merge ซึ่ง list ที่จัดเรียงแล้วถูกรวมเข้าด้วยกัน คล้ายกับซิป
The Quest Is Over: No Better Sorting Algorithm, Ever (การตามหาสิ้นสุดลง: ไม่มีอัลกอริทึมการจัดเรียงใดที่ดีไปกว่านี้ อีกเลย)
Mergesort เป็นวิธีการจัดเรียงที่มีประสิทธิภาพมากที่สุดที่ได้กล่าวถึงมาจนถึงตอนนี้ แต่มันเป็นไปได้ไหมที่จะจัดเรียงให้เร็วกว่านี้? คำตอบคือทั้งใช่และไม่ใช่ แม้ว่าเราจะไม่สามารถจัดเรียงให้เร็วกว่านี้ได้ในกรณีทั่วไป แต่เราสามารถทำได้ดีกว่าภายใต้สมมติฐานบางประการเกี่ยวกับองค์ประกอบที่จะจัดเรียง ตัวอย่างเช่น ถ้าเรารู้ว่า list ที่จะจัดเรียงมีเฉพาะตัวเลขระหว่าง 1 ถึง 100 เราสามารถสร้าง array ที่มี 100 ช่อง หนึ่งช่องสำหรับแต่ละหมายเลขที่เป็นไปได้ใน list วิธีนี้คล้ายกับ bucket sort ซึ่งมีกองหนึ่งสำหรับแต่ละตัวอักษรของตัวอักษร ในที่นี้แต่ละช่องของ array สอดคล้องกับกองที่ประกอบด้วยตัวเลขเฉพาะ ช่องของ array มีดัชนีตั้งแต่ 1 ถึง 100 เราใช้แต่ละช่องที่มีดัชนี i เพื่อนับว่าค่า i ปรากฏใน list กี่ครั้ง ขั้นแรก เราเก็บ 0 ในแต่ละช่องของ array เนื่องจากเรายังไม่รู้ว่าตัวเลขใดอยู่ใน list ที่จะจัดเรียง จากนั้นเรา traversing list และสำหรับแต่ละองค์ประกอบ i ที่พบ เราเพิ่มจำนวนที่เก็บในช่องของ array ที่มีดัชนี i สุดท้าย เรา traversing array ตามลำดับดัชนีที่เพิ่มขึ้นและใส่แต่ละดัชนีลงใน list ผลลัพธ์ตามจำนวนครั้งที่ตัวนับของช่องนั้นระบุ ตัวอย่างเช่น ถ้า list ที่จะจัดเรียงคือ 4→2→5→4→2→6 เราจะได้ array ต่อไปนี้หลังจาก traversing list:

โดยการ traversing array เราพบว่า 1 ไม่ปรากฏใน list เนื่องจากตัวนับของมันยังคงเป็น 0 ดังนั้น 1 จะไม่เป็นส่วนหนึ่งของ list ผลลัพธ์ที่จัดเรียงแล้ว ในทางตรงกันข้าม เลข 2 ปรากฏสองครั้งและจะถูกใส่ลงใน list สองครั้ง และต่อไปเรื่อย ๆ list ผลลัพธ์จะเป็น 2→2→4→4→5→6 วิธีนี้เรียกว่า counting sort เนื่องจาก array รักษาตัวนับว่าองค์ประกอบหนึ่ง ๆ ปรากฏใน list ที่จะจัดเรียงกี่ครั้ง runtime ของ counting sort เกิดจากต้นทุนรวมของการ traversing list และ array เนื่องจากแต่ละขั้นตอนเป็นแบบ linear ตามขนาดของ data structure ที่เกี่ยวข้อง (list และ array) counting sort จึงทำงานในเวลาแบบ linear ตามขนาดของ list หรือ array แล้วแต่ว่าอันไหนใหญ่กว่า
ข้อเสียของ counting sort คือมันสามารถสิ้นเปลืองพื้นที่ได้มาก ในตัวอย่าง ช่องทั้งหมดที่มีดัชนี 7 ถึง 100 ไม่เคยถูกใช้เลย ยิ่งไปกว่านั้น มันทำงานได้ก็ต่อเมื่อองค์ประกอบสามารถใช้เป็นดัชนีของ array และถ้าช่วงขององค์ประกอบของ list เป็นที่รู้จักและไม่ใหญ่เกินไป ตัวอย่างเช่น เราไม่สามารถจัดเรียง list ของชื่อโดยใช้ counting sort เพราะชื่อเป็นลำดับของตัวอักษรและไม่สามารถใช้เป็นดัชนีของ array ได้ 5 มีอัลกอริทึมการจัดเรียงเฉพาะอื่น ๆ สำหรับ list ของ strings ตัวอย่างเช่น data structure แบบ trie (ดู บทที่ 5 ) สามารถใช้ในการจัดเรียง list ของ strings แต่วิธีเหล่านั้นก็มีสมมติฐานอื่น ๆ เกี่ยวกับองค์ประกอบที่จะจัดเรียง
As Good as It Gets (ดีที่สุดเท่าที่จะทำได้)
หากไม่ใช้ประโยชน์จากคุณสมบัติพิเศษของข้อมูล เราไม่สามารถจัดเรียงได้เร็วกว่า mergesort แม้ว่าข้อเท็จจริงนี้อาจดูน่าผิดหวังในตอนแรก แต่มันก็เป็นข่าวดีเช่นกัน เพราะมันให้ความมั่นใจแก่เราว่าเราพบอัลกอริทึมที่เร็วที่สุดเท่าที่เป็นไปได้แล้ว กล่าวอีกนัยหนึ่ง mergesort เป็นคำตอบที่ดีที่สุดสำหรับปัญหาการจัดเรียง มันจึงเป็น optimal algorithm หรืออัลกอริทึมที่เหมาะสมที่สุด นักวิจัยวิทยาการคอมพิวเตอร์สามารถพิจารณาได้ว่าปัญหานี้ได้รับการแก้ไขแล้ว และใช้เวลาและพลังงานของพวกเขาในการแก้ปัญหาอื่น ๆ
ความเหมาะสมที่สุดของ mergesort ขึ้นอยู่กับข้อเท็จจริงสองประการที่เกี่ยวข้องกันแต่แตกต่างกัน Mergesort มี runtime แบบ linearithmic และอัลกอริทึมการจัดเรียงใด ๆ สำหรับกรณีทั่วไปต้องมี runtime อย่างน้อยแบบ linearithmic ส่วนที่สองนี้เป็นสิ่งที่ยืนยันข้อสรุปเกี่ยวกับความเหมาะสมที่สุดของ mergesort และในเรื่องนั้นก็รวมถึงความเหมาะสมที่สุดของอัลกอริทึมการจัดเรียงอื่น ๆ ที่มี runtime แบบ linearithmic ในกรณีเลวร้ายที่สุดด้วย เป้าหมายสูงสุดในการออกแบบอัลกอริทึมและ data structures คือการหาอัลกอริทึมที่เหมาะสมที่สุดสำหรับปัญหา นั่นคือ อัลกอริทึมที่มีความซับซ้อนของ runtime ในกรณีเลวร้ายที่สุดเท่ากับความซับซ้อนโดยธรรมชาติของปัญหาที่มันแก้ อัลกอริทึมเช่นนี้สามารถถือได้ว่าเป็นจอกศักดิ์สิทธิ์ (Holy Grail) สำหรับปัญหานั้น และเช่นเดียวกับ Indiana Jones ใน The Last Crusade John von Neumann พบจอกศักดิ์สิทธิ์ของการจัดเรียงใน mergesort 6
สิ่งสำคัญคือต้องแยกความแตกต่างระหว่าง runtime ของอัลกอริทึมกับความซับซ้อนของปัญหา อย่างหลังบอกว่าคำตอบที่ถูกต้องต้องใช้ อย่างน้อย จำนวนขั้นตอนนั้น ในทางตรงกันข้าม runtime ของอัลกอริทึมบอกว่าอัลกอริทึมเฉพาะนั้นใช้ อย่างมาก จำนวนขั้นตอนนั้น ข้อความเกี่ยวกับความซับซ้อนขั้นต่ำของปัญหาเรียกว่า lower bound หรือขอบเขตล่างของปัญหา ขอบเขตล่างให้การประมาณว่างานหนึ่งต้องใช้ความพยายามขั้นต่ำเท่าใด และดังนั้นจึงแสดงถึงความซับซ้อนโดยธรรมชาติของปัญหา มันคล้ายกับระยะทางเรขาคณิตระหว่างสองจุด ซึ่งเป็นขอบเขตล่างสำหรับเส้นทางใด ๆ ที่เชื่อมต่อจุดทั้งสอง เส้นทางดังกล่าวอาจยาวกว่าระยะทางเนื่องจากสิ่งกีดขวาง แต่มันไม่สามารถสั้นกว่าระยะทางได้ ความผิดหวังที่อาจเกิดขึ้นเกี่ยวกับขอบเขตล่างของการจัดเรียงและข้อจำกัดที่เกี่ยวข้องของอัลกอริทึมการจัดเรียงควรถูกชดเชยด้วยความเข้าใจอย่างลึกซึ้งที่ความรู้นี้ให้เกี่ยวกับปัญหาการจัดเรียง เปรียบเทียบสิ่งนี้กับผลลัพธ์ที่คล้ายกันในสาขาวิชาอื่น ๆ ตัวอย่างเช่น ในฟิสิกส์ เรารู้ว่าเราไม่สามารถเดินทางได้เร็วกว่าแสง และเราไม่สามารถสร้างพลังงานจากความว่างเปล่า
แต่เรามั่นใจได้อย่างไรเกี่ยวกับขอบเขตล่างของการจัดเรียง? บางทีอาจมีอัลกอริทึมที่ไม่มีใครเคยคิดมาก่อนที่ทำงานได้เร็วกว่าเวลาแบบ linearithmic การพิสูจน์สิ่งที่เป็นเชิงลบนั้นไม่ใช่เรื่องง่าย เพราะมันต้องการให้เราแสดงให้เห็นว่าอัลกอริทึมใด ๆ ไม่ว่าจะมีอยู่แล้วหรือยังไม่ถูกประดิษฐ์ขึ้น จะต้องดำเนินการตามจำนวนขั้นตอนต่ำสุดที่กำหนด ข้อโต้แย้งสำหรับขอบเขตล่างของการจัดเรียงคือการนับจำนวน list ที่เป็นไปได้สำหรับความยาวเฉพาะ 7 และแสดงให้เห็นว่าจำนวนการเปรียบเทียบที่จำเป็นในการระบุ list ที่จัดเรียงแล้วนั้นเป็นแบบ linearithmic 8 เนื่องจากทุกอัลกอริทึมต้องทำการเปรียบเทียบในจำนวนขั้นต่ำนี้ จึงสรุปได้ว่าอัลกอริทึมใด ๆ ต้องใช้จำนวนขั้นตอนอย่างน้อยแบบ linearithmic ซึ่งพิสูจน์ขอบเขตล่างได้
การใช้เหตุผลเกี่ยวกับ runtime ของอัลกอริทึมและขอบเขตล่างนั้นมีสมมติฐานเกี่ยวกับความสามารถของคอมพิวเตอร์ที่กำลังดำเนินการอัลกอริทึม ตัวอย่างเช่น สมมติฐานทั่วไปคือขั้นตอนของอัลกอริทึมถูกดำเนินการตามลำดับ และใช้หนึ่งหน่วยเวลาในการดำเนินการหนึ่งขั้นตอนการคำนวณ สมมติฐานเหล่านี้รองรับการวิเคราะห์อัลกอริทึมการจัดเรียงที่กล่าวถึงในบทนี้ อย่างไรก็ตาม ถ้าเราสมมติว่าเราสามารถเปรียบเทียบแบบขนานได้ การวิเคราะห์จะเปลี่ยนไป และเราจะได้ผลลัพธ์ที่แตกต่างกันสำหรับ runtime และขอบเขตล่าง
Computation Preservation (การเก็บรักษาการคำนวณ)
ดูเหมือนว่า Indiana Jones ค่อนข้างเป็นระบบเกี่ยวกับการออกผจญภัย: เขามักจะเก็บหมวกและแส้ใส่กระเป๋าเดินทางของเขาเสมอ แต่แทนที่จะวางแผนอย่างครอบคลุมทุกขั้นตอน เขาสามารถเข้าใกล้การผจญภัยโดยการกำหนดขั้นตอนต่อไปของเขาเพียงก่อนที่จะจำเป็นต้องทำ ทั้งสองวิธีคือการวางแผนล่วงหน้าและการใช้ชีวิตอยู่กับปัจจุบัน ต่างก็มีข้อดีและข้อเสียของตัวเอง การเดินทางไปขั้วโลกเหนือต้องการเสื้อผ้าและอุปกรณ์ที่แตกต่างจากการเดินทางไปแอมะซอน ในที่นี้การวางแผนล่วงหน้าดูเหมือนเป็นความคิดที่ดี ในทางกลับกัน สถานการณ์ที่เปลี่ยนแปลงอาจทำให้แผนก่อนหน้านี้ล้าสมัยและทำให้ความพยายามในการวางแผนไร้ประโยชน์ โดยเฉพาะอย่างยิ่ง ในระหว่างการผจญภัย สิ่งที่ไม่คาดคิดอาจเกิดขึ้น ซึ่งมักต้องดำเนินการที่แตกต่างไปจากที่คาดการณ์ไว้
หากกลยุทธ์ของ Indiana Jones ในการหาหีบพันธสัญญาคือการกำหนดการกระทำถัดไปเมื่อจำเป็นเท่านั้น เขาก็จะทำ selection sort อยู่จริง ๆ และจะค้นหาองค์ประกอบที่เล็กที่สุดในบรรดาการกระทำที่เหลืออยู่เสมอ เพราะ เล็กที่สุด ในที่นี้หมายถึง "ต้องมาก่อนการกระทำอื่นทั้งหมด" ดังที่ได้กล่าวไปแล้ว นี่ไม่มีประสิทธิภาพมากนัก เนื่องจาก selection sort เป็นอัลกอริทึมแบบ quadratic Indiana สามารถทำได้ดีขึ้นมากถ้าเขาสร้างแผนล่วงหน้าโดยใช้อัลกอริทึมการจัดเรียงแบบ linearithmic เช่น mergesort กลยุทธ์การคำนวณข้อมูลล่วงหน้านี้เรียกว่า precomputation หรือการคำนวณล่วงหน้า ในกรณีของแผนสำหรับการหาหีบพันธสัญญา ข้อมูลที่คำนวณล่วงหน้าไม่ใช่ชุดของขั้นตอนแต่ละขั้น แต่เป็นการจัดเรียงขั้นตอนในลำดับที่ถูกต้อง

ข้อมูลเกี่ยวกับลำดับถูกเก็บไว้ใน list ที่จัดเรียงแล้ว ประเด็นสำคัญของ precomputation คือการใช้ความพยายามในการคำนวณในเวลาหนึ่งและใช้ผลลัพธ์ที่คำนวณได้ในเวลาต่อมา ผลลัพธ์ที่คำนวณล่วงหน้าถูกเก็บรักษาไว้ใน data structure — ในกรณีนี้คือ list ที่จัดเรียงแล้ว list ที่จัดเรียงนี้ทำหน้าที่เหมือนแบตเตอรี่เชิงคำนวณที่สามารถชาร์จได้ผ่านการจัดเรียง runtime ที่ใช้โดยอัลกอริทึมเพื่อสร้าง list ที่จัดเรียงนั้นเปรียบเสมือนพลังงานที่ใช้ในการชาร์จแบตเตอรี่ data structure พลังงานนี้สามารถใช้เพื่อขับเคลื่อนการคำนวณ เช่น การหาองค์ประกอบที่เล็กที่สุดถัดไป ในที่นี้ การขับเคลื่อนหมายถึงการเร่งความเร็ว: หากไม่มีแบตเตอรี่ list ที่จัดเรียงแล้ว การหาองค์ประกอบที่เล็กที่สุดถัดไปต้องใช้เวลาแบบ linear แต่เมื่อมีแบตเตอรี่ จะใช้เวลาเพียงค่าคงที่ (constant time)
บางวิธีมีประสิทธิภาพมากกว่าวิธีอื่นในการชาร์จแบตเตอรี่ data structure ซึ่งสะท้อนให้เห็นใน runtime ที่แตกต่างกันของอัลกอริทึมการจัดเรียงต่าง ๆ ตัวอย่างเช่น insertion sort มีประสิทธิภาพน้อยกว่า mergesort และความจริงที่ว่า mergesort เป็นอัลกอริทึมการจัดเรียงที่เหมาะสมที่สุดหมายความว่ามีวิธีที่มีประสิทธิภาพมากที่สุดในการชาร์จแบตเตอรี่ list ที่จัดเรียงแล้ว ซึ่งแตกต่างจากแบตเตอรี่ไฟฟ้าที่พลังงานสามารถใช้ได้เพียงครั้งเดียว แบตเตอรี่ data structure มีคุณสมบัติที่ดีที่ว่าเมื่อชาร์จแล้ว สามารถคายประจุซ้ำแล้วซ้ำอีกโดยไม่ต้องชาร์จใหม่ คุณสมบัตินี้เป็นข้อได้เปรียบที่สำคัญของการคำนวณล่วงหน้า สถานการณ์ที่คาดว่าจะสามารถใช้ data structure ซ้ำ ๆ ได้เป็นแรงจูงใจให้ลงทุนในการคำนวณล่วงหน้า เพราะต้นทุนสามารถเฉลี่ยออกมาได้หลายครั้ง ในทางกลับกัน แบตเตอรี่ data structure ต้องชาร์จเต็มจึงจะทำงานได้อย่างถูกต้อง list ที่เกือบจะเรียงลำดับแล้วนั้นไม่เพียงพอ เพราะมันไม่รับประกันว่าองค์ประกอบที่เล็กที่สุดจะอยู่ด้านหน้า และดังนั้นจึงอาจให้ผลลัพธ์ที่ไม่ถูกต้อง โดยพื้นฐานแล้วนี่หมายความว่าแบตเตอรี่ data structure มีสองสถานะ: มันถูกชาร์จเต็มและมีประโยชน์ หรือไม่ก็ไม่
การคำนวณล่วงหน้าดูเหมือนจะเป็นความคิดที่ดี — เหมือนกระรอกที่เก็บถั่วไว้กินในฤดูหนาว อย่างไรก็ตาม มีหลายสถานการณ์ที่ไม่ชัดเจนว่าความพยายามในการคำนวณล่วงหน้าจะคุ้มค่าหรือไม่ เรารู้หลายกรณีที่การกระทำแต่เนิ่น ๆ สามารถเป็นประโยชน์ แต่มันไม่ได้รับประกัน และอาจกลายเป็นข้อเสียได้ ถ้าคุณซื้อตั๋วเครื่องบินล่วงหน้าหรือจองโรงแรมในอัตราที่ไม่สามารถคืนเงินได้ คุณอาจได้ข้อเสนอที่ดี แต่ถ้าคุณป่วยและไม่สามารถเดินทางได้ คุณอาจเสียเงินและแย่กว่าการถอยหลังรอซื้อ
ในกรณีเช่นนี้ คุณค่าของการกระทำแต่เนิ่น ๆ หรือการคำนวณล่วงหน้า (precomputation) ถูกตั้งคำถามด้วยความไม่แน่นอนเกี่ยวกับอนาคต เนื่องจากประโยชน์ของการคำนวณล่วงหน้าขึ้นอยู่กับผลลัพธ์เฉพาะของเหตุการณ์ในอนาคต มันสะท้อนถึงทัศนคติเชิงคำนวณที่มองโลกในแง่ดีด้วยมุมมองที่มั่นใจต่ออนาคต แต่ถ้าคุณไม่เชื่อมั่นเกี่ยวกับอนาคตล่ะ? คุณอาจคิดว่าคนที่ยื่นแบบแสดงรายการภาษีแต่เนิ่น ๆ เป็นพวกชอบทรมานตัวเอง และคุณมักจะเลื่อนออกไปจนถึงวันที่ 14 เมษายน เพราะกรมสรรพากรอาจถูกยุบเลิกวันไหนก็ได้ หรือคุณอาจตายก่อน อย่างไรก็ตาม ถ้าคุณมั่นใจเหมือน Ben Franklin ว่าภาษีนั้นแน่นอนเท่ากับความตาย การคำนวณล่วงหน้าก็อาจเป็นสิ่งที่รอบคอบ
ทัศนคติที่ไม่เชื่อมั่นต่ออนาคตเรียกร้องกลยุทธ์ที่แตกต่างอย่างสิ้นเชิงสำหรับการจัดตารางการคำนวณ กล่าวคือ กลยุทธ์ที่พยายามเลื่อนการดำเนินการที่มีต้นทุนสูงออกไปให้นานที่สุดเท่าที่จะทำได้ จนกระทั่งไม่สามารถหลีกเลี่ยงได้อีกต่อไป ความหวังหรือความคาดหวังคือบางสิ่งอาจเกิดขึ้นที่ทำให้การดำเนินการที่มีต้นทุนสูงนั้นล้าสมัย และดังนั้นจึงประหยัด runtime (และทรัพยากรอื่น ๆ ที่อาจเกิดขึ้น) ในชีวิตจริงพฤติกรรมนี้เรียกว่าการผัดวันประกันพรุ่ง ในวิทยาการคอมพิวเตอร์เรียกว่า lazy evaluation หรือการประเมินแบบขี้เกียจ Lazy evaluation สามารถประหยัดความพยายามในการคำนวณเมื่อใดก็ตามที่ข้อมูลที่ได้จากการคำนวณที่บันทึกไว้ไม่จำเป็นอีกต่อไป ในกรณีของการผจญภัยของ Indiana Jones มันเกิดขึ้นบ่อยครั้งที่แผนเริ่มต้นต้องถูกเปลี่ยนแปลงหรือละทิ้งเพราะเหตุการณ์หรือความยุ่งยากที่ไม่คาดคิด ในกรณีเช่นนี้ ความพยายามทั้งหมดที่ใช้ในการสร้างแผนสูญเปล่า และสามารถประหยัดได้โดยไม่สร้างแผนตั้งแต่แรก
ในขณะที่คติประจำใจของผู้สนับสนุนการคำนวณล่วงหน้าคือ "เย็บตอนนี้เพื่อประหยัดเวลาเก้าทีหลัง" หรือ "นกที่ตื่นเช้าได้หนอน" ผู้สนับสนุน lazy evaluation อาจตอบว่า "ใช่ แต่หนูตัวที่สองได้ชีส" ในขณะที่ lazy evaluation ดูน่าสนใจในคำมั่นสัญญาว่าจะไม่เสียความพยายาม แต่มันเป็นปัญหาที่เมื่อการกระทำที่หลีกเลี่ยงไม่ได้ใช้เวลานานกว่าที่ควรจะเป็นภายใต้การคำนวณล่วงหน้า หรือแย่กว่านั้น นานกว่าเวลาที่มีอยู่ โดยเฉพาะอย่างยิ่ง เมื่อการกระทำที่ถูกเลื่อนหลายอย่างถึงกำหนดพร้อมกัน สิ่งนี้อาจเป็นปัญหาทรัพยากรที่ร้ายแรง ดังนั้น กลยุทธ์โดยรวมที่สมเหตุสมผลกว่าคือการกระจายงานอย่างสม่ำเสมอในช่วงเวลา แม้ว่าสิ่งนี้อาจเสียความพยายามบางส่วนในการคำนวณล่วงหน้า แต่มันหลีกเลี่ยงวิกฤตที่กลยุทธ์ lazy evaluation อาจนำมา