ชนิดข้อมูลที่พูดถึงใน บทที่ 4 จับรูปแบบการเข้าถึงชุดข้อมูลที่เฉพาะเจาะจง เนื่องจากชุดข้อมูลสามารถมีขนาดใหญ่มาก ข้อควรพิจารณาในทางปฏิบัติที่สำคัญคือวิธีจัดการอย่างมีประสิทธิภาพ เราได้เห็นแล้วว่าโครงสร้างข้อมูลที่แตกต่างกันสามารถรองรับประสิทธิภาพของการดำเนินการเฉพาะได้ และมีความต้องการพื้นที่ที่แตกต่างกัน แม้ว่าการสร้างและการแปลงชุดข้อมูลจะเป็นงานที่สำคัญ แต่การค้นหารายการในชุดข้อมูลน่าจะเป็นการดำเนินการที่จำเป็นบ่อยที่สุด
เราค้นหาสิ่งต่าง ๆ ตลอดเวลา บ่อยครั้งที่สิ่งนี้เกิดขึ้นโดยไม่รู้ตัว แต่บางครั้งเราก็รู้สึกได้อย่างเจ็บปวด เช่น เมื่อกิจกรรมธรรมดา ๆ อย่างการหากุญแจรถกลายเป็นการค้นหาที่แสนทรมาน ยิ่งมีสถานที่ให้ค้นหาและสิ่งของให้ตรวจสอบมากเท่าไหร่ การค้นหาก็ยิ่งยากขึ้นเท่านั้น และเรามักจะสะสมสิ่งของมากมายตลอดหลายปี—เพราะท้ายที่สุดแล้ว เราก็เป็นลูกหลานของนักล่าและผู้เก็บเกี่ยว นอกจากของสะสมอย่างแสตมป์ เหรียญ หรือการ์ดกีฬาแล้ว เรายังกักตุนหนังสือ รูปภาพ หรือเสื้อผ้าไว้มากมายเมื่อเวลาผ่านไป บางครั้งสิ่งนี้เกิดขึ้นเป็นผลพลอยได้จากงานอดิเรกหรือความหลงใหล—ผมรู้จักคนที่คลั่งไคล้การปรับปรุงบ้านหลายคนที่สะสมเครื่องมือไว้มากมายน่าประทับใจ
ถ้าชั้นหนังสือของคุณถูกจัดเรียงตามตัวอักษรหรือตามหัวข้อ หรือถ้ารูปภาพของคุณถูกจัดเก็บในรูปแบบอิเล็กทรอนิกส์และมีแท็กระบุสถานที่และเวลา การหาหนังสือหรือรูปภาพเล่มใดเล่มหนึ่งอาจเป็นเรื่องง่าย แต่ถ้าจำนวนสิ่งของมีมากและขาดรูปแบบการจัดระเบียบใด ๆ การค้นหาเช่นนั้นอาจกลายเป็นเรื่องยากลำบาก
สถานการณ์ยิ่งแย่ลงไปอีกเมื่อพูดถึงข้อมูลที่จัดเก็บแบบอิเล็กทรอนิกส์ เนื่องจากเราสามารถเข้าถึงพื้นที่จัดเก็บได้ไม่จำกัด ขนาดของข้อมูลที่จัดเก็บจึงเติบโตอย่างรวดเร็ว ตัวอย่างเช่น จากข้อมูลของ YouTube มีวิดีโอความยาว 300 ชั่วโมงถูกอัปโหลดไปยังไซต์ทุกนาที 1
การค้นหาเป็นปัญหาที่พบได้ทั่วไปในชีวิตจริง และยังเป็นหัวข้อสำคัญในวิทยาการคอมพิวเตอร์อีกด้วย อัลกอริทึมและโครงสร้างข้อมูลสามารถช่วยเร่งกระบวนการค้นหาได้อย่างมาก และสิ่งที่ใช้ได้กับข้อมูลบางครั้งก็สามารถช่วยในการจัดเก็บและค้นหาสิ่งของทางกายภาพได้เช่นกัน มีวิธีง่าย ๆ วิธีหนึ่งที่ช่วยให้คุณไม่ต้องหากุญแจรถอีกต่อไป—ถ้าคุณทำตามวิธีนั้นอย่างพิถีพิถัน
The Key to Fast Search (กุญแจสู่การค้นหาที่รวดเร็ว)
ในเรื่อง The Last Crusade อินเดียน่า โจนส์เริ่มต้นการค้นหาครั้งใหญ่สองครั้ง ครั้งแรกเขาพยายามหาพ่อของเขา เฮนรี่ โจนส์ ซีเนียร์ จากนั้นทั้งคู่ก็ร่วมกันค้นหาจอกศักดิ์สิทธิ์ ในฐานะศาสตราจารย์ด้านโบราณคดี อินเดียน่า โจนส์รู้เรื่องการค้นหาไม่น้อย ใน-betweenการบรรยายครั้งหนึ่ง เขาอธิบายให้นักเรียนฟังว่า
โบราณคดีคือการค้นหาความจริง
การค้นหาสิ่งของทางโบราณคดี—หรือบุคคลในเรื่องนั้น—ทำงานอย่างไร ถ้าทราบตำแหน่งของสิ่งที่ต้องการ ก็ไม่จำเป็นต้องค้นหาแน่นอน เพียงแค่ไปที่นั่นแล้วเจอมัน มิฉะนั้น กระบวนการค้นหาขึ้นอยู่กับสองสิ่ง: ปริภูมิการค้นหา (search space) และ เบาะแส หรือ กุญแจ ที่สามารถจำกัดปริภูมิการค้นหาให้แคบลง
ใน The Last Crusade อินเดียน่า โจนส์ได้รับสมุดบันทึกของพ่อซึ่งมีข้อมูลเกี่ยวกับจอกศักดิ์สิทธิ์ทางไปรษณีย์จากเวนิส ซึ่งทำให้เขาเริ่มต้นการค้นหาที่นั่น ต้นทางของสมุดบันทึกเป็นเบาะแสสำหรับอินเดียน่า โจนส์ที่จำกัดปริภูมิการค้นหาเริ่มต้นลงอย่างมาก—จากทั่วทั้งโลกลงมาเหลือเพียงเมืองเดียว ในตัวอย่างนี้ ปริภูมิการค้นหาคือปริภูมิทางเรขาคณิตสองมิติตามตัวอักษร แต่โดยทั่วไปแล้วคำว่า search space หมายถึงสิ่งที่คล้ายนามธรรมมากกว่า ตัวอย่างเช่น โครงสร้างข้อมูลใด ๆ สำหรับแทนชุดของรายการสามารถมองได้เป็น search space ที่เราสามารถค้นหารายการเฉพาะได้ รายชื่อผู้ต้องสงสัยของเชอร์ล็อก โฮล์มส์ก็เป็น search space แบบหนึ่งที่เราสามารถค้นหาชื่อเฉพาะได้
ลิสต์เหมาะกับการค้นหามากแค่ไหน? ดังที่ผมได้กล่าวถึงใน บทที่ 4 ในกรณีที่แย่ที่สุด เราต้องตรวจสอบทุก element ในลิสต์ก่อนที่จะพบ element ที่ต้องการหรือรู้ว่า element นั้นไม่ได้อยู่ในลิสต์ นั่นหมายความว่าการค้นหาผ่านลิสต์ไม่ได้ใช้เบาะแสในการจำกัดปริภูมิการค้นหาอย่างมีประสิทธิภาพ
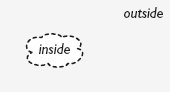
เพื่อทำความเข้าใจว่าทำไมลิสต์ถึงไม่ใช่โครงสร้างข้อมูลที่ดีสำหรับการค้นหา การพิจารณาว่าเบาะแสทำงานอย่างไรให้ละเอียดขึ้นจะเป็นประโยชน์ ในปริภูมิสองมิติ เบาะแสจะให้ขอบเขตที่แยก "ภายนอก" ซึ่งรู้ว่า ไม่มี element ที่ต้องการออกจาก "ภายใน" ซึ่งอาจมี element นั้นอยู่ 2 ในทำนองเดียวกัน เพื่อให้โครงสร้างข้อมูลใช้ประโยชน์จากเบาะแสได้ มันต้องมีแนวคิดเรื่องขอบเขตที่สามารถแยกส่วนต่าง ๆ ของโครงสร้างข้อมูลออกจากกัน และจำกัดการค้นหาให้อยู่เพียงส่วนใดส่วนหนึ่ง ยิ่งไปกว่านั้น เบาะแสหรือกุญแจคือข้อมูลที่เชื่อมโยงกับวัตถุที่กำลังค้นหา กุญแจต้องสามารถระบุขอบเขตระหว่าง element ที่เกี่ยวข้องกับการค้นหาปัจจุบันกับ element ที่ไม่เกี่ยวข้องได้
ในลิสต์ แต่ละ element คือขอบเขตที่แยก element ที่อยู่ก่อนหน้ามันออกจาก element ที่ตามหลังมัน อย่างไรก็ตาม เนื่องจากเราไม่เคยเข้าถึง element ที่อยู่ตรงกลางของลิสต์โดยตรง และมักจะ traverse ลิสต์จากปลายด้านหนึ่งไปยังอีกด้านหนึ่ง element ของลิสต์จึงไม่สามารถแยกภายนอกออกจากภายในได้อย่างมีประสิทธิภาพ ลองพิจารณา element แรกในลิสต์ มันไม่ได้ตัด element ใดออกจากการค้นหาเลยนอกจากตัวมันเอง เพราะถ้ามันไม่ใช่ element ที่เรากำลังมองหา เราก็ต้องค้นหาต่อผ่าน element ที่เหลือทั้งหมดของลิสต์ แต่แล้วเมื่อเราตรวจสอบ element ที่สองของลิสต์ เราก็เจอสถานการณ์เดียวกัน ถ้า element ที่สองไม่ใช่สิ่งที่เรากำลังมองหา เราก็ต้องค้นหาต่อผ่าน element ที่เหลือทั้งหมดอีกครั้ง แน่นอนว่า element ที่สองกำหนดให้ element แรกของลิสต์เป็น "ภายนอก" ซึ่งเราไม่ต้องตรวจสอบอีก แต่เนื่องจากเราได้ตรวจสอบมันไปแล้ว มันจึงไม่ช่วยประหยัดความพยายามในการค้นหา และเช่นเดียวกันกับทุก element ในลิสต์: "ภายนอก" ที่มันกำหนดนั้นต้องถูกตรวจสอบเพื่อที่จะไปถึง element นั้น
หลังจากมาถึงเวนิส อินเดียน่า โจนส์ก็ค้นหาต่อในห้องสมุด การค้นหาหนังสือในห้องสมุดเป็นตัวอย่างเชิงปฏิบัติที่ดีสำหรับแนวคิดเรื่องขอบเขตและกุญแจ เมื่อชื่อหนังสือถูกวางบนชั้นโดยจัดกลุ่มตามนามสกุลของผู้เขียน ชั้นแต่ละชั้นมักจะมีป้ายบอกชื่อผู้เขียนเล่มแรกและเล่มสุดท้ายบนชั้นนั้น ชื่อทั้งสองนี้กำหนดช่วงของนักเขียนที่มีหนังสืออยู่บนชั้นนั้น ชื่อทั้งสองนี้กำหนดขอบเขตที่แยกหนังสือจากนักเขียนที่อยู่ในช่วงออกจากหนังสืออื่น ๆ ทั้งหมด สมมติว่าเรากำลังพยายามหา The Hound of the Baskervilles ของ อาเธอร์ โคนัน ดอยล์ ในห้องสมุด เราสามารถใช้นามสกุลของผู้เขียนเป็นกุญแจเพื่อระบุชั้นที่มีช่วงชื่อครอบคลุมก่อน เมื่อพบแล้ว เราก็ค้นหาหนังสือต่อบนชั้นนั้น การค้นหานี้เกิดขึ้นในสองระยะ ระยะหนึ่งสำหรับหาชั้นหนังสือ และอีกระยะสำหรับหาหนังสือบนชั้นนั้น กลยุทธ์นี้ใช้ได้ดีเพราะมันแบ่งปริภูมิการค้นหาออกเป็นพื้นที่เล็ก ๆ ที่ไม่ทับซ้อนกัน (ชั้นหนังสือ) โดยใช้ขอบเขตของชื่อผู้เขียน
การค้นหาผ่านชั้นหนังสือสามารถทำได้หลายวิธี วิธีง่าย ๆ วิธีหนึ่งคือตรวจสอบทีละชั้นจนกว่าจะพบชั้นที่มีช่วงครอบคลุม Doyle วิธีนี้ถือว่าชั้นหนังสือเป็นลิสต์และมีข้อเสียเดียวกัน ในกรณีของ Doyle การค้นหาอาจใช้เวลาไม่นาน แต่ถ้าเรากำลังหาหนังสือของ Yeats ก็จะใช้เวลานานกว่ามาก มีคนน้อยมากที่จะเริ่มค้นหา Yeats ที่ชั้น A แต่จะเริ่มใกล้กับชั้น Z และหาชั้นที่ถูกต้องได้เร็วกว่า วิธีนี้ขึ้นอยู่กับสมมติฐานที่ว่าชั้นหนังสือทั้งหมดถูกจัดเรียงตามชื่อผู้เขียนของหนังสือที่อยู่บนชั้น และถ้ามี 26 ชั้น (สมมติว่าหนึ่งชั้นต่อหนึ่งตัวอักษร) ก็จะเริ่มหา Yeats ที่ชั้นที่ 25 และหา Doyle ที่ชั้นที่ 4 กล่าวอีกนัยหนึ่งคือ เราจะถือว่าชั้นหนังสือเป็น array ที่ถูก indexed ด้วยตัวอักษร และแต่ละ cell คือชั้นหนังสือ แน่นอนว่าไม่น่าเป็นไปได้ที่ห้องสมุดจะมี 26 ชั้นพอดี แต่วิธีนี้ปรับขนาดได้กับจำนวนชั้นเท่าใดก็ได้ เพียงแค่เริ่มค้นหา Yeats ในช่วงสุดท้ายหนึ่งในสิบสามของชั้นทั้งหมด ปัญหาของวิธีนี้คือจำนวนผู้เขียนที่ชื่อขึ้นต้นด้วยตัวอักษรเดียวกันนั้นแตกต่างกันอย่างมาก (มีผู้เขียนที่ชื่อขึ้นต้นด้วย S มากกว่า X ) กล่าวคือ การกระจายของหนังสือไม่เท่ากันในทุกชั้น และกลยุทธ์นี้จึงไม่แม่นยำ ดังนั้น โดยทั่วไปเราต้องเดินไปมาหน้าชั้นเพื่อหาชั้นเป้าหมาย การใช้ความรู้เกี่ยวกับการกระจายของชื่อผู้เขียนสามารถเพิ่มความแม่นยำของวิธีนี้ได้อย่างมาก แต่แม้แต่กลยุทธ์ง่าย ๆ ก็ใช้ได้ดีในทางปฏิบัติและมีประสิทธิภาพในการตัดชั้นจำนวนมากออกเป็น "ภายนอก" โดยไม่ต้องพิจารณาเลย
การค้นหาหนังสือภายในชั้นเดียวสามารถทำได้หลายวิธีเช่นกัน เราสามารถสแกนหนังสือทีละเล่ม หรือใช้กลยุทธ์ที่คล้ายกับวิธีหาชั้นหนังสือ โดยประมาณตำแหน่งของหนังสือตามตำแหน่งของเบาะแสในช่วงของผู้เขียนของชั้นนั้น ๆ โดยรวมแล้ว วิธีสองระยะใช้ได้ค่อนข้างดีและเร็วกว่าวิธีการแบบ naïve ที่ดูหนังสือทั้งหมดทีละเล่มมาก ผมได้ทำการทดลองและค้นหา The Hound of the Baskervilles ในห้องสมุดประชาชนคอร์แวลลิส ผมสามารถหาชั้นที่ถูกต้องได้ในห้าขั้นตอน และหาหนังสือบนชั้นนั้นได้ในอีกเจ็ดขั้นตอน ซึ่งเป็นการปรับปรุงที่ดีเมื่อเทียบกับวิธี naïve เมื่อพิจารณาว่าในขณะนั้นห้องสมุดมีหนังสือในส่วนนวนิยายสำหรับผู้ใหญ่ถึง 44,679 เล่มบน 36 ชั้น
การตัดสินใจของอินเดียน่า โจนส์ที่จะเดินทางไปเวนิสเพื่อตามหาพ่อของเขาก็ใช้กลยุทธ์ที่คล้ายกัน ในกรณีนี้ โลกถูกมองเป็น array ที่แต่ละ cell สอดคล้องกับภูมิภาคทางภูมิศาสตร์ซึ่งถูก indexed ด้วยชื่อเมือง ที่อยู่ผู้ส่งบนจดหมายที่มีสมุดบันทึกของเฮนรี่ โจนส์ ซีเนียร์ทำหน้าที่เป็นเบาะแสที่เลือก cell ที่ถูก indexed ด้วย "เวนิส" เพื่อค้นหาต่อ ในเวนิส การค้นหานำอินเดียน่า โจนส์ไปยังห้องสมุด ซึ่งเขาไม่ได้กำลังหาหนังสือ แต่มุ่งหาหลุมฝังศพของเซอร์ริชาร์ด อัศวินคนหนึ่งในสงครามครูเสดครั้งแรก เขาพบหลุมฝังศพหลังจากเหยียบกระเบื้องปูพื้นที่ทำเครื่องหมายด้วย X ซึ่งไม่ใช่เรื่องปราศจากการประชดประชัน เมื่อเทียบกับคำประกาศก่อนหน้านี้ของเขาที่บอกนักเรียนว่า
X ไม่เคย ไม่เคยทำเครื่องหมายตำแหน่งเลย
กุญแจสู่การค้นหาที่รวดเร็วคือการมีโครงสร้างที่ช่วยให้จำกัดปริภูมิการค้นหาให้แคบลงได้อย่างมีประสิทธิภาพ ยิ่ง "ภายใน" ที่ถูกระบุโดยกุญแจมีขนาดเล็กเท่าไหร่ ก็ยิ่งดี เพราะช่วยให้การค้นหาลู่เข้าสู่คำตอบได้เร็วขึ้น ในกรณีของการค้นหาหนังสือ มีสองระยะการค้นหาที่คั่นด้วยขั้นตอนการจำกัดให้แคบลงครั้งใหญ่หนึ่งครั้ง
Survival by Boggle (การอยู่รอดด้วย Boggle)
การค้นหามักมาในรูปแบบปลอมตัวและในสถานการณ์ที่ไม่คาดคิดที่สุด ในช่วงท้ายของ The Last Crusade อินเดียน่า โจนส์มาถึงวิหารแห่งดวงอาทิตย์ ซึ่งเขาต้องผ่านความท้าทายสามอย่างก่อนจะเข้าไปในห้องที่มีจอกศักดิ์สิทธิ์ได้ ความท้าทายที่สองต้องการให้เขาข้ามพื้นกระเบื้องที่อยู่เหนือเหว ปัญหาคือมีเพียงบางกระเบื้องที่ปลอดภัย ในขณะที่กระเบื้องอื่น ๆ จะพังและนำไปสู่ความตายอันน่าสยดสยองเมื่อเหยียบ พื้นประกอบด้วยกระเบื้องประมาณ 50 แผ่น เรียงเป็นกริดที่ไม่เป็นระเบียบ แต่ละแผ่นมีตัวอักษรกำกับอยู่ ชีวิตของนักโบราณคดีนั้นซับซ้อน: วันหนึ่งคุณต้องทุบกระเบื้องปูพื้นเพื่อความคืบหน้า อีกวันคุณต้องหลีกเลี่ยงมันไม่ให้ได้
การหากระเบื้องที่ปลอดภัยที่จะเหยียบนั้นไม่ใช่เรื่องง่าย เพราะถ้าไม่มีข้อจำกัดเพิ่มเติม จำนวนความเป็นไปได้นั้นมหาศาล: มากกว่าหนึ่งพันล้านล้าน—1 ตามด้วยศูนย์ 15 ตัว เบาะแสในการหาลำดับกระเบื้องที่เป็นไปได้ซึ่งนำไปสู่อีกฝั่งของพื้นอย่างปลอดภัยคือ กระเบื้องต้องสะกดชื่อ Iehova แม้ว่าข้อมูลนี้จะแก้ปริศนาได้โดยพื้นฐาน แต่การระบุลำดับกระเบื้องที่ถูกต้องยังคงต้องใช้ความพยายามบ้าง น่าประหลาดใจที่มันเกี่ยวข้องกับ การค้นหา ที่ค่อย ๆ จำกัดพื้นที่ของความเป็นไปได้ให้แคบลงอย่างเป็นระบบ

งานนี้คล้ายกับการเล่น Boggle ซึ่งเป้าหมายคือการหาสายอักขระที่เชื่อมต่อกันบนกริดที่ประกอบเป็นคำ 3 ภารกิจของอินเดียน่า โจนส์ดูเหมือนจะง่ายกว่ามากเพราะเขารู้คำศัพท์แล้ว อย่างไรก็ตาม ใน Boggle อักขระที่ต่อเนื่องกันต้องอยู่บนกระเบื้องที่อยู่ติดกัน ซึ่งไม่ใช่ข้อจำกัดสำหรับความท้าทายบนพื้นกระเบื้อง และทำให้อินเดียน่า โจนส์มีความเป็นไปได้มากขึ้นที่ต้องพิจารณา และทำให้ยากขึ้นอีกครั้ง
เพื่ออธิบายปัญหาการค้นหาที่ต้องแก้ สมมติให้ง่ายว่าพื้นกระเบื้องประกอบด้วยหกแถว แต่ละแถวมีตัวอักษรแปดตัวที่แตกต่างกัน ซึ่งให้กริดทั้งหมด 48 กระเบื้อง ถ้าเส้นทางที่ถูกต้องประกอบด้วยหนึ่งกระเบื้องในแต่ละแถว ก็จะมี 8 × 8 × 8 × 8 × 8 × 8 = 262,144 เส้นทางที่เป็นไปได้ผ่านชุดค่าผสมของกระเบื้องทั้งหมดในหกแถว ในจำนวนนี้ มีเพียงเส้นทางเดียวที่ใช้ได้
แล้วอินเดียน่า โจนส์หาเส้นทางได้อย่างไร? ด้วยการใช้คำใบ้นำทาง เขาหากระเบื้องที่มีตัวอักษร I ในแถวแรกและเหยียบลงไป การระบุนี้เป็นกระบวนการค้นหาในตัวเองที่เกี่ยวข้องกับหลายขั้นตอน ถ้าตัวอักษรบนกระเบื้องไม่ได้เรียงตามลำดับตัวอักษร อินเดียน่า โจนส์ต้องดูทีละแผ่นจนกว่าจะเจอกระเบื้องที่มีตัวอักษร I จากนั้นเขาก็เหยียบลงไป และค้นหากระเบื้องที่มีตัวอักษร e ในแถวที่สองต่อไปเรื่อย ๆ
ถ้าการค้นหาทีละอันทำให้คุณนึกถึงการค้นหา element ในลิสต์ คุณคิดถูกแล้ว นี่คือสิ่งที่เกิดขึ้นจริง ๆ ข้อแตกต่างคือการค้นหาในลิสต์ถูกนำมาใช้ซ้ำ ๆ สำหรับแต่ละแถว นั่นคือ สำหรับแต่ละตัวอักษรของคำใบ้ และนี่คือจุดที่พลังของวิธีนี้อยู่ ลองพิจารณาว่าเกิดอะไรขึ้นกับปริภูมิการค้นหา นั่นคือ เซตของเส้นทางที่เป็นไปได้ทั้งหมด 262,144 เส้นทางข้ามกริดกระเบื้อง แต่ละกระเบื้องในแถวแรกระบุจุดเริ่มต้นที่แตกต่างกัน ซึ่งสามารถต่อยอดได้ 8 × 8 × 8 × 8 × 8 = 32,768 วิธี โดยการเลือกชุดค่าผสมของตัวอักษรจากห้าแถวที่เหลือ เมื่ออินเดียน่า โจนส์มองกระเบื้องแผ่นแรก ซึ่งมีป้าย เช่น K แน่นอนว่าเขาจะไม่เหยียบมัน เพราะมันไม่ตรงกับ I ที่ต้องการ การตัดสินใจครั้งเดียวนี้ได้กำจัดเส้นทางทั้งหมด 32,768 เส้นทางออกจากปริภูมิการค้นหาในคราวเดียว นั่นคือ เส้นทางทั้งหมดที่เกิดจากการเริ่มต้นด้วยกระเบื้อง K และการลดลงแบบเดียวกันก็เกิดขึ้นกับทุกกระเบื้องที่ถูกปฏิเสธในแถวแรก
เมื่ออินเดียน่า โจนส์ไปถึงกระเบื้องที่ถูกต้อง การลดลงของปริภูมิการค้นหาก็ยิ่งน่าทึ่งมากขึ้น เพราะทันทีที่เขาเหยียบกระเบื้องนั้น กระบวนการตัดสินใจสำหรับแถวแรกก็เสร็จสมบูรณ์ และปริภูมิการค้นหาจะลดลงทันทีเหลือ 32,768 เส้นทางที่สามารถเกิดขึ้นกับห้าแถวที่เหลือ โดยรวมแล้ว ด้วยการตัดสินใจไม่เกินเจ็ดครั้ง (ซึ่งจำเป็นเมื่อกระเบื้อง I มาเป็นอันดับสุดท้าย) อินเดียน่า โจนส์ได้ลดปริภูมิการค้นหาลงแปดเท่า จากนั้นเขาก็ดำเนินการต่อกับแถวที่สองของกระเบื้องและตัวอักษร e อีกครั้ง ปริภูมิการค้นหาลดลงแปดเท่าเหลือ 4,096 ด้วยการตัดสินใจไม่เกินเจ็ดครั้ง เมื่ออินเดียน่า โจนส์ไปถึงแถวสุดท้าย ก็เหลือเส้นทางที่เป็นไปได้เพียงแปดเส้นทาง และอีกครั้งด้วยการตัดสินใจไม่เกินเจ็ดครั้ง เขาก็สามารถทำเส้นทางให้สมบูรณ์ได้ ในกรณีที่แย่ที่สุด การค้นหานี้ต้องใช้ 6 × 7 = 42 "ขั้นตอน" (มีเพียงหกก้าวตามตัวอักษร)—เป็นวิธีที่มีประสิทธิภาพอย่างน่าทึ่งในการหาเส้นทางหนึ่งเส้นทางจาก 262,144 เส้นทาง
อาจไม่ชัดเจนนัก แต่ความท้าทายที่อินเดียน่า โจนส์เอาชนะได้มีความคล้ายคลึงกับของฮันเซลกับเกรเทล ในทั้งสองกรณี ตัวละครหลักต้องหาเส้นทางไปสู่ความปลอดภัย และในทั้งสองกรณี เส้นทางประกอบด้วยลำดับของสถานที่ที่มีเครื่องหมาย—ในกรณีของฮันเซลกับเกรเทลคือก้อนกรวด ในกรณีของอินเดียน่า โจนส์คือตัวอักษร การค้นหาสถานที่ถัดไปในเส้นทางนั้นแตกต่างกัน: ฮันเซลกับเกรเทลแค่ต้องหาก้อนกรวดก้อนใดก็ได้ (ถึงแม้พวกเขาต้องแน่ใจว่าจะไม่กลับไปหาก้อนกรวดเดิม) ในขณะที่อินเดียน่า โจนส์ต้องหาตัวอักษรเฉพาะ ตัวอย่างทั้งสองเน้นย้ำถึงบทบาทของการแทนค่า (representation) ในการคำนวณอีกครั้ง ความท้าทายของอินเดียน่า โจนส์แสดงให้เห็นโดยเฉพาะว่าลำดับของ signifier (ตัวอักษร) สำหรับกระเบื้องแต่ละแผ่นนั้นเป็น signifier อีกตัวหนึ่ง (คำว่า Iehova ) สำหรับเส้นทางหนึ่ง นอกจากนี้ ข้อเท็จจริงที่ว่าคำว่า Iehova แทนเส้นทางหนึ่งนั้นแสดงให้เห็นว่าการคำนวณที่เพียงแค่ค้นหาคำศัพท์นั้นกลายเป็นสิ่งที่มีความหมายและสำคัญในโลกแห่งความเป็นจริงได้อย่างไร
วิธีที่อินเดียน่า โจนส์หาคำใบ้บนกริดนั้นตรงกับวิธีการค้นหาคำในพจนานุกรมอย่างมีประสิทธิภาพ: ขั้นแรกจำกัดกลุ่มของหน้าที่มีคำที่ขึ้นต้นด้วยตัวอักษรเดียวกับคำใบ้ จากนั้นจำกัดกลุ่มของหน้าเพิ่มเติมให้เหลือเฉพาะหน้าที่ตรงกับตัวอักษรตัวแรกและตัวที่สอง และต่อไปเรื่อย ๆ จนกว่าจะพบคำนั้น
เพื่อให้เข้าใจโครงสร้างข้อมูลที่ซ่อนอยู่เบื้องหลังกริดกระเบื้องและที่ทำให้การค้นหาของอินเดียน่า โจนส์มีประสิทธิภาพมาก เราจะดูอีกวิธีหนึ่งในการแทนคำและพจนานุกรมที่ใช้ต้นไม้ในการจัดระเบียบปริภูมิการค้นหา
Counting with a Dictionary (การนับด้วย Dictionary)
บทที่ 4 อธิบายโครงสร้างข้อมูลแบบต้นไม้ (tree) ผมใช้แผนผังครอบครัวเพื่อสาธิตวิธีการคำนวณรายชื่อทายาทตามลำดับสิทธิ์ในการรับมรดก การคำนวณ traverse ต้นไม้ทั้งหมดและต้องเยี่ยมทุก node ในต้นไม้ ต้นไม้ยังเป็นโครงสร้างข้อมูลที่ยอดเยี่ยมสำหรับสนับสนุนการค้นหาภายในชุดข้อมูลอีกด้วย ในกรณีนี้ การค้นหาใช้ node ในต้นไม้เพื่อนำทางการค้นหาลงไปตามเส้นทางเดียวเพื่อหา element ที่ต้องการ
ลองกลับมาพิจารณาความท้าทายบนพื้นกระเบื้องของอินเดียน่า โจนส์อีกครั้ง ในภาพยนตร์ ก้าวแรกของเขากลายเป็นฉากที่ดราม่าเมื่อเขาเกือบตายเพราะเหยียบกระเบื้องที่ไม่ปลอดภัย เขาใช้การสะกด Jehova และเหยียบกระเบื้อง J ซึ่งพังทลายลงใต้เท้าของเขา นี่แสดงให้เห็นว่าความท้าทายนั้นซับซ้อนกว่าที่คิดไว้ในตอนแรก เพราะอินเดียน่า โจนส์ไม่สามารถแน่ใจเกี่ยวกับคำใบ้ที่ถูกต้อง (การสะกด) ได้มากขนาดนั้น นอกจาการสะกดด้วย I และ J แล้ว ยังมีการสะกดอีกแบบที่ขึ้นต้นด้วย Y ยิ่งไปกว่านั้น ชื่ออื่น ๆ ที่อาจใช้ได้ในหลักการก็เช่น Yahweh และ God สมมติว่าทั้งหมดนี้คือความเป็นไปได้ และอินเดียน่า โจนส์กับพ่อของเขาแน่ใจว่าหนึ่งในคำเหล่านี้บ่งบอกถึงเส้นทางที่ปลอดภัยข้ามพื้นกระเบื้อง
แล้วกลยุทธ์ที่ดีในการตัดสินใจว่าจะเหยียบกระเบื้องไหนคืออะไร? ถ้าทุกคำมีโอกาสเท่ากัน เขาสามารถเพิ่มโอกาสได้โดยเลือกตัวอักษรที่ปรากฏในหลายชื่อมากกว่าหนึ่งชื่อ เพื่ออธิบาย สมมติว่าเขาเลือก J (ตามที่เขาทำจริง) เนื่องจาก J ปรากฏในชื่อเดียวจากห้าชื่อ จึงมีโอกาสเพียงหนึ่งในห้า (นั่นคือ 20%) ที่กระเบื้องจะปลอดภัย ในทางกลับกัน การเหยียบกระเบื้อง v ปลอดภัยถึง 60% เนื่องจาก v ปรากฏในสามชื่อ ถ้าคำใดคำหนึ่งในสามคำนี้ถูกต้อง กระเบื้อง v จะปลอดภัย และเนื่องจากทุกคำถือว่ามีโอกาสถูกต้องเท่ากัน โอกาสรอดชีวิตจึงเพิ่มเป็นสามในห้าสำหรับกระเบื้อง v 4

ดังนั้น กลยุทธ์ที่ดีคือการคำนวณความถี่ของตัวอักษรในห้าคำก่อน แล้วจึงพยายามเหยียบกระเบื้องที่มีอัตราการปรากฏสูงสุด การจับคู่ตัวอักษรกับความถี่เช่นนี้เรียกว่า histogram ในการคำนวณ letter histogram อินเดียน่า โจนส์ต้องรักษา counter ความถี่สำหรับแต่ละตัวอักษร โดยการสแกนผ่านทุกคำ เขาสามารถเพิ่ม counter สำหรับแต่ละตัวอักษรที่พบ การรักษา counter สำหรับตัวอักษรต่าง ๆ เป็นงานที่แก้ไขได้ด้วยชนิดข้อมูล dictionary (ดู บทที่ 4 ) สำหรับการใช้งานนี้ key คือตัวอักษรแต่ละตัว และข้อมูลที่เก็บกับแต่ละ key คือความถี่ของตัวอักษร
เราสามารถใช้ array ที่มีตัวอักษรเป็น index เป็นโครงสร้างข้อมูลเพื่อ implement dictionary นี้ แต่นั่นจะเปลืองพื้นที่ของ array มากกว่า 50% เนื่องจากเรามีตัวอักษรที่แตกต่างกันเพียงสิบเอ็ดตัวให้ นับ อีกทางเลือกหนึ่ง เราสามารถใช้ลิสต์ได้ แต่นั่นก็จะไม่มีประสิทธิภาพมากนัก เพื่อให้เห็นสิ่งนี้ สมมติว่าเราสแกนคำตามลำดับตัวอักษร ดังนั้นเราจึงเริ่มต้นด้วยคำว่า God และเพิ่มแต่ละตัวอักษรลงในลิสต์ พร้อมกับค่าเริ่มต้นที่ 1 เราจะได้ลิสต์ดังนี้:
G:1 → o:1 → d:1
สังเกตว่าการแทรก G ใช้หนึ่งขั้นตอน การแทรก o ใช้สองขั้นตอนเพราะเราต้องเพิ่มมันต่อจาก G และการแทรก d ใช้สามขั้นตอนเพราะเราต้องเพิ่มมันต่อจากทั้ง G และ o แต่เราไม่สามารถแทรกตัวอักษรใหม่ที่ด้านหน้าของลิสต์แทนได้หรือ? น่าเสียดายที่มันใช้ไม่ได้เพราะเราต้องแน่ใจว่าตัวอักษรนั้นไม่ได้อยู่ในลิสต์ก่อนที่จะเพิ่มมัน ดังนั้นเราจึงต้องดูตัวอักษรที่มีอยู่ทั้งหมดในลิสต์ก่อนที่จะเพิ่มตัวอักษรใหม่ได้ ถ้าตัวอักษรอยู่ในลิสต์อยู่แล้ว เราจะเพิ่ม counter ของมันแทน ดังนั้นเราจึงใช้ไปแล้ว 1 + 2 + 3 = 6 ขั้นตอนสำหรับคำแรก
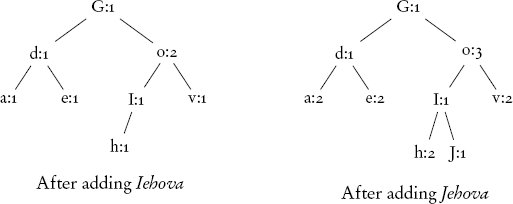
สำหรับคำถัดไป Iehova เราต้องใช้ 4, 5 และ 6 ขั้นตอนในการแทรก I , e และ h ตามลำดับ ซึ่งทำให้เรามีทั้งหมด 21 ขั้นตอน ตัวอักษรถัดไปคือ o ซึ่งมีอยู่แล้ว เราต้องใช้เพียง 2 ขั้นตอนในการหาและอัปเดตค่านับเป็น 2 ตัวอักษร v และ a เป็นตัวอักษรใหม่และต้องใช้อีก 7 + 8 = 15 ขั้นตอนในการแทรกที่ท้ายลิสต์ ณ จุดนี้ลิสต์ของเราใช้ 38 ขั้นตอนในการสร้างและมีลักษณะดังนี้:
G:1 → o:2 → d:1 → I:1 → e:1 → h:1 → v:1 → a:1
การอัปเดต dictionary ด้วยค่าจากคำว่า Jehova จากนั้นใช้ 9 ขั้นตอนสำหรับการเพิ่ม J และ 5, 6, 2, 7 และ 8 ขั้นตอนสำหรับการเพิ่มค่าของตัวอักษรที่เหลือที่มีอยู่แล้วในลิสต์ ซึ่งทำให้จำนวนขั้นตอนทั้งหมดเป็น 75 หลังจากประมวลผลสองคำสุดท้าย Yahweh และ Yehova โดยใช้ 40 และ 38 ขั้นตอนตามลำดับ ในที่สุดเราก็ได้ลิสต์ดังต่อไปนี้ ซึ่งใช้ทั้งหมด 153 ขั้นตอนในการสร้าง:
G:1 → o:4 → d:1 → I:1 → e:4 → h:4 → v:3 → a:4 → J:1 → Y:2 → w:1
สังเกตว่าเราต้องไม่เพิ่ม h ตัวที่สองใน Yahweh เพราะการนับมันสองครั้งสำหรับคำเดียวจะเพิ่มโอกาสของตัวอักษรนั้นอย่างไม่ถูกต้อง (ในกรณีนี้จาก 80% เป็น 100%) 5 การสแกนลิสต์ครั้งสุดท้ายแสดงให้เห็นว่าตัวอักษร o , e , h และ a ปลอดภัยที่สุดที่จะเริ่มต้น โดยทั้งหมดมีความน่าจะเป็น 80% ที่จะอยู่ในคำที่ถูกต้อง
Lean Is Not Always Better (ความเรียบง่ายไม่ได้ดีกว่าเสมอไป)
ข้อเสียหลักของโครงสร้างข้อมูลแบบลิสต์เมื่อใช้เป็น dictionary คือต้นทุนสูงในการเข้าถึงข้อมูลที่อยู่ท้ายลิสต์ซ้ำ ๆ
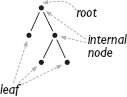
โครงสร้างข้อมูล binary search tree พยายามหลีกเลี่ยงปัญหานี้โดยแบ่งปริภูมิการค้นหาให้เท่าเทียมกันมากขึ้นเพื่อสนับสนุนการค้นหาที่เร็วกว่า Binary tree คือต้นไม้ที่แต่ละ node มีลูกได้มากที่สุดสองตัว ดังที่ได้กล่าวไป node ที่ไม่มีลูกเรียกว่า ใบ (leaves) node ที่มีลูกเรียกว่า node ภายใน (internal nodes) และ node ที่ไม่มีพ่อแม่เรียกว่า ราก (root) ของต้นไม้
มาดูตัวอย่าง binary tree บางส่วนที่แสดงใน รูปที่ 5.1 กัน ต้นไม้ทางซ้ายคือต้นไม้ที่มี node เดียว—ต้นไม้ที่ง่ายที่สุดเท่าที่จะจินตนาการได้ รากซึ่งก็เป็นใบเช่นกัน ประกอบด้วยตัวอักษร G ต้นไม้นี้ดูไม่ค่อยเหมือนต้นไม้เลย คล้ายกับลิสต์ที่มี element เดียวที่ไม่เหมือนลิสต์ ต้นไม้ตรงกลางมีอีกหนึ่ง node ซึ่งเป็นลูก o เพิ่มเข้าไปที่ราก ในต้นไม้ทางขวา ลูก d ตัวมันเองมีลูก a และ e ตัวอย่างนี้แสดงให้เห็นว่าถ้าเราตัดลิงก์ไปยังพ่อแม่ของมัน node จะกลายเป็นรากของต้นไม้ที่แยกต่างหาก ซึ่งเรียกว่า ซับทรี (subtree) ของพ่อแม่ ในกรณีนี้ ต้นไม้ที่มีราก d และลูกสองตัว a และ e เป็น subtree ของ node G เช่นเดียวกับต้นไม้ node เดียวที่มีราก o สิ่งนี้บ่งชี้ว่าต้นไม้เป็นโครงสร้างข้อมูลที่ recursive โดยธรรมชาติและสามารถนิยามได้ดังนี้ ต้นไม้คือ node เดียว หรือเป็น node ที่มี subtree หนึ่งหรือสองอัน (ซึ่งรากของมันคือลูกของ node นั้น) โครงสร้างแบบ recursive ของต้นไม้นี้ถูกระบุไว้ใน บทที่ 4 ซึ่งนำเสนออัลกอริทึมแบบ recursive ในการ traverse แผนผังครอบครัว
แนวคิดของ binary search tree คือการใช้ internal node เป็นขอบเขตที่แยก node สืบเชื้อสายทั้งหมดออกเป็นสองกลุ่ม: node ที่มีค่าน้อยกว่า node ขอบเขตจะอยู่ในซับทรีด้านซ้าย และ node ที่มีค่ามากกว่าจะอยู่ในซับทรีด้านขวา
การจัดเรียงนี้สามารถใช้ประโยชน์ในการค้นหาได้ดังนี้ ถ้าเรากำลังหาค่าเฉพาะในต้นไม้ เราจะเปรียบเทียบมันกับรากของต้นไม้ ถ้าตรงกัน เราก็พบค่าและการค้นหาก็จบลง มิฉะนั้น ถ้าค่าน้อยกว่าราก เราสามารถจำกัดการค้นหาต่อไปเฉพาะซับทรีด้านซ้ายเท่านั้น เราไม่ต้องดู node ใด ๆ ในซับทรีด้านขวาเลย เพราะ node ทั้งหมดมีค่ามากกว่ารากและมากกว่าค่าที่กำลังค้นหา ในแต่ละกรณี internal node จะกำหนดขอบเขตที่แยก "ภายใน" (ซึ่งคือซับทรีด้านซ้าย) ออกจาก "ภายนอก" ซึ่งคือซับทรีด้านขวา เช่นเดียวกับที่อยู่ผู้ส่งของสมุดบันทึกจอกศักดิ์สิทธิ์กำหนด "ภายใน" ของขั้นตอนถัดไปในการค้นหาพ่อของอินเดียน่า โจนส์
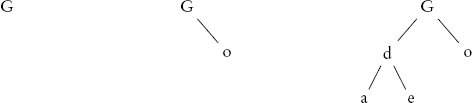
รูปที่ 5.1 ตัวอย่าง binary tree สามแบบ ซ้าย: ต้นไม้ที่มีเพียง node เดียว กลาง: ต้นไม้ที่รากมีซับทรีด้านขวาที่เป็น node เดียว ขวา: ต้นไม้ที่รากมีสองซับทรี ต้นไม้ทั้งสามมีคุณสมบัติของ binary search tree ซึ่งกล่าวว่า node ในซับทรีด้านซ้ายมีค่าน้อยกว่าราก และ node ในซับทรีด้านขวามีค่ามากกว่าราก
ต้นไม้ทั้งสามที่แสดงใน รูปที่ 5.1 ล้วนเป็น binary search tree พวกมันเก็บตัวอักษรเป็นค่าที่สามารถเปรียบเทียบตามตำแหน่งในตัวอักษรได้ การหาค่าในต้นไม้ดังกล่าวทำงานโดยการเปรียบเทียบค่าที่ต้องการกับค่าใน node ของต้นไม้ซ้ำ ๆ และลงไปในซับทรีด้านขวาหรือซ้ายตามลำดับ
สมมติว่าเราต้องการตรวจสอบว่า e อยู่ในต้นไม้ทางขวาหรือไม่ เราเริ่มที่รากของต้นไม้และเปรียบเทียบ e กับ G เนื่องจาก e มาก่อน G ในตัวอักษรและดังนั้นจึง "น้อยกว่า" G เราจึงค้นหาต่อในซับทรีด้านซ้าย ซึ่งมีค่าทั้งหมดที่น้อยกว่า G ที่เก็บอยู่ในต้นไม้นี้ เปรียบเทียบ e กับรากของซับทรีด้านซ้าย d เราพบว่า e มีค่ามากกว่าและจึงค้นหาต่อในซับทรีด้านขวา ซึ่งเป็นต้นไม้ที่มีเพียง node เดียว เปรียบเทียบ e กับ node นั้นก็สิ้นสุดการค้นหาด้วยผลสำเร็จ ถ้าเราค้นหา f แทน การค้นหาจะนำไปยัง node เดียวกันคือ e แต่เนื่องจาก e ไม่มีซับทรีด้านขวา การค้นหาจะจบลงที่นั่นด้วยข้อสรุปว่า f ไม่ได้อยู่ในต้นไม้
การค้นหาใด ๆ จะดำเนินไปตามเส้นทางในต้นไม้ ดังนั้นเวลาในการหา element หรือสรุปว่ามันไม่มีอยู่ในต้นไม้จะไม่นานกว่าเส้นทางที่ยาวที่สุดจากรากถึงใบในต้นไม้ เราสามารถเห็นได้ว่าต้นไม้ทางขวาใน รูปที่ 5.1 ซึ่งเก็บห้า element มีเส้นทางไปยังใบที่มีความยาวเพียง 2 หรือ 3 เท่านั้น ซึ่งหมายความว่าเราสามารถหา element ใด ๆ ได้ในอย่างมากสามขั้นตอน เปรียบเทียบกับลิสต์ที่มีห้า element ซึ่งการค้นหา element สุดท้ายของลิสต์จะใช้เวลาห้าขั้นตอนเสมอ
ตอนนี้เราพร้อมที่จะติดตามการคำนวณ letter histogram โดยใช้ binary search tree เพื่อแทน dictionary อีกครั้ง เราเริ่มต้นด้วยคำ God และเพิ่มแต่ละตัวอักษรลงในต้นไม้ พร้อมกับค่าเริ่มต้นที่ 1 เราได้ต้นไม้ต่อไปนี้ ซึ่งสะท้อนลำดับของตัวอักษรตามที่ปรากฏในต้นไม้:
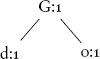
ในกรณีนี้ การแทรก G ใช้หนึ่งขั้นตอน เช่นเดียวกับในลิสต์ แต่การแทรก o และ d ทั้งคู่ใช้เพียงสองขั้นตอน เนื่องจากทั้งคู่เป็นลูกของ G ดังนั้นเราจึงประหยัดไปหนึ่งขั้นตอนสำหรับคำแรก (1 + 2 + 2 = 5 ขั้นตอนสำหรับต้นไม้ เทียบกับ 1 + 2 + 3 = 6 สำหรับลิสต์)
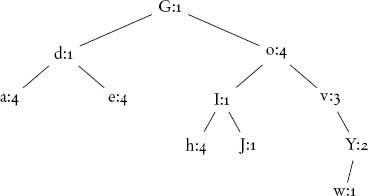
การแทรกคำถัดไป Iehova ต้องใช้สามขั้นตอนสำหรับแต่ละตัวอักษร ยกเว้น o และ h ซึ่งต้องใช้สองและสี่ขั้นตอนตามลำดับ เช่นเดียวกับลิสต์ การประมวลผล o ไม่ได้สร้าง element ใหม่ แต่เพิ่มค่าของ element ที่มีอยู่ขึ้น 1 การประมวลผลคำนี้จึงใช้ 18 ขั้นตอน ทำให้รวมเป็น 24 ขั้นตอน เทียบกับ 38 ขั้นตอนที่จำเป็นสำหรับโครงสร้างข้อมูลแบบลิสต์ คำว่า Jehova เปลี่ยนแปลงโครงสร้างต้นไม้เพียงเล็กน้อยโดยเพิ่ม node สำหรับ J ซึ่งใช้สี่ขั้นตอน ด้วยอีก 3 + 4 + 2 + 3 + 3 = 15 ขั้นตอน ค่าของตัวอักษรที่มีอยู่จึงถูกอัปเดต ทำให้รวมเป็น 39 ขั้นตอน เทียบกับ 75 สำหรับลิสต์:
สุดท้าย การเพิ่ม Yahwe(h) และ Yehova แต่ละคำใช้ 19 ขั้นตอน เราได้ต้นไม้ต่อไปนี้ ซึ่งใช้ทั้งหมด 76 ขั้นตอนในการสร้าง นี่คือครึ่งหนึ่งของ 153 ขั้นตอนที่จำเป็นสำหรับโครงสร้างข้อมูลแบบลิสต์
binary search tree นี้แทน dictionary เดียวกับลิสต์ แต่อยู่ในรูปแบบที่สนับสนุนการค้นหาและการอัปเดตที่เร็วกว่า—โดยทั่วไปแล้วอย่างน้อย รูปร่างเชิงพื้นที่ของลิสต์และต้นไม้ช่วยอธิบายความแตกต่างในประสิทธิภาพได้บางส่วน โครงสร้างที่ยาวและแคบของลิสต์มักบังคับให้การค้นหาต้องเดินทางไกลและดู element ที่ไม่เกี่ยวข้อง ในทางตรงกันข้าม รูปร่างที่กว้างและตื้นของต้นไม้จะนำทางการค้นหาอย่างมีประสิทธิภาพและจำกัด element ที่ต้องพิจารณาและระยะทางที่ต้องเดินทาง อย่างไรก็ตาม การเปรียบเทียบที่เป็นธรรมระหว่างลิสต์และ binary search tree จำเป็นต้องพิจารณาแง่มุมเพิ่มเติมอีกสองสามประการ
Efficiency Hangs in the Balance (ประสิทธิภาพขึ้นอยู่กับความสมดุล)
ในวิทยาการคอมพิวเตอร์ เรามักจะไม่เปรียบเทียบโครงสร้างข้อมูลที่แตกต่างกันโดยการนับจำนวนขั้นตอนที่แน่นอนสำหรับลิสต์หรือต้นไม้เฉพาะ เนื่องจากอาจให้ภาพที่ทำให้เข้าใจผิด โดยเฉพาะกับโครงสร้างข้อมูลขนาดเล็ก ยิ่งไปกว่านั้น แม้แต่ในการวิเคราะห์ง่าย ๆ นี้ เราก็เปรียบเทียบการดำเนินการที่มีความซับซ้อนไม่เท่ากันและใช้เวลาในการดำเนินการต่างกัน ตัวอย่างเช่น ในการเปรียบเทียบในลิสต์ เราแค่ต้องทดสอบว่า element สองตัวเท่ากันหรือไม่ ในขณะที่ใน binary search tree เรายังต้องพิจารณาว่า element ใดใหญ่กว่าเพื่อนำทางการค้นหาไปยังซับทรีที่สอดคล้องกัน ซึ่งหมายความว่าหลายการดำเนินการจาก 153 รายการของลิสต์นั้นเรียบง่ายกว่าและเร็วกว่าในการดำเนินการมากกว่าบางส่วนจาก 76 การดำเนินการของต้นไม้ และเราไม่ควรตีความการเปรียบเทียบโดยตรงของตัวเลขทั้งสองมากเกินไป
แทนที่จะทำเช่นนั้น เราจะพิจารณาการเพิ่มขึ้นของ runtime ของการดำเนินการเมื่อโครงสร้างข้อมูลมีขนาดใหญ่ขึ้นและซับซ้อนขึ้น บทที่ 2 แสดงตัวอย่างไว้ สำหรับลิสต์เรารู้ว่า runtime สำหรับการแทรก element ใหม่และการค้นหา element ที่มีอยู่เป็นแบบ linear นั่นคือ เวลาสำหรับการแทรกหรือหานั้นเป็นสัดส่วนกับความยาวของลิสต์ในกรณีที่แย่ที่สุด ซึ่งไม่เลวนัก แต่ถ้าการดำเนินการดังกล่าวถูกดำเนินการซ้ำ ๆ runtime ที่สะสมจะกลายเป็น quadratic ซึ่งอาจเป็นอุปสรรค จำกลยุทธ์ที่ให้ฮันเซลเดินทางกลับบ้านทุกครั้งเพื่อหาก้อนกรวดใหม่
ในทางเปรียบเทียบ runtime สำหรับการแทรก element ลงในต้นไม้และการค้นหา element ในต้นไม้คือเท่าใด? ต้นไม้ค้นหาสุดท้ายมี 11 element และการค้นหาและแทรกใช้เวลาระหว่างสามถึงห้าขั้นตอน ในความเป็นจริง เวลาที่ใช้ในการหาหรือแทรก element ถูกจำกัดด้วยความสูงของต้นไม้ ซึ่งมักจะน้อยกว่าจำนวน element ของมันมาก ในต้นไม้ที่ สมดุล (balanced) นั่นคือ ต้นไม้ที่เส้นทางทั้งหมดจากรากถึงใบมีความยาวเท่ากัน (±1) ความสูงของต้นไม้เป็น logarithmic ตามขนาด ซึ่งหมายความว่าความสูงเพิ่มขึ้นเพียง 1 เมื่อใดก็ตามที่จำนวน node ในต้นไม้เพิ่มขึ้นเป็นสองเท่า ตัวอย่างเช่น ต้นไม้ที่สมดุลที่มี 15 node มีความสูง 4 ต้นไม้ที่สมดุลที่มี 1,000 node มีความสูง 10 และ 1,000,000 node สามารถอยู่ในต้นไม้ที่สมดุลที่มีความสูง 20 ได้อย่างสบาย ๆ runtime แบบ logarithmic ดีกว่า runtime แบบ linear มาก และเมื่อขนาดของ dictionary ใหญ่ขึ้นเรื่อย ๆ โครงสร้างข้อมูลแบบต้นไม้ก็จะดีขึ้นเรื่อย ๆ เมื่อเทียบกับโครงสร้างข้อมูลแบบลิสต์
การวิเคราะห์นี้ขึ้นอยู่กับ binary search tree ที่ สมดุล เราสามารถรับประกันได้หรือไม่ว่าต้นไม้ที่สร้างขึ้นจะสมดุล และถ้าไม่ runtime ในกรณีของต้นไม้ค้นหาที่ไม่สมดุลจะเป็นเท่าใด? ต้นไม้สุดท้ายในตัวอย่างนี้ ไม่ได้ สมดุล เนื่องจากเส้นทางไปยังใบ e มีความยาว 3 ในขณะที่เส้นทางไปยังใบ w มีความยาว 5 ลำดับที่ตัวอักษรถูกแทรกลงในต้นไม้มีความสำคัญและสามารถนำไปสู่ต้นไม้ที่แตกต่างกัน ตัวอย่างเช่น ถ้าเราแทรกตัวอักษรตามลำดับของคำว่า doG เราจะได้ binary search tree ดังต่อไปนี้ ซึ่งไม่สมดุลเลย:
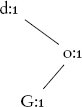
ต้นไม้นี้ไม่สมดุลอย่างมาก—มันไม่ได้แตกต่างจากลิสต์จริง ๆ และนี่ไม่ใช่ข้อยกเว้นที่แปลกประหลาด จากลำดับที่เป็นไปได้หกลำดับของตัวอักษรสามตัว มีสองลำดับที่นำไปสู่ต้นไม้ที่สมดุล ( God และ Gdo ) และอีกสี่ลำดับนำไปสู่ลิสต์ โชคดีที่มีเทคนิคในการปรับสมดุลต้นไม้ค้นหาที่เสียรูปทรงหลังการแทรก แต่เทคนิคเหล่านี้เพิ่มต้นทุนให้กับการดำเนินการแทรก แม้ว่าต้นทุนยังคงสามารถรักษาให้เป็น logarithmic ได้
สุดท้าย binary search tree ใช้ได้กับ element ที่สามารถเรียงลำดับได้เท่านั้น นั่นคือ element สองตัวใด ๆ ที่เราสามารถบอกได้ว่าอันไหนใหญ่กว่าและอันไหนเล็กกว่า การเปรียบเทียบเช่นนี้จำเป็นในการตัดสินใจว่าจะเคลื่อนไปในทิศทางใดในต้นไม้เพื่อหา หรือจัดเก็บ element อย่างไรก็ตาม สำหรับข้อมูลบางประเภท การเปรียบเทียบเช่นนี้ไม่สามารถทำได้ สมมติว่าคุณกำลังจดบันทึกเกี่ยวกับรูปแบบการเย็บปะติดปะต่อกัน สำหรับแต่ละรูปแบบคุณต้องการบันทึกว่าต้องใช้ผ้าและเครื่องมืออะไร ยากแค่ไหนในการทำ และใช้เวลาเท่าไหร่ ในการจัดเก็บข้อมูลเกี่ยวกับรูปแบบเหล่านั้นใน binary search tree คุณจะตัดสินใจได้อย่างไรว่ารูปแบบหนึ่งเล็กกว่าหรือใหญ่กว่าอีกรูปแบบหนึ่ง? เนื่องจากรูปแบบแตกต่างกันในจำนวนชิ้นส่วน รวมถึงรูปร่างและสีของชิ้นส่วน จึงไม่ชัดเจนว่าจะนิยามลำดับระหว่างรูปแบบเหล่านั้นอย่างไร นี่ไม่ใช่งานที่เป็นไปไม่ได้—เราสามารถแยกรูปแบบออกเป็นส่วนประกอบและอธิบายด้วยรายการคุณลักษณะของมัน (เช่น จำนวนชิ้นส่วน หรือสีและรูปร่างของมัน) แล้วเปรียบเทียบรูปแบบโดยการเปรียบเทียบรายการคุณลักษณะของมัน แต่นี่ต้องใช้ความพยายาม และอาจไม่ practical เท่าไหร่ ดังนั้น binary search tree อาจไม่เหมาะสมสำหรับการจัดเก็บ dictionary ของรูปแบบการเย็บปะติดปะต่อกัน อย่างไรก็ตาม คุณยังสามารถใช้ลิสต์ได้ เพราะสิ่งที่ต้องทำสำหรับลิสต์คือการตัดสินใจว่ารูปแบบสองแบบเหมือนกันหรือไม่ ซึ่งง่ายกว่าการเรียงลำดับพวกมัน
โดยสรุป: Binary search tree ใช้กลยุทธ์ที่ผู้คนใช้โดยธรรมชาติและไม่ต้องใช้ความพยายามในการแยกปัญหาการค้นหาออกเป็นปัญหาย่อย ๆ ที่เล็กกว่า ในความเป็นจริง binary search tree ได้ทำให้แนวคิดนี้เป็นระบบและสมบูรณ์แบบ ผลที่ตามมาคือ binary search tree สามารถมีประสิทธิภาพมากกว่าลิสต์มากในการแทน dictionary อย่างไรก็ตาม พวกมันต้องการความพยายามมากขึ้นในการรับประกันความสมดุล และมันใช้ไม่ได้กับข้อมูลทุกประเภท และสิ่งนี้ควรตรงกับประสบการณ์ของคุณในการค้นหาโต๊ะทำงาน สำนักงาน ห้องครัว หรือโรงรถของคุณ ถ้าคุณทุ่มเทความพยายามอย่างสม่ำเสมอในการรักษาความเป็นระเบียบ เช่น การวางเอกสารหรือเครื่องมือกลับเข้าที่หลังการใช้งาน คุณจะหาสิ่งของได้ง่ายกว่าการต้องค้นหากองของที่ไม่เป็นระเบียบ
Try a Trie (ลองใช้ Trie)
Binary search tree เป็นทางเลือกที่มีประสิทธิภาพแทนลิสต์ในการคำนวณ histogram ของความถี่ตัวอักษรในคำ แต่นี่เป็นเพียงหนึ่งในการคำนวณที่ช่วยให้อินเดียน่า โจนส์แก้ความท้าทายบนพื้นกระเบื้องได้ การคำนวณอีกอย่างคือการระบุลำดับของกระเบื้องที่สะกดคำเฉพาะและนำทางข้ามพื้นกระเบื้องอย่างปลอดภัย
เราทราบแล้วว่ากริดที่มีหกแถว แต่ละแถวมีแปดตัวอักษร มีเส้นทางกระเบื้องหกแผ่นที่แตกต่างกัน 262,144 เส้นทาง เนื่องจากแต่ละเส้นทางสอดคล้องกับหนึ่งคำ เราสามารถแทนความสัมพันธ์ของคำต่อเส้นทางด้วย dictionary ลิสต์จะเป็นการแทนที่ไม่มีประสิทธิภาพ เนื่องจากคำใบ้ Iehova อาจอยู่ใกล้ท้ายลิสต์และอาจใช้เวลาค่อนข้างนานในการค้นหา Balanced binary search tree จะดีกว่ามากเพราะความสูงของมันจะเท่ากับ 18 ซึ่งรับประกันว่าคำใบ้จะถูกพบได้ค่อนข้างเร็ว แต่เราไม่มีต้นไม้ค้นหาที่สมดุลเช่นนั้น และการสร้างมันเป็นงานที่ใช้เวลามาก เช่นเดียวกับต้นไม้ค้นหาที่มีตัวอักษร เราต้องแทรกแต่ละ element แยกกัน และในการทำเช่นนั้นเราต้อง traverse เส้นทางในต้นไม้จากรากไปยังใบซ้ำ ๆ โดยไม่ต้องวิเคราะห์กระบวนการนี้โดยละเอียด มันควรจะชัดเจนว่าการสร้างต้นไม้ใช้เวลามากกว่า linear time 6
อย่างไรก็ตาม เราสามารถระบุลำดับของกระเบื้องได้อย่างมีประสิทธิภาพ (ด้วยไม่เกิน 42 ขั้นตอน) โดยไม่ต้องมีโครงสร้างข้อมูลเพิ่มเติมใด ๆ เป็นไปได้อย่างไร? คำตอบคือพื้นกระเบื้องที่มีตัวอักษรบนกระเบื้องนั้นเป็นโครงสร้างข้อมูลในตัวที่รองรับการค้นหาแบบที่อินเดียน่า โจนส์ต้องทำเป็นพิเศษ มันถูกเรียกว่า trie, 7 ซึ่งเป็นโครงสร้างข้อมูลที่ค่อนข้างคล้ายกับ binary search tree แต่ก็แตกต่างในแง่มุมที่สำคัญ
จำได้ว่าอินเดียน่า โจนส์ในแต่ละก้าวบนกระเบื้องลดปริภูมิการค้นหาลงแปดเท่า ซึ่งคล้ายกับสิ่งที่เกิดขึ้นเมื่อลงไปใน balanced binary search tree ที่ปริภูมิการค้นหาถูกตัดครึ่ง: โดยการเลือกหนึ่งในสองกิ่งของต้นไม้ ครึ่งหนึ่งของ node ในต้นไม้ถูกแยกออกจากการค้นหา ในทำนองเดียวกัน โดยการไม่เลือกกระเบื้อง ปริภูมิการค้นหาจะลดลงหนึ่งในแปด และโดยการเลือกกระเบื้อง ปริภูมิการค้นหาจะลดลงเหลือหนึ่งในแปดของขนาดก่อนหน้า เพราะการเลือกกระเบื้องหนึ่งแผ่นหมายถึงการไม่เลือกอีกเจ็ดแผ่น และลดปริภูมิการค้นหาลงเจ็ดในแปด
แต่ยังมีอย่างอื่นเกิดขึ้นที่นั่นซึ่งแตกต่างจากวิธีการทำงานของ binary search tree ใน binary search tree แต่ละ element จะถูกเก็บใน node ที่แยกจากกัน ในทางตรงกันข้าม trie จะเก็บตัวอักษรเดี่ยวในแต่ละ node และแทนคำเป็นเส้นทางที่เชื่อมต่อตัวอักษรต่าง ๆ เพื่อทำความเข้าใจความแตกต่างระหว่าง binary search tree และ trie ให้พิจารณาตัวอย่างต่อไปนี้ สมมติว่าเราต้องการแทนชุดคำ bat , bag , beg , bet , mag , mat , meg และ met balanced binary search tree ที่มีคำเหล่านี้มีลักษณะดังนี้:
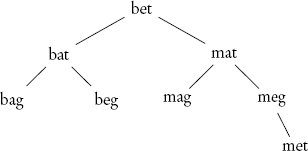
ในการหาคำ bag ในต้นไม้นี้ เราจะเปรียบเทียบมันกับราก bet ซึ่งบอกให้เราค้นหาต่อในซับทรีด้านซ้าย การเปรียบเทียบนี้ใช้สองขั้นตอนในการเปรียบเทียบอักขระสองตัวแรกของทั้งสองคำ ต่อไปเราจะเปรียบเทียบ bag กับรากของซับทรีด้านซ้าย bat ซึ่งบอกให้เราค้นหาต่อในซับทรีด้านซ้ายอีกครั้ง การเปรียบเทียบนี้ใช้สามขั้นตอน เนื่องจากเราต้องเปรียบเทียบอักขระทั้งสามตัวของทั้งสองคำ สุดท้ายเราเปรียบเทียบ bat กับ node ซ้ายสุดในต้นไม้ ซึ่งส่งผลให้การค้นหาสำเร็จ การเปรียบเทียบครั้งสุดท้ายนี้ก็ใช้สามขั้นตอนเช่นกัน และการค้นหาทั้งหมดต้องใช้การเปรียบเทียบ 8 ครั้ง
เราสามารถแทนชุดคำเดียวกันนี้ด้วยพื้นกระเบื้องขนาด 2 คูณ 3 โดยแต่ละแถวมีกระเบื้องสำหรับตัวอักษรที่สามารถเกิดขึ้นที่ตำแหน่งที่สอดคล้องกันในคำใด ๆ ตัวอย่างเช่น เนื่องจากแต่ละคำขึ้นต้นด้วย b หรือ m แถวแรกจึงต้องมีกระเบื้องสองแผ่นสำหรับตัวอักษรสองตัวนี้ ในทำนองเดียวกัน แถวที่สองต้องมีกระเบื้องสองแผ่นสำหรับ a และ e และแถวที่สามต้องมีกระเบื้องสำหรับ g และ t
b | m |
a | e |
g | t |
การค้นหาคำบนพื้นกระเบื้องทำงานโดยการ traverse พื้นกระเบื้องทีละแถวอย่างเป็นระบบ สำหรับแต่ละตัวอักษรของคำ แถวกระเบื้องที่สอดคล้องกันจะถูก traverse จากซ้ายไปขวาจนกว่าจะพบตัวอักษรนั้น ตัวอย่างเช่น ในการหาคำ bag บนพื้นกระเบื้องนี้ เราเริ่มค้นหาตัวอักษรแรก b ในแถวแรก เราพบกระเบื้องในหนึ่งขั้นตอน ต่อไปเราค้นหาตัวอักษรที่สอง a ในแถวที่สอง ซึ่งก็ใช้หนึ่งขั้นตอนเช่นกัน สุดท้ายเราสามารถค้นหาสำเร็จโดยการหา g ในแถวที่สาม ซึ่งก็ใช้เพียงหนึ่งขั้นตอนเช่นกัน โดยรวมแล้วการค้นหานี้ใช้การเปรียบเทียบ 3 ครั้ง
การค้นหาบนพื้นกระเบื้องต้องการขั้นตอนน้อยกว่า binary search tree เพราะเราต้องเปรียบเทียบแต่ละตัวอักษรเพียงครั้งเดียว ในขณะที่การค้นหาใน binary tree ทำให้เกิดการเปรียบเทียบส่วนต้นของคำซ้ำ ๆ คำว่า bag เป็นกรณีที่ดีที่สุดสำหรับพื้นกระเบื้อง เนื่องจากแต่ละตัวอักษรสามารถพบบนกระเบื้องแผ่นแรก ในทางตรงกันข้าม คำว่า met ต้องการหกขั้นตอน เนื่องจากตัวอักษรแต่ละตัวอยู่ในกระเบื้องแผ่นสุดท้ายในแถว แต่มันจะแย่ไปกว่านี้ไม่ได้แล้วเพราะเราต้องตรวจกระเบื้องแต่ละแผ่นอย่างมากที่สุดหนึ่งครั้ง (สำหรับการเปรียบเทียบ การหา met ใน binary search tree ต้องการ 2 + 3 + 3 + 3 = 11 ขั้นตอน) กรณีที่ดีที่สุดสำหรับ binary search tree คือการหาคำ bet ซึ่งต้องการเพียงสามขั้นตอน อย่างไรก็ตาม เมื่อระยะห่างจากรากเพิ่มขึ้น binary search จะนำไปสู่การเปรียบเทียบมากขึ้นเรื่อย ๆ เนื่องจากคำส่วนใหญ่อยู่ใกล้ใบของต้นไม้ ซึ่งอยู่ห่างจากรากมากกว่า 8 เราจึงต้องทำการเปรียบเทียบส่วนต้นของคำซ้ำ ๆ ซึ่งบ่งชี้ว่าในกรณีส่วนใหญ่ การค้นหาใน trie จะเร็วกว่าใน binary search tree
การเปรียบเทียบกับพื้นกระเบื้องชี้ให้เห็นว่า trie สามารถแทนเป็นตารางได้ แต่ก็ไม่เสมอไป ตัวอย่างใช้ได้ดีเพราะทุกคำมีความยาวเท่ากัน และแต่ละตำแหน่งในคำสามารถมีตัวอักษรเดียวกันได้ อย่างไรก็ตาม สมมติว่าเราต้องการแทนคำ bit และ big ด้วย ในกรณีนี้ แถวที่สองต้องการกระเบื้องเพิ่มเติมสำหรับตัวอักษร i ซึ่งทำให้รูปทรงสี่เหลี่ยมผืนผ้าหายไป การเพิ่มสองคำนี้เผยให้เห็นความสม่ำเสมออีกอย่างในตัวอย่างที่ไม่มีอยู่ทั่วไป ตัวอย่างคำถูกเลือกเพื่อให้ prefix ที่แตกต่างกันที่มีความยาวเท่ากันมี suffix ที่เป็นไปได้เหมือนกัน ซึ่งช่วยให้สามารถแบ่งปันข้อมูลได้ ตัวอย่างเช่น ba และ be สามารถทำให้สมบูรณ์ได้ทั้งคู่โดยการเพิ่ม g หรือ t ซึ่งหมายความว่าการต่อเนื่องที่เป็นไปได้ของ prefix ทั้งสองสามารถอธิบายได้ด้วยแถวกระเบื้องแถวเดียวที่มีตัวอักษร g และ t อย่างไรก็ตาม สิ่งนี้ไม่เป็นความจริงอีกต่อไปเมื่อเราเพิ่มคำ bit และ big ในขณะที่ b สามารถต่อด้วยตัวอักษรที่เป็นไปได้ 3 ตัว คือ a , e และ i แต่ m สามารถต่อด้วย a และ e เท่านั้น ซึ่งหมายความว่าเราต้องการการต่อเนื่องที่แตกต่างกันสองแบบ
ดังนั้น trie จึงมักถูกแทนเป็น binary tree แบบพิเศษที่ node มีตัวอักษรเดี่ยว ซับทรีด้านซ้ายแทนการต่อเนื่องของคำ และซับทรีด้านขวาแทนตัวเลือกตัวอักษรอื่น (พร้อมการต่อเนื่องของมัน) ตัวอย่างเช่น trie สำหรับคำ bat, bag, beg และ bet มีลักษณะดังนี้:
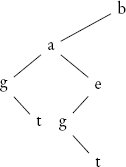
เนื่องจากรากไม่มีขอบด้านขวา คำทั้งหมดจึงเริ่มต้นด้วย b ขอบด้านซ้ายจาก b ไปยังซับทรีที่มีราก a นำไปสู่การต่อเนื่องที่เป็นไปได้ ซึ่งเริ่มต้นด้วย a หรือ e ซึ่งเป็นทางเลือกของ a ที่ชี้โดยขอบด้านขวาจาก a ข้อเท็จจริงที่ว่า ba และ be สามารถต่อด้วย g หรือ t แสดงโดยขอบด้านซ้ายจาก a ไปยังซับทรีที่มีราก g ซึ่งมีลูกด้านขวา t ข้อเท็จจริงที่ว่าซับทรีด้านซ้ายของ a และ e เหมือนกันหมายความว่าสามารถแชร์กันได้ ซึ่งถูกใช้ประโยชน์ในการแทนพื้นกระเบื้องโดยมีแถวกระเบื้องแถวเดียว เนื่องจากการแชร์นี้ trie โดยทั่วไปจึงต้องการพื้นที่จัดเก็บน้อยกว่า binary search tree
ในขณะที่ใน binary search tree แต่ละ key ถูกบรรจุอยู่ใน node ที่แยกจากกัน key ที่เก็บใน trie จะถูกกระจายไปทั่ว node ของ trie ลำดับของ node ใด ๆ จากรากของ trie คือ prefix ของ key บางตัวใน trie และในกรณีของพื้นกระเบื้อง กระเบื้องที่เลือกคือ prefix ของเส้นทางสุดท้าย นี่คือสาเหตุที่ trie ถูกเรียกว่า prefix tree ด้วย โครงสร้างข้อมูล trie ที่แทนพื้นกระเบื้องที่อินเดียน่า โจนส์เผชิญแสดงใน รูปที่ 5.2
เช่นเดียวกับ binary search tree และลิสต์ trie ก็มีข้อดีและปัญหาของมัน ตัวอย่างเช่น มันใช้ได้เฉพาะกับ key ที่สามารถแยกย่อยเป็นลำดับของรายการได้ เช่นเดียวกับอินเดียน่า โจนส์ที่ในที่สุดไม่สามารถครอบครองจอกศักดิ์สิทธิ์ได้ ไม่มีจอกศักดิ์สิทธิ์ของโครงสร้างข้อมูล การเลือกโครงสร้างข้อมูลที่ดีที่สุดขึ้นอยู่กับรายละเอียดของแอปพลิเคชันเสมอ
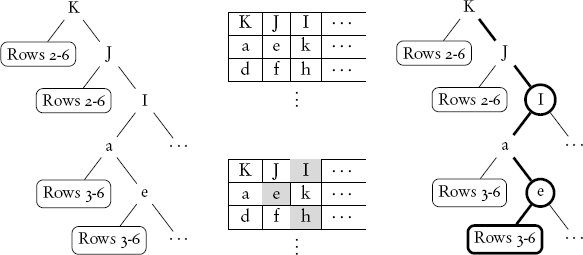
รูปที่ 5.2 โครงสร้างข้อมูล trie และวิธีการค้นหา ซ้าย: การแทน trie ที่ซับทรีด้านซ้ายแทนการต่อเนื่องของคำที่เป็นไปได้ของตัวอักษรใน node แม่ (แสดงโดยสี่เหลี่ยมมุมมน) และซับทรีด้านขวาแทนทางเลือกของ node แม่ กลางบน: การแทนพื้นกระเบื้องของ trie ทางซ้ายซึ่งซับทรีที่เหมือนกันถูกแชร์ผ่านแถวกระเบื้องแถวเดียว กลางล่าง: กระเบื้องสามแผ่นที่ถูกเลือกซึ่งสะกดจุดเริ่มต้นของคำ Iehova ขวา: เส้นทางผ่าน trie ที่ทำเครื่องหมายด้วยขอบหนาสำหรับกระเบื้องที่เลือก node ที่วงกลมสอดคล้องกับกระเบื้องที่เลือก
เมื่อเราดูฉากในภาพยนตร์ เรามองว่าความท้าทายที่แท้จริงคือการหาคำใบ้หรือการกระโดดลงบนกระเบื้องเป้าหมายอย่างแม่นยำ แต่แทบไม่คิดถึงการระบุกระเบื้องตามตัวอักษรของคำใบ้เลย สิ่งนี้ดูชัดเจนจนเราไม่คิดถึงมันเลย ซึ่งแสดงให้เห็นอีกครั้งว่าการดำเนินการตามอัลกอริทึมที่มีประสิทธิภาพนั้นเป็นธรรมชาติสำหรับเราเพียงใด เช่นเดียวกับฮันเซลกับเกรเทลและเชอร์ล็อก โฮล์มส์ การผจญภัยของอินเดียน่า โจนส์และการอยู่รอดของเขาขึ้นอยู่กับหลักการพื้นฐานของการคำนวณ
และสุดท้าย ถ้าคุณยังคงสงสัยเกี่ยวกับวิธีที่จะไม่ทำกุญแจรถหายอีกต่อไป มันง่ายมาก: เมื่อคุณกลับบ้าน วางมันไว้ที่ตำแหน่งเฉพาะที่เดียวเสมอ ตำแหน่งนี้คือกุญแจสู่กุญแจ แต่คุณน่าจะรู้อยู่แล้ว