เนื้อหาของ บทที่ 12 นั้นเน้นไปที่การอธิบายว่ารีเคอร์ชันคืออะไร รูปแบบต่างๆ ของรีเคอร์ชัน และความสัมพันธ์ระหว่างรีเคอร์ชันกับลูป การดำเนินการของอัลกอริทึม ToDo และ Count แสดงให้เห็นว่าการทำงานของรีเคอร์ชันเชิงพรรณนานำไปสู่รีเคอร์ชันที่ถูกคลี่ออก ซึ่งเผยให้เห็นว่าความเชื่อมโยงระหว่างการอ้างอิงตนเองและความคล้ายตนเองคือการคำนวณ อย่างไรก็ตาม เรายังไม่ได้พิจารณาอย่างละเอียดว่ารีเคอร์ชันทำงานอย่างไรในเชิงการคำนวณ
บทนี้จะอธิบายว่าอัลกอริทึมแบบรีเคอร์ซีฟสามารถถูกดำเนินการได้อย่างไร ประเด็นที่น่าสนใจคือการดำเนินการของอัลกอริทึมหนึ่งนำไปสู่การดำเนินการหลายครั้งของอัลกอริทึมเดียวกันผ่านทางรีเคอร์ชัน พฤติกรรมพลวัตของอัลกอริทึมแบบรีเคอร์ซีฟสามารถอธิบายได้สองวิธี
วิธีแรก คือการใช้ การแทนที่ (substitution) ซึ่งช่วยให้สามารถสร้างร่องรอยการคำนวณจากนิยามแบบรีเคอร์ซีฟได้ การแทนที่อาร์กิวเมนต์ด้วยพารามิเตอร์เป็นกิจกรรมพื้นฐานที่เกิดขึ้นทุกครั้งเมื่อเราดำเนินการอัลกอริทึม สำหรับการดำเนินการอัลกอริทึมแบบรีเคอร์ซีฟ การแทนที่ยังถูกใช้เพื่อแทนที่การเรียกอัลกอริทึมด้วยนิยามของมันอีกด้วย ด้วยวิธีนี้ การแทนที่สามารถกำจัดรีเคอร์ชันเชิงพรรณนาและแปลงมันให้เป็นร่องรอยที่สามารถใช้อธิบายการทำงานของอัลกอริทึมแบบรีเคอร์ซีฟได้
วิธีที่สอง คือแนวคิดของ อินเทอร์พรีเตอร์ (interpreter) ซึ่งเป็นอีกแนวทางหนึ่งในการอธิบายอัลกอริทึมแบบรีเคอร์ซีฟ อินเทอร์พรีเตอร์คือเครื่องคอมพิวเตอร์ชนิดพิเศษที่ดำเนินการอัลกอริทึมโดยใช้โครงสร้างข้อมูลแบบสแต็ก (ดู บทที่ 4 ) เพื่อติดตามการเรียกรีเคอร์ซีฟ (และนอนรีเคอร์ซีฟ) และสำเนาหลายชุดของอาร์กิวเมนต์ที่เกิดขึ้นจากการทำงานของอัลกอริทึมแบบรีเคอร์ซีฟ การทำงานของอินเทอร์พรีเตอร์นั้นซับซ้อนกว่าการแทนที่ แต่มันให้มุมมองอีกแบบหนึ่งเกี่ยวกับการดำเนินการของอัลกอริทึมแบบรีเคอร์ซีฟ ยิ่งไปกว่านั้น อินเทอร์พรีเตอร์ยังสามารถสร้างร่องรอยการคำนวณที่เรียบง่ายกว่าที่ได้จากการแทนที่ เนื่องจากมันบรรจุเฉพาะข้อมูลเท่านั้น ไม่มีคำสั่งประกอบอยู่ด้วย นอกจากการอธิบายว่ารีเคอร์ชันทำงานอย่างไรแล้ว ทั้งสองแบบจำลองนี้ยังช่วยอธิบายอีกแง่มุมหนึ่งของรีเคอร์ชัน นั่นคือความแตกต่างระหว่างรีเคอร์ชันเชิงเส้นและรีเคอร์ชันไม่เชิงเส้น
Rewriting History (การเขียนประวัติศาสตร์ใหม่)
อัลกอริทึมในฐานะเครื่องมือสำหรับแก้ปัญหานั้นจะมีประโยชน์ก็ต่อเมื่อมันสามารถแก้ปัญหาที่เกี่ยวข้องกันหลายๆ ปัญหาได้ (ดู บทที่ 2 ) ถ้าอัลกอริทึมชนิดหนึ่งสามารถแก้ปัญหาได้เพียงปัญหาเดียว เช่น การหาเส้นทางที่สั้นที่สุดจากบ้านไปที่ทำงาน คุณก็แค่ดำเนินการอัลกอริทึมนั้นสักครั้งแล้วจำเส้นทางนั้นไว้ แล้วก็ลืมอัลกอริทึมทิ้งไป แต่ในทางกลับกัน ถ้าอัลกอริทึมนั้นมีพารามิเตอร์และสามารถหาเส้นทางที่สั้นที่สุดระหว่างสถานที่ต่างๆ ได้ มันก็จะมีประโยชน์อย่างมาก เพราะสามารถนำไปใช้ได้ในหลายสถานการณ์
เมื่ออัลกอริทึมถูกดำเนินการ การคำนวณที่เกิดขึ้นจะทำงานกับค่าที่ป้อนเข้าไปซึ่งถูก แทนที่ ลงในพารามิเตอร์ อัลกอริทึมการตื่นนอนใน บทที่ 2 ประกอบด้วยคำสั่ง "ตื่นนอนเวลา เวลาปลุก . " ในการดำเนินการอัลกอริทึมนั้น จะต้องระบุค่าเวลาที่เป็นรูปธรรม เช่น 6:30 น. (เช่น โดยการตั้งนาฬิกาปลุก) ดังนั้นคำสั่งจึงกลายเป็น "ตื่นนอนเวลา 6:30 น." ซึ่งได้มาจากการแทนที่ค่า 6:30 น. ลงในพารามิเตอร์ เวลาปลุก ในอัลกอริทึม
กลไกการแทนที่นี้ใช้ได้กับอัลกอริทึมทั้งหมดและพารามิเตอร์ของมัน เช่น ถ้วยน้ำสำหรับชงกาแฟ ก้อนกรวดสำหรับหาเส้นทาง สภาพอากาศสำหรับพยากรณ์อากาศ และอื่นๆ แน่นอนว่าการแทนที่พารามิเตอร์ยังใช้ได้กับอัลกอริทึมแบบรีเคอร์ซีฟด้วย ตัวอย่างเช่น quicksort และ mergesort ต้องการลิสต์ที่จะจัดเรียงเป็นอินพุต binary search มีพารามิเตอร์สองตัว คือรายการที่จะค้นหาและโครงสร้างข้อมูล (ต้นไม้หรืออาร์เรย์) ที่ใช้ในการค้นหา และอัลกอริทึม Count (ดู บทที่ 12 ) รับลิสต์ที่จะนับเป็นอินพุตสำหรับพารามิเตอร์ของมัน
นอกจากนี้ การแทนที่อีกชนิดหนึ่งก็มีบทบาทในการดำเนินการของอัลกอริทึมแบบรีเคอร์ซีฟ นั่นคือการแทนที่นิยามของอัลกอริทึมด้วยชื่อของมัน ดังเช่นในการสาธิตว่า Count คำนวณจำนวนสิ่งของที่มาร์ตี้พกติดตัวไปในการเดินทางสู่ปี 1885 ได้อย่างไร ลองกลับไปดูสมการที่นิยามว่าอัลกอริทึม Count ทำอะไรกับลิสต์ที่ไม่ว่าง:
Count ( x → rest ) = Count ( rest ) + 1
ขั้นแรก มีการแทนที่ลิสต์อาร์กิวเมนต์ลงในพารามิเตอร์ การดำเนินการ Count บนลิสต์ B→W→H หมายถึงการแทนที่ลิสต์นั้นลงในพารามิเตอร์ของ Count เนื่องจากพารามิเตอร์ของ Count ถูกแสดงในสมการเป็นแพทเทิร์นที่ประกอบด้วยสองส่วน กระบวนการจับคู่ลิสต์กับแพทเทิร์นนี้จึงเกิดการแทนที่สองครั้ง คือ B แทนที่ x และ W→H แทนที่ rest การแทนที่นี้ส่งผลกระทบต่อด้านขวาของสมการ ซึ่งนิยามขั้นตอนต่างๆ ของอัลกอริทึม — ในกรณีนี้คือการดำเนินการของอัลกอริทึม Count บน rest และการบวก 1 เข้ากับจำนวนที่ได้ ซึ่งนำไปสู่สมการต่อไปนี้:
Count (B→W→H) = Count (W→H) + 1
สมการนี้สามารถเข้าใจได้ว่าเป็นนิยามของอัลกอริทึมที่ถูกปรับใช้สำหรับกรณีตัวอย่างหนึ่ง แต่ก็สามารถมองเป็น การแทนที่การเรียกอัลกอริทึมด้วยนิยามของมันได้เช่นกัน
สิ่งนี้จะชัดเจนขึ้นถ้าเราใช้สัญกรณ์สำหรับการอนุพัทธ์ (derivation) ที่กล่าวถึงครั้งแรกใน บทที่ 8 อย่างที่คุณอาจจำได้ ลูกศรถูกใช้เพื่อบ่งบอกว่าสัญลักษณ์ทางไวยากรณ์ที่ไม่ใช่เทอร์มินัลถูกขยายด้วยด้านขวาของนิยามอย่างไร ลำดับการขยายดังกล่าวสามารถใช้เพื่ออนุพัทธ์สตริงหรือต้นไม้ไวยากรณ์โดยใช้กฎไวยากรณ์ของภาษา เราสามารถมองสมการนิยามของอัลกอริทึมแบบรีเคอร์ซีฟในลักษณะเดียวกับกฎสำหรับการอนุพัทธ์การคำนวณ โดยใช้สัญกรณ์ลูกศร เราสามารถเขียนสมการข้างต้นใหม่ได้ดังนี้:
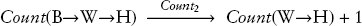
สัญกรณ์ลูกศรเน้นให้เห็นว่า Count (W→H) + 1 เป็นผลลัพธ์ของการแทนที่, หรือ การแทนที่ การเรียกอัลกอริทึม Count ด้วยนิยามของมัน ป้ายกำกับ Count 2 เหนือลูกศรบ่งบอกว่าเราใช้สมการที่สองสำหรับ Count ในการทำเช่นนั้น เนื่องจากผลลัพธ์ยังคงมีการเรียก Count อยู่ เราจึงสามารถใช้กลยุทธ์นี้ซ้ำและแทนที่นิยามของมันอีกครั้ง โดยต้องแน่ใจว่าได้แทนที่ลิสต์อาร์กิวเมนต์ใหม่ W→H ลงในพารามิเตอร์ด้วย คราวนี้เราต้องใช้สมการที่สองอีกครั้ง เนื่องจากลิสต์อาร์กิวเมนต์ไม่ว่าง:
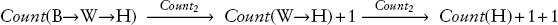
ขั้นตอนสุดท้ายนี้แสดงให้เห็นว่าการแทนที่โดยทั่วไปเกิดขึ้นภายในบริบทที่ไม่ได้รับผลกระทบจากการแทนที่ กล่าวอีกนัยหนึ่ง การแทนที่จะเปลี่ยนส่วนหนึ่งของพจน์ที่ใหญ่กว่าและทำการเปลี่ยนแปลงเฉพาะในระดับท้องถิ่นเท่านั้น คล้ายกับการเปลี่ยนหลอดไฟมาก หลอดไฟเก่าถูกถอดออก และใส่หลอดใหม่เข้าไปแทนที่ โดยที่โคมไฟและส่วนอื่นๆ ของสภาพแวดล้อมยังคงไม่เปลี่ยนแปลง ในตัวอย่างนี้ การแทนที่ Count (H) + 1 ด้วย Count (W→H) เกิดขึ้นในบริบทของ "+ 1" เราจำเป็นต้องใช้ขั้นตอนการแทนที่อีกสองขั้นตอนเพื่อทำให้การขยายสมบูรณ์และกำจัดการเกิดรีเคอร์ซีฟทั้งหมดของ Count:
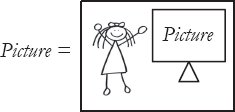
รูปที่ 13.1 นิยามภาพแบบรีเคอร์ซีฟ ชื่อถูกกำหนดให้กับภาพหนึ่ง ซึ่งภายในภาพนั้นมีชื่อนั้นและด้วยเหตุนี้จึงมีการอ้างอิงถึงตัวเอง ความหมายของนิยามที่อ้างอิงตนเองนี้สามารถหาได้โดยการแทนที่สำเนาของภาพที่ย่อส่วนลงซ้ำๆ แทนที่ชื่อของมัน จึงเป็นการผลิตการคลี่คลายของรีเคอร์ชันทีละขั้นตอน
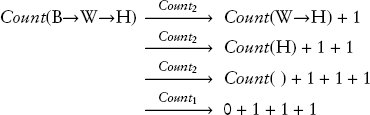
สังเกตว่าขั้นตอนการแทนที่ขั้นสุดท้ายใช้กฎข้อแรกสำหรับ Count ซึ่งใช้กับลิสต์ว่าง เมื่อเราได้กำจัดรีเคอร์ชันทั้งหมดและได้พจน์เลขคณิตแล้ว เราก็สามารถประเมินค่าและรับผลลัพธ์ได้
เราสามารถใช้กลยุทธ์เดียวกันกับอัลกอริทึม ToDo และ Goal และใช้การแทนที่เพื่อติดตามการดำเนินการของอัลกอริทึมย้อนเวลาที่เป็นรีเคอร์ซีฟ ทำให้เกิดลำดับของการกระทำ:

ตัวอย่างเหล่านี้แสดงให้เห็นว่าการอ้างอิงตนเองที่อาจดูน่าฉงนในรีเคอร์ชันเชิงพรรณนาสามารถแก้ไขได้ด้วยการแทนที่ชื่อซ้ำๆ ด้วยนิยามของมัน การแทนที่นิยามซ้ำๆ นี้ใช้ได้แม้กระทั่งกับภาพรีเคอร์ซีฟที่แสดงห้องที่มีทีวีซึ่งแสดงภาพของห้องนั้น (ดู รูปที่ 13.1 )
นี่คือขั้นตอนสองสามขั้นตอนแรกที่แสดงให้เห็นว่าการแทนที่ซ้ำๆ เปลี่ยนรีเคอร์ชันเชิงพรรณนาให้กลายเป็นรีเคอร์ชันที่คลี่ออกได้อย่างไร:

แน่นอนว่ากระบวนการแทนที่นี้ไม่มีวันสิ้นสุด เนื่องจากรีเคอร์ชันไม่มีขอบเขตและไม่มีกรณีฐาน สถานการณ์นี้คล้ายคลึงกับนิยามของลิสต์ของเลข 1 ที่ไม่มีที่สิ้นสุด:
Ones = 1→ Ones
เมื่อดำเนินการตามนิยามนี้ การแทนที่จะสร้างลิสต์ที่ยาวขึ้นเรื่อยๆ ในแต่ละขั้น จะมีการเพิ่มเลข 1 เข้าไปในลิสต์อีกหนึ่งตัว:
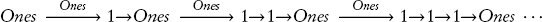
กระบวนการแทนที่ชื่อซ้ำๆ ด้วยนิยามนี้เรียกว่า การเขียนใหม่ (rewriting) ดังนั้นเมื่อเรามองการเดินทางข้ามเวลาของมาร์ตี้เป็นการคำนวณ เขากำลังเขียนประวัติศาสตร์ใหม่นั่นเอง
A Smaller Footprint (รอยเท้าที่เล็กลง)
การแทนที่เป็นกลไกที่เรียบง่ายสำหรับการผลิตร่องรอยของการคำนวณ ซึ่งโดยพื้นฐานแล้วคือลำดับของภาพรวมของผลลัพธ์หรือสถานะระหว่างกลาง มันใช้ได้ทั้งกับอัลกอริทึมแบบนอนรีเคอร์ซีฟและรีเคอร์ซีฟ แต่มันมีประโยชน์อย่างยิ่งสำหรับอัลกอริทึมแบบรีเคอร์ซีฟเพราะมันกำจัดการอ้างอิงตนเองและเปลี่ยนรีเคอร์ชันเชิงพรรณนาให้เป็นรีเคอร์ชันที่คลี่ออกอย่างเป็นระบบ เมื่อเราสนใจเฉพาะผลลัพธ์ของการคำนวณ ไม่ใช่ขั้นตอนระหว่างกลาง การแทนที่ก็ทำงานเกินความจำเป็น แต่มูลค่าของร่องรอยการแทนที่อยู่ที่ความสามารถในการอธิบายการคำนวณที่เกิดขึ้น ร่องรอยของ Count เป็นตัวอย่างหนึ่งของกรณีนี้
อย่างไรก็ตาม แม้ว่าร่องรอยการแทนที่จะช่วยให้เข้าใจได้ แต่มันก็อาจทำให้เสียสมาธิเมื่อมันใหญ่เกินไป ลองพิจารณาอัลกอริทึม insertion sort อีกครั้ง (ดู บทที่ 6 ) นี่คือนิยามแบบรีเคอร์ซีฟของอัลกอริทึม Isort ซึ่งใช้ลิสต์สองลิสต์ คือลิสต์ขององค์ประกอบที่ยังต้องจัดเรียง และลิสต์ขององค์ประกอบที่เรียงลำดับแล้ว:
| Isort ( , list ) | = list |
| Isort ( x → rest , list ) | = Isort( rest , Insert ( x , list )) |
Insert ( w , ) | = w |
| Insert ( w , x → rest ) | = if w ≤ x then w → x → rest else x → Insert ( w , rest ) |

รูปที่ 13.2 ร่องรอยการแทนที่สำหรับการดำเนินการของ insertion sort
อัลกอริทึม Isort มีสองอาร์กิวเมนต์ มัน traverses ลิสต์แรกและดำเนินการอัลกอริทึมเสริม Insert สำหรับแต่ละองค์ประกอบของลิสต์ ถ้าลิสต์ขององค์ประกอบที่ต้องจัดเรียงว่าง ไม่จำเป็นต้องจัดเรียงอีก และพารามิเตอร์ที่สอง list จะบรรจุผลลัพธ์สุดท้าย มิฉะนั้น อัลกอริทึม Insert จะย้ายองค์ประกอบ w จากลิสต์ที่ยังไม่ได้จัดเรียงไปยังตำแหน่งที่ถูกต้องในลิสต์ที่เรียงลำดับแล้ว ถ้าลิสต์นั้นว่าง w เพียงอย่างเดียวก็ถือเป็นลิสต์ที่เรียงลำดับแล้ว มิฉะนั้น Insert จะเปรียบเทียบ w กับองค์ประกอบแรก ( x ) ของลิสต์ที่มันจะถูกแทรกเข้าไป ถ้า w น้อยกว่าหรือเท่ากับ x ก็พบตำแหน่งที่ถูกต้องแล้ว และ w ถูกวางไว้ที่จุดเริ่มต้นของลิสต์ มิฉะนั้น Insert จะเก็บ x ไว้ที่ตำแหน่งเดิมและพยายามแทรก w ลงในลิสต์ที่เหลือ rest แน่นอนว่าวิธีนี้จะใช้ได้ก็ต่อเมื่อลิสต์ที่มันจะถูกแทรกเข้าไปนั้นเรียงลำดับแล้ว ซึ่งเป็นเช่นนั้นเพราะลิสต์นั้นถูกสร้างขึ้นโดยใช้อัลกอริทึม Insert เท่านั้น
ดังที่ รูปที่ 13.2 แสดงให้เห็น การสร้างลิสต์ที่เรียงลำดับแล้วต้องใช้หลายขั้นตอน และผลของการดำเนินการต่างๆ ของอัลกอริทึม Insert นั้นถูกบดบังบางส่วนจากการมีเงื่อนไข (conditional) และความจริงที่ว่าลิสต์ระหว่างกลางถูกแสดง สองครั้ง ชั่วคราวในทางเลือกของเงื่อนไข ในขณะที่ร่องรอยที่ได้จากการแทนที่นั้นแม่นยำและแสดงสิ่งที่อัลกอริทึมทำจริงๆ แต่มันก็ต้องใช้ความตั้งใจและสมาธิอย่างมากในการเจาะลึกผ่านรายละเอียดทั้งหมด และเพื่อแยกข้อมูลออกจากคำสั่ง
อีกแง่มุมหนึ่งของวิธีการแทนที่ที่อาจทำให้สับสนคือในหลายกรณีมีการแทนที่ที่แตกต่างกันหลายแบบ และแม้ว่าตัวเลือกโดยทั่วไปจะไม่ส่งผลต่อผลลัพธ์ แต่มันอาจส่งผลต่อขนาดของร่องรอยและความเข้าใจได้ ตัวอย่างเช่น รูปที่ 13.2 แสดงให้เห็นว่าการแทนที่ครั้งแรกให้ผลลัพธ์ Isort (W→H, Insert (B, )), ซึ่งมีการแทนที่สองแบบที่สามารถใช้ได้: เราสามารถใช้สมการแรกสำหรับ Insert หรือสมการที่สองสำหรับ Isort.
บทที่ 6 แสดงร่องรอยเฉพาะข้อมูลเพื่ออธิบายอัลกอริทึมการจัดเรียงต่างๆ: สำหรับแต่ละองค์ประกอบที่ถูกย้าย จะแสดงเฉพาะลิสต์ที่ยังไม่ได้จัดเรียงและลิสต์ที่เรียงลำดับแล้วเท่านั้น (ดูภาพประกอบของ insertion sort ใน รูปที่ 6.2 ) ถ้าเราใช้การแสดงภาพแบบเดียวกันกับตัวอย่างนี้ เราจะได้ร่องรอยที่สั้นและกระชับกว่ามากเมื่อเทียบกับใน รูปที่ 13.2 :

ร่องรอยเฉพาะข้อมูลดูเรียบง่ายกว่ามากเพราะมันไม่มีคำสั่งใดๆ จากอัลกอริทึม (สิ่งนี้เผยให้เห็นว่าอินเทอร์พรีเตอร์ทำงานอย่างไรโดยทั่วไป: มันแยกคำอธิบายอัลกอริทึมหรือโปรแกรมออกจากข้อมูลที่จะถูกจัดการ) นอกจากนี้ ร่องรอยเฉพาะข้อมูลยังแสดงเฉพาะผลกระทบของ Isort ต่อลิสต์ทั้งสอง โดยละเว้นรายละเอียดว่า Insert ย้ายองค์ประกอบภายในลิสต์ที่สองอย่างไร ยิ่งไปกว่านั้น โปรแกรมถูกแสดงเพียงครั้งเดียวและไม่ถูกเปลี่ยนแปลงเลย เมื่ออัลกอริทึมถูกตีความ (interpreted) ร่องรอยเฉพาะข้อมูลจะนำเสนอเฉพาะข้อมูลในขณะที่มันพัฒนาไป
ในขณะที่ร่องรอยในวิธีการแทนที่มีหน้าที่สองอย่างคือการติดตามวิวัฒนาการของข้อมูลและความก้าวหน้าของการคำนวณ อินเทอร์พรีเตอร์ใช้โครงสร้างข้อมูลแบบสแต็กสำหรับแต่ละงานทั้งสองนี้ โดยเฉพาะอย่างยิ่ง สำหรับอัลกอริทึมแบบรีเคอร์ซีฟ อินเทอร์พรีเตอร์ต้องติดตามสำหรับการเรียกรีเคอร์ซีฟแต่ละครั้งว่าค้างไว้ที่จุดไหน เพื่อจะได้กลับไปและดำเนินการคำนวณต่อหลังจากที่การเรียกรีเคอร์ซีฟเสร็จสิ้น เนื่องจากการดำเนินการแบบรีเคอร์ซีฟแต่ละครั้งของอัลกอริทึมมีอาร์กิวเมนต์ของตัวเอง อินเทอร์พรีเตอร์จึงต้องสามารถรักษาพารามิเตอร์หลายเวอร์ชันได้เช่นกัน
ความต้องการทั้งสองนี้สามารถบรรลุได้โดยการเก็บที่อยู่ของโปรแกรมและค่าพารามิเตอร์ไว้บนสแต็ก มาดูกันว่าวิธีนี้ทำงานอย่างไรโดยการดำเนินการอัลกอริทึม ToDo เพื่อช่วยในการกระโดดกลับจากการเรียกรีเคอร์ซีฟ เราต้องทำเครื่องหมายตำแหน่งในอัลกอริทึม ซึ่งเราจะใช้ตัวเลข เนื่องจากพารามิเตอร์ของอัลกอริทึม ToDo ไม่ได้ถูกใช้ในนิยามใดๆ เราจึงสามารถละเว้นมันและเก็บเฉพาะตำแหน่งบนสแต็กได้ อัลกอริทึมถูกนำเสนอในรูปแบบที่ปรับเปลี่ยนเล็กน้อย โดยที่ตัวเลขทำเครื่องหมายตำแหน่งระหว่างคำสั่ง:
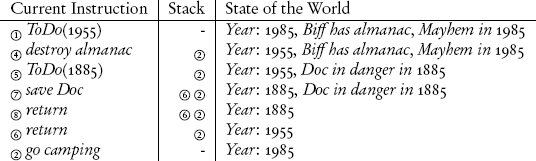
รูปที่ 13.3 การตีความ ToDo (1985) ถ้าคำสั่งปัจจุบันเป็นการเรียกรีเคอร์ซีฟ ที่อยู่ที่ตามหลังมันจะถูกจดจำไว้บนสแต็กเพื่อให้สามารถดำเนินการต่อหลังจากที่มันเสร็จสิ้น สิ่งนี้เกิดขึ้นเมื่อใดก็ตามที่พบคำสั่ง return หลังจากกระโดดกลับ ที่อยู่จะถูกลบออกจากสแต็ก
ToDo (1985) = ① ToDo (1955) ② go camping ③ return
ToDo (1955) = ④ destroy almanac ⑤ ToDo (1885) ⑥ return
ToDo (1885) = ⑦ save Doc ⑧ return
อินเทอร์พรีเตอร์ดำเนินการอัลกอริทึมที่ประยุกต์ใช้กับอาร์กิวเมนต์ เช่น ToDo (1985) โดยทำคำสั่งทีละคำสั่งและเก็บที่อยู่ที่จะกระโดดกลับไว้บนสแต็ก เมื่อใดก็ตามที่คำสั่งเป็นการดำเนินการแบบรีเคอร์ซีฟของอัลกอริทึม ที่อยู่ที่ตามหลังคำสั่งนั้นจะถูก push ขึ้นไปบนสุดของสแต็ก ก่อนที่อินเทอร์พรีเตอร์จะกระโดดไปยังคำสั่งที่ระบุโดยการเรียกรีเคอร์ซีฟ ในตัวอย่าง คำสั่งแรกคือการกระโดดที่ทำให้ที่อยู่ ② ถูก push ขึ้นบนสแต็ก และทำให้ ④ กลายเป็นคำสั่งถัดไป
สิ่งนี้แสดงให้เห็นในสองบรรทัดแรกของ รูปที่ 13.3 ซึ่งแสดงให้เห็นว่าคำสั่งปัจจุบันและสแต็กเปลี่ยนแปลงไปอย่างไรระหว่างการดำเนินการของอัลกอริทึม คอลัมน์ที่สองแสดงสแต็ก โดยด้านซ้ายคือด้านบนและด้านขวาคือด้านล่าง รูปภาพยังแสดงส่วนหนึ่งของโลกที่เปลี่ยนแปลงไปตามการดำเนินการของคำสั่ง เช่น ปีปัจจุบันหรือการครอบครองสมุดบันทึกกีฬา ข้อเท็จจริงเฉพาะนี้เกี่ยวกับโลกเปลี่ยนแปลงหลังจากที่มาร์ตี้ทำลายสมุดบันทึกกีฬาในปี 1955 อย่างไรก็ตาม โปรดสังเกตว่าข้อเท็จจริงที่ว่า Doc Brown ตกอยู่ในอันตรายไม่ใช่ผลมาจากการดำเนินการของอัลกอริทึมปัจจุบัน แต่การเปลี่ยนแปลงมันเป็นส่วนหนึ่งของขั้นตอนถัดไปของอัลกอริทึม หลังจากเดินทางไปปี 1885 ซึ่งทำให้ที่อยู่สำหรับกลับอีกอัน ⑥ ถูก push ขึ้นบนสแต็ก การกระทำเพื่อช่วย Doc Brown จะเปลี่ยนแปลงข้อเท็จจริงเกี่ยวกับการที่เขาตกอยู่ในอันตราย คำสั่งถัดไปในอัลกอริทึมคือการกลับไปยังจุดที่อัลกอริทึมค้างไว้เมื่อมีการกระโดดแบบรีเคอร์ซีฟ เป้าหมายสำหรับการกระโดดกลับคือที่อยู่สุดท้ายที่ถูก push ขึ้นบนสแต็ก และจึงสามารถพบได้ที่ด้านบนของสแต็ก ดังนั้น การดำเนินการของคำสั่ง return ทำให้คำสั่งถัดไปเป็นคำสั่งที่ที่อยู่ ⑥ ซึ่งเป็น return อีกอันที่ pop ที่อยู่กลับออกจากสแต็กเช่นกัน สิ่งนี้เผยให้เห็นที่อยู่เป้าหมายสำหรับคำสั่ง return ถัดไป ซึ่งคือ ② ซึ่งเป็นจุดที่มาร์ตี้และเจนนิเฟอร์สามารถไปตั้งแคมป์ได้ในที่สุด
ตัวอย่าง ToDo แสดงให้เห็นว่าการเรียกที่ซ้อนกันของอัลกอริทึมนำไปสู่การเก็บที่อยู่กลับไว้บนสแต็ก แต่มันไม่จำเป็นต้องเก็บค่าพารามิเตอร์บนสแต็ก เพื่อแสดงให้เห็นแง่มุมนี้ของอินเทอร์พรีเตอร์ เราจะพิจารณาอัลกอริทึม Isort อีกครั้ง ซึ่งจำเป็นต้องทำเช่นนี้ อย่างไรก็ตาม เราไม่จำเป็นต้องเก็บที่อยู่กลับเพราะแต่ละขั้นตอนของอัลกอริทึมถูกกำหนดโดยพจน์เดียวเท่านั้น ไม่ใช่ลำดับของหลายพจน์อย่างในกรณีของ ToDo.
ในการจัดเรียงลิสต์สิ่งของของมาร์ตี้ อินเทอร์พรีเตอร์เริ่มต้นด้วยการประเมินการเรียก Isort (B→W→H, ) ด้วยสแต็กว่าง การจับคู่อาร์กิวเมนต์กับแพทเทิร์นพารามิเตอร์ของ Isort นำไปสู่ การผูก (bindings) ซึ่งเป็นการเชื่อมโยงระหว่างชื่อพารามิเตอร์ที่ใช้ในแพทเทิร์นกับค่า การผูกเหล่านี้ถูก push ขึ้นบนสแต็ก ทำให้เกิดสแต็กดังที่แสดงใน รูปที่ 13.4 A อาจดูแปลกที่ในขณะที่อัลกอริทึม Isort รับอินพุตสองตัว การประยุกต์ใช้กับอินพุตแรกที่ไม่ว่างกลับสร้างการผูกสำหรับพารามิเตอร์สามตัวบนสแต็ก ทั้งนี้เพราะอาร์กิวเมนต์แรกถูกจับคู่กับแพทเทิร์น x → rest ซึ่งประกอบด้วยพารามิเตอร์สองตัวที่มีจุดประสงค์เพื่อแยกลิสต์อาร์กิวเมนต์ออกเป็นสองส่วน คือองค์ประกอบแรกและส่วนท้ายของลิสต์ สมการแรกสร้างการผูกสำหรับพารามิเตอร์เพียงตัวเดียว เพราะอินพุตแรกเป็นที่รู้กันว่าเป็นลิสต์ว่างและไม่จำเป็นต้องอ้างอิงด้วยชื่อ
หลังจากการจับคู่แพทเทิร์น ซึ่งสร้างการผูกพารามิเตอร์บนสแต็ก อัลกอริทึมจะสั่งให้คำนวณ Isort ( rest , Insert ( x , list )) เช่นเดียวกับวิธีการแทนที่ อินเทอร์พรีเตอร์ตอนนี้มีสองเส้นทางที่สามารถดำเนินการได้: ดำเนินการต่อด้วยการเรียก Isort ภายนอก หรือจัดการกับการเรียก Insert ที่ซ้อนกันก่อน ภาษาโปรแกรมส่วนใหญ่จะประเมินอาร์กิวเมนต์ก่อนที่จะดำเนินการอัลกอริทึม 1 ตามกลยุทธ์นี้ อินเทอร์พรีเตอร์จะประเมิน Insert ( x , list ) ก่อนที่จะประเมินการเรียก Isort ต่อไป ค่าสำหรับ x และ list สามารถดึงมาจากสแต็กและนำไปสู่การประเมิน Insert (B, ) การประเมินนี้สามารถดำเนินการด้วยสแต็กแยกต่างหากและผลิตรายการผลลัพธ์ B ซึ่งหมายความว่าการประเมินการเรียก Isort กลายเป็น Isort ( rest , B)
อินเทอร์พรีเตอร์ประเมิน Isort ( rest , B) ด้วยสแต็กดังที่แสดงใน รูปที่ 13.4 A ขั้นแรก ค่าของ rest ถูกดึงมาจากสแต็ก ซึ่งหมายความว่าอินเทอร์พรีเตอร์ประเมินการเรียก Isort (W→H, B) จริงๆ จากนั้นการจับคู่แพทเทิร์นจะสร้างการผูกใหม่สำหรับพารามิเตอร์ของ Isort ที่จะถูก push ขึ้นบนสแต็ก ดังที่แสดงใน รูปที่ 13.4 B .
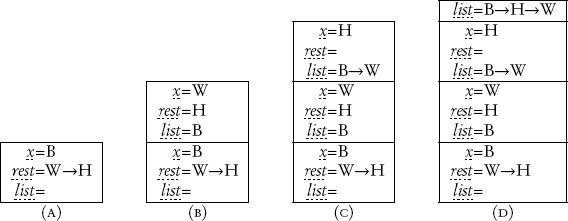
รูปที่ 13.4 ภาพรวมของค่าบนสแต็กระหว่างการตีความ Isort (B→W→H, )
เป็นที่น่าสังเกตว่าพารามิเตอร์ x , rest และ list ปรากฏบนสแต็กสองครั้ง ทั้งนี้เพราะการเรียกรีเคอร์ซีฟของ Isort ดำเนินการกับอาร์กิวเมนต์ที่แตกต่างกันสำหรับพารามิเตอร์ของมัน และดังนั้นจึงต้องการพื้นที่จัดเก็บแยกต่างหากสำหรับพวกมัน เมื่อการเรียกที่ซ้อนกันของ Isort ได้ถูกประมวลผลโดยอินเทอร์พรีเตอร์แล้ว การผูกสำหรับพารามิเตอร์จะถูกนำออก ("pop") จากสแต็ก และการคำนวณของการเรียกก่อนหน้าของ Isort สามารถดำเนินการต่อ โดยเข้าถึงอาร์กิวเมนต์ของตัวเองได้ 2
อย่างไรก็ตาม ก่อนที่จะเสร็จสมบูรณ์ การเรียก Isort นำไปสู่การดำเนินการของสมการที่สองสำหรับ Isort อีกครั้ง ซึ่งกระตุ้นให้เกิดการประเมิน Isort ( rest , Insert ( x , list )) การผูกถูกพบอีกครั้งบนสแต็ก แต่เนื่องจากมีการผูกหลายรายการสำหรับชื่อพารามิเตอร์แต่ละชื่อ คำถามคือควรใช้การผูกใด และจะหามันได้อย่างไร นี่คือจุดที่โครงสร้างข้อมูลแบบสแต็กเข้ามามีบทบาทอีกครั้ง เนื่องจากค่าพารามิเตอร์สำหรับการเรียก Isort ล่าสุดถูก push ขึ้นบนสแต็กเป็นลำดับสุดท้าย มันจึงถูกพบบนสุดของสแต็ก การเรียกที่ได้จึงเป็น Isort (H, Insert (W, B)) เนื่องจาก Insert (W, B) ให้ผลลัพธ์เป็น B→W การเรียกถัดไปของ Isort ที่ต้องประเมินคือ Isort (H, B→W) ซึ่งกระตุ้นสมการที่สองสำหรับ Isort อีกครั้งและนำไปสู่การเรียกอีกครั้ง Isort ( rest , Insert ( x , list )) ด้วยสแต็กดังที่แสดงใน รูปที่ 13.4 C .
เมื่อหาอาร์กิวเมนต์สำหรับพารามิเตอร์จากบนสุดของสแต็ก การเรียกนี้นำไปสู่การประเมิน Isort ( , Insert (H,B→W)) ซึ่งส่งผลให้เป็น Isort ( , B→H→W) หลังจากการประเมิน Insert (H, B→W) เนื่องจากตอนนี้อาร์กิวเมนต์แรกของ Isort เป็นลิสต์ว่าง อินเทอร์พรีเตอร์จึงถูกสั่งให้ประเมิน list โดยสมการแรกสำหรับ Isort การประเมินเกิดขึ้นในบริบทของสแต็กดังที่แสดงใน รูปที่ 13.4 D .
ณ จุดนี้ ค่าสำหรับ list ถูกพบบนสแต็กและถูกส่งกลับเป็นผลลัพธ์สุดท้าย ในที่สุด การสิ้นสุดของการเรียก Isort แต่ละครั้งจะมาพร้อมกับการลบการผูกพารามิเตอร์ออกจากสแต็ก ทำให้สแต็กว่างเปล่า เราสามารถสังเกตได้ว่าสแต็กเติบโตขึ้นตามการเรียก (รีเคอร์ซีฟ) แต่ละครั้งและหดตัวลงหลังจากที่การเรียกเสร็จสมบูรณ์
ร่องรอยสองลิสต์สำหรับ insertion sort ที่แสดงก่อนหน้านี้สามารถสร้างขึ้นอย่างเป็นระบบจากสแต็กใน รูปที่ 13.4 ที่จริงแล้ว สแต็กที่แสดงการซ้อนที่สมบูรณ์ของการเรียก Isort ทั้งหมด ( รูปที่ 13.4D ) ก็เพียงพอสำหรับจุดประสงค์นั้น โดยเฉพาะอย่างยิ่ง แต่ละกลุ่มของการผูกในสแต็กจะสร้างหนึ่งขั้นตอนของร่องรอย จำไว้ว่าแต่ละลิสต์อินพุตที่ไม่ว่างสำหรับ Isort ถูกแยกออกเมื่อ Isort ถูกเรียกเพื่อสร้างการผูกสำหรับพารามิเตอร์สองตัว x และ rest ซึ่งหมายความว่าลิสต์อินพุตสำหรับสามการเรียกแรกของ Isort ถูกกำหนดโดยลิสต์ x → rest และเอาต์พุตถูกกำหนดโดย list สำหรับการเรียกครั้งสุดท้ายของ Isort เมื่อลิสต์อินพุตว่าง ลิสต์อินพุตคือลิสต์ว่าง ซึ่งไม่ได้ถูกแสดงด้วยพารามิเตอร์ และลิสต์เอาต์พุตถูกกำหนดโดย list ดังนั้นรายการล่างสุดของสแต็กให้คู่ของลิสต์ B→W→H และลิสต์ว่าง รายการที่สองให้ W→H และ B รายการที่สามให้ H และ B→W และรายการบนสุดให้ลิสต์ว่าง (ลิสต์อินพุต ไม่ได้ผูกกับพารามิเตอร์) และ B→H→W
การแทนที่และการตีความเป็นสองวิธีในการทำความเข้าใจการดำเนินการของอัลกอริทึม โดยเฉพาะอย่างยิ่งอัลกอริทึมแบบรีเคอร์ซีฟ การแทนที่นั้นง่ายกว่า เพราะมันทำงานกับร่องรอยที่ถูกเขียนใหม่ทีละขั้นตอน ในขณะที่การตีความใช้สแต็กเสริม การแทนที่ผสมรหัสและข้อมูลเข้าด้วยกัน ในขณะที่การตีความแยกพวกมันออกจากกันอย่างชัดเจน ซึ่งทำให้การแยกร่องรอยที่เรียบง่ายทำได้ง่ายขึ้น ในกรณีของรีเคอร์ชันที่ไม่มีขอบเขต การแทนที่ให้ผลลัพธ์ที่มีประโยชน์ ในขณะที่การตีความไม่สิ้นสุด
Doppelgängers Get More Done (ตัวปลอมทำงานได้มากกว่า)
เมื่อมาร์ตี้ย้อนเวลากลับไปปี 1955 เป็นครั้งที่สอง (หลังจากกลับมากับด็อกจากปี 2015 สู่ปี 1985 ที่รุนแรง) เขามีตัวตนอยู่ในปี 1955 สองคน เพราะอดีตที่เขาเดินทางกลับไปนั้นคืออดีตที่เขาเคยเดินทางไปก่อนหน้านี้แล้ว (โดยบังเอิญในภาพยนตร์เรื่องแรก) มาร์ตี้ทั้งสองคนไม่ได้มีปฏิสัมพันธ์กัน และพวกเขาทำสิ่งที่แตกต่างกัน มาร์ตี้คนแรกพยายามทำให้พ่อแม่ของเขาตกหลุมรักกัน ในขณะที่มาร์ตี้คนที่สองพยายามเอาสมุดบันทึกกีฬาคืนจากบิฟฟ์ ในทำนองเดียวกัน เมื่อบิฟฟ์แก่เดินทางจากปี 2015 ไปยังปี 1955 เพื่อมอบสมุดบันทึกกีฬาให้กับตัวเองในวัยหนุ่ม เขาก็มีตัวตนสองคนในปี 1955 เช่นกัน ซึ่งแตกต่างจากมาร์ตี้สองคน บิฟฟ์ทั้งสองคนมีปฏิสัมพันธ์กัน บิฟฟ์แก่มอบสมุดบันทึกกีฬาให้กับบิฟฟ์หนุ่ม โชคดีที่ความขัดแย้งทางกาลอวกาศที่อาจนำไปสู่การทำลายล้างจักรวาลไม่ได้เกิดขึ้น 3 ยิ่งไปกว่านั้น เครื่องย้อนเวลาที่มาร์ตี้ใช้เพื่อกลับจากปี 1985 ไปยังปี 1955 ก็เป็นเครื่องเดียวกับที่บิฟฟ์แก่ใช้เดินทางจากปี 2015 ไปยังปี 1955 ดังนั้น ในขณะที่มาร์ตี้สังเกตเห็นบิฟฟ์แก่มอบสมุดบันทึกกีฬาให้บิฟฟ์หนุ่ม เครื่องย้อนเวลาสองเครื่องจะต้องมีอยู่ในปี 1955 ที่จริงแล้ว สาม เครื่องจะต้องมีอยู่ในเวลาเดียวกันในปี 1955 เพราะมาร์ตี้คนแรกก็เดินทางมาปี 1955 ด้วยเครื่องย้อนเวลาเช่นกัน
สิ่งนี้แสดงให้เห็นว่าผลลัพธ์ที่หลีกเลี่ยงไม่ได้ของการเดินทางข้ามเวลาไปยังอดีตคือการทำซ้ำของวัตถุและบุคคลที่เดินทางข้ามเวลา — อย่างน้อยก็เมื่อมีการเดินทางหลายครั้งไปยังเวลาเดียวกันในอดีต สถานการณ์กับรีเคอร์ชันมีความคล้ายคลึงกันมาก เนื่องจากสมการที่สองสำหรับ Count มีการเกิดรีเคอร์ซีฟของ Count เพียงครั้งเดียว มันจะสร้างเพียงหนึ่งอินสแตนซ์ในเวลาใดๆ ในอดีตเมื่อถูกดำเนินการ เนื่องจากการเรียกรีเคอร์ซีฟแต่ละครั้งจะเดินทางหนึ่งหน่วยเวลาย้อนกลับไปยังอดีตจากเวลาที่มันเกิดขึ้น รูปแบบของรีเคอร์ชันนี้ ซึ่งสิ่งที่ถูกนิยามถูกอ้างอิงเพียงครั้งเดียวในนิยามของมัน เรียกว่า รีเคอร์ชันเชิงเส้น (linear recursion) รีเคอร์ชันเชิงเส้นในอัลกอริทึมนำไปสู่การเกิดการเรียกอัลกอริทึมที่แยกจากกันในอดีต รีเคอร์ชันเชิงเส้นสามารถแปลงเป็นลูปได้ง่าย และโดยทั่วไปแล้วมันไม่นำไปสู่โอกาสในการดำเนินการพร้อมกัน
ในทางตรงกันข้าม กรณีที่นิยามอ้างอิงถึงสิ่งที่ถูกนิยามมากกว่าหนึ่งครั้งเรียกว่า รีเคอร์ชันไม่เชิงเส้น (nonlinear recursion) เนื่องจากการเรียกทั้งหมดเกิดขึ้นในเวลาเดียวกัน การดำเนินการที่สอดคล้องกันจึงเริ่มต้นพร้อมกันในอดีตและเกิดขึ้นพร้อมกัน ซึ่งไม่ได้หมายความว่าคอมพิวเตอร์ (อิเล็กทรอนิกส์หรือมนุษย์) ต้อง ดำเนินการเรียกแบบขนาน มันหมายความเพียงว่าพวกมัน สามารถ ถูกดำเนินการแบบขนานได้ และนี่คือแง่มุมที่น่าทึ่งของอัลกอริทึมแบบ divide-and-conquer ที่ออกแบบมาอย่างดี ไม่เพียงแต่มันจะแบ่งปัญหาอย่างรวดเร็วเพื่อให้ปัญหาสามารถแก้ไขได้ด้วยขั้นตอนไม่กี่ขั้นตอน พวกมันยังรองรับการดำเนินการแบบขนานโดยคอมพิวเตอร์หลายเครื่องอีกด้วย
Quicksort และ mergesort เป็นสองตัวอย่างของอัลกอริทึมดังกล่าว (ดู บทที่ 6 ) นิยามของ quicksort เป็นดังนี้ สมการแรกบอกว่าลิสต์ว่างนั้นเรียงลำดับแล้ว และสมการที่สองบอกว่าในการจัดเรียงลิสต์ที่ไม่ว่าง ควรนำองค์ประกอบทั้งหมดจากส่วนท้ายของลิสต์ ( rest ) ที่มีค่าน้อยกว่า x มาเรียงลำดับและวางไว้ข้างหน้า x และทำนองเดียวกันให้วางผลลัพธ์ของการเรียงลำดับองค์ประกอบที่มากกว่าหรือเท่ากับทั้งหมดไว้หลัง x :
| Qsort ( ) | = |
| Qsort ( x → rest ) | = Qsort ( Smaller ( rest , x ))→ x → Qsort ( Larger ( rest , x )) |
สังเกตว่าสมการที่สองเผยให้เห็นรีเคอร์ชันไม่เชิงเส้นของ Qsort Quicksort ทำงานได้ดีที่สุดเมื่อ x ทำให้ส่วนท้ายถูกแบ่งออกเป็นสองลิสต์ย่อยที่มีขนาดใกล้เคียงกันอย่างสม่ำเสมอ ซึ่งอาจไม่เกิดขึ้นในกรณีที่แย่ที่สุด เมื่อลิสต์ถูกจัดเรียง (เกือบ) เรียบร้อยแล้ว แต่ quicksort ทำงานได้ดีมากโดยเฉลี่ย
ที่จริงแล้ว การดำเนินการ quicksort หรือ mergesort ร่วมกับกลุ่มคนเป็นเรื่องสนุก ในการดำเนินการ quicksort ทุกคนเข้าแถวในคิว และคนแรกเริ่มจัดเรียงโดยใช้สมการที่สองและแบ่งลิสต์ขององค์ประกอบทั้งหมดออกเป็นสองลิสต์ย่อย ขึ้นอยู่กับว่าพวกมันมีค่าน้อยกว่าองค์ประกอบแรกหรือไม่ เธอเก็บองค์ประกอบแรกไว้และมอบลิสต์ย่อยแต่ละลิสต์ให้กับคนใหม่จากคิว ซึ่งจะดำเนินการ quicksort กับลิสต์ที่ได้รับและอาจรับสมัครคนใหม่จากคิวเพื่อจัดเรียงลิสต์ย่อยต่อไป คนที่ได้รับลิสต์ว่างจะเสร็จทันทีและสามารถส่งคืนลิสต์ว่างนั้นได้ ตามนิยามของสมการแรก 4 เมื่อมีคนจัดเรียงลิสต์ของเธอเสร็จแล้ว เธอก็ส่งลิสต์ที่เรียงแล้วกลับไปให้คนที่ให้ลิสต์กับเธอ และทุกคนที่ได้รับลิสต์ย่อยที่เรียงแล้วเป็นผลลัพธ์จะสร้างลิสต์ที่เรียงลำดับของตัวเองโดยวางลิสต์ที่มีองค์ประกอบน้อยกว่าไว้ก่อน x และลิสต์ที่มีองค์ประกอบมากกว่าไว้หลัง x ถ้าเราหยุดรีเคอร์ชันเมื่อลิสต์มีเพียงองค์ประกอบเดียว เราจะต้องใช้คนในการจัดเรียงลิสต์เท่ากับจำนวนองค์ประกอบในลิสต์ เพราะแต่ละคนยึดไว้เพียงองค์ประกอบเดียว กลยุทธ์นี้อาจดูเหมือนเป็นการสิ้นเปลืองทรัพยากรสำหรับการแค่เรียงลำดับลิสต์ แต่ด้วยต้นทุนการคำนวณที่ลดลงเรื่อยๆ และพลังการคำนวณที่เพิ่มขึ้น มันแสดงให้เห็นถึงพลังของ divide-and-conquer และแสดงให้เห็นว่ามือมากทำให้งานเบา