การคำนวณมีประโยชน์อย่างยิ่งเมื่อเราต้องจัดการกับข้อมูลปริมาณมากที่ไม่สามารถจัดการได้ในไม่กี่ขั้นตอน ในกรณีเช่นนี้ อัลกอริทึมที่เหมาะสมสามารถรับประกันได้ว่าข้อมูลทั้งหมดจะถูกประมวลผลอย่างเป็นระบบ และในหลายกรณีก็มีประสิทธิภาพอีกด้วย
สัญญาณ (Signs) ที่กล่าวถึงใน บทที่ 3 แสดงให้เห็นว่าการแทนข้อมูลทำงานอย่างไรสำหรับข้อมูลทีละชิ้น และการแทนนี้กลายเป็นส่วนหนึ่งของการคำนวณได้อย่างไร ตัวอย่างเช่น การเคลื่อนที่ของฮันเซลกับเกรเทลจากก้อนกรวดหนึ่งไปยังอีกก้อนหนึ่งหมายความว่าพวกเขาตกอยู่ในอันตรายจนกว่าจะเคลื่อนที่จากก้อนกรวดสุดท้ายกลับไปยังบ้านของพวกเขา แต่ถึงแม้กลุ่มของสัญญาณจะเป็นสัญญาณในตัวเอง แต่ก็ไม่ชัดเจนว่าจะคำนวณกับกลุ่มดังกล่าวอย่างไร ในกรณีของฮันเซลกับเกรเทล ก้อนกรวดแต่ละก้อนเป็นตัวชี้บอกตำแหน่งหนึ่งตำแหน่ง และกลุ่มของก้อนกรวดทั้งหมดแสดงถึงเส้นทางจากอันตรายสู่ความปลอดภัย แต่กลุ่มดังกล่าวถูกสร้างขึ้นและใช้งานอย่างเป็นระบบได้อย่างไร? การดูแลรักษากลุ่มข้อมูลทำให้เกิดคำถามสองข้อ
ประการแรก ข้อมูลจะถูกแทรก ค้นหา และลบออกจากกลุ่มในลำดับใด คำตอบขึ้นอยู่กับภารกิจการคำนวณที่กลุ่มข้อมูลนั้นเกี่ยวข้อง แต่เราสามารถสังเกตได้ว่ารูปแบบเฉพาะของการเข้าถึงองค์ประกอบในกลุ่มข้อมูลนั้นเกิดขึ้นซ้ำๆ รูปแบบการเข้าถึงข้อมูลดังกล่าวเรียกว่า ชนิดข้อมูล (data type) ตัวอย่างเช่น ก้อนกรวดที่ฮันเซลกับเกรเทลใช้ถูกเข้าถึงในลำดับตรงกันข้ามกับที่วางไว้ รูปแบบการเข้าถึงเช่นนี้เรียกว่า สแต็ก (stack)
ประการที่สอง จะจัดเก็บกลุ่มข้อมูลอย่างไรให้รูปแบบการเข้าถึง หรือชนิดข้อมูล ได้รับการสนับสนุนอย่างมีประสิทธิภาพสูงสุด? คำตอบขึ้นอยู่กับปัจจัยหลากหลาย เช่น ต้องเก็บองค์ประกอบจำนวนเท่าใด? ทราบจำนวนนี้ล่วงหน้าหรือไม่? แต่ละองค์ประกอบต้องการพื้นที่เก็บเท่าใด? องค์ประกอบทั้งหมดมีขนาดเท่ากันหรือไม่? วิธีการจัดเก็บกลุ่มข้อมูลแบบใดแบบหนึ่งเรียกว่า โครงสร้างข้อมูล (data structure) โครงสร้างข้อมูลทำให้กลุ่มข้อมูลพร้อมสำหรับการคำนวณ ชนิดข้อมูลหนึ่งชนิดสามารถนำไปใช้งานได้ด้วยโครงสร้างข้อมูลที่แตกต่างกัน ซึ่งหมายความว่ารูปแบบการเข้าถึงแบบหนึ่งสามารถนำไปใช้งานผ่านวิธีการจัดเก็บข้อมูลที่แตกต่างกัน ความแตกต่างระหว่างโครงสร้างข้อมูลอยู่ที่ประสิทธิภาพในการสนับสนุนการดำเนินการเฉพาะบนกลุ่มข้อมูล นอกจากนี้ โครงสร้างข้อมูลหนึ่งชนิดสามารถนำไปใช้กับชนิดข้อมูลที่แตกต่างกันได้
บทนี้กล่าวถึงชนิดข้อมูลหลายชนิด โครงสร้างข้อมูลที่นำไปใช้งาน และวิธีที่พวกมันถูกใช้เป็นส่วนหนึ่งของการคำนวณ
The Usual Suspects (ผู้ต้องสงสัยตามปกติ)
เมื่อรู้ตัวผู้กระทำความผิดแล้ว (อาจจะมีพยานและคำสารภาพ) เราก็ไม่จำเป็นต้องใช้ฝีมือของเชอร์ล็อก โฮล์มส์ แต่เมื่อมีผู้ต้องสงสัยหลายคน เราจำเป็นต้องติดตามแรงจูงใจ ข้อแก้ตัว และข้อมูลสำคัญอื่นๆ ของพวกเขาเพื่อสืบสวนคดีอย่างละเอียด
ใน The Hound of the Baskervilles ผู้ต้องสงสัยรวมถึงดร. มอร์ติเมอร์, แจ็ก สเตเปิลตันและเบริล ผู้ที่ถูกสันนิษฐานว่าเป็นน้องสาวของเขา (แต่แท้จริงแล้วเป็นภรรยาของเขา), นักโทษที่หลบหนีชื่อเซเดน, นายแฟรงก์แลนด์, และคู่สามีภรรยาบาร์รีมอร์ ผู้รับใช้ของเซอร์ชาร์ลส์ แบสเกอร์วิลล์ผู้ล่วงลับ ก่อนที่วัตสันจะออกเดินทางไปยังแบสเกอร์วิลล์ ฮอลล์ เชอร์ล็อก โฮล์มส์สั่งให้วัตสันรายงานข้อเท็จจริงที่เกี่ยวข้องทั้งหมด แต่ให้ยกเว้นนายเจมส์ เดสมอนด์ออกจากรายชื่อผู้ต้องสงสัย เมื่อวัตสันเสนอให้ยกเว้นคู่สามีภรรยาบาร์รีมอร์ด้วย เชอร์ล็อก โฮล์มส์ตอบว่า:
ไม่ ไม่ เราจะเก็บพวกเขาไว้ในรายชื่อผู้ต้องสงสัยของเรา . 1
การแลกเปลี่ยนสั้นๆ นี้แสดงให้เห็นสองสิ่ง
ประการแรก ถึงแม้เชอร์ล็อก โฮล์มส์จะไม่รู้อะไรเกี่ยวกับโครงสร้างข้อมูลเลย แต่เขาก็กำลังใช้โครงสร้างข้อมูลอยู่ เพราะดูเหมือนว่าเขาได้เก็บรายชื่อผู้ต้องสงสัยไว้ ลิสต์ (list) เป็นโครงสร้างข้อมูลอย่างง่ายสำหรับเก็บรายการข้อมูลโดยการเชื่อมโยงพวกมันเข้าด้วยกัน ลิสต์จัดเตรียมรูปแบบเฉพาะของการเข้าถึงและการจัดการรายการข้อมูลเหล่านี้ ประการที่สอง รายชื่อผู้ต้องสงสัยไม่ใช่สิ่งที่อยู่นิ่ง มันเพิ่มขึ้นและลดลงเมื่อมีผู้ต้องสงสัยใหม่ถูกเพิ่มเข้ามาหรือเมื่อผู้ต้องสงสัยถูกตัดออก การเพิ่ม ลบ หรือเปลี่ยนแปลงรายการในโครงสร้างข้อมูลต้องใช้อัลกอริทึมที่โดยทั่วไปใช้เวลามากกว่าหนึ่งขั้นตอน และระยะเวลาการทำงานของอัลกอริทึมเหล่านี้เองที่เป็นตัวกำหนดว่าโครงสร้างข้อมูลแบบใดเหมาะสมกับงานเฉพาะใด
ด้วยความเรียบง่ายและความคล่องตัว ลิสต์น่าจะเป็นโครงสร้างข้อมูลที่ถูกใช้มากที่สุดในวิทยาการคอมพิวเตอร์และนอกเหนือจากนั้น พวกเราทุกคนใช้ลิสต์เป็นประจำในรูปแบบของรายการสิ่งที่ต้องทำ รายการช้อปปิ้ง รายการหนังสืออ่าน รายการสิ่งที่อยากได้ และการจัดอันดับทุกชนิด ลำดับขององค์ประกอบในลิสต์มีความสำคัญ และโดยทั่วไปแล้วองค์ประกอบจะถูกเข้าถึงทีละตัว เริ่มจากปลายด้านหนึ่งไปยังอีกด้านหนึ่ง ลิสต์มักถูกเขียนในแนวตั้ง หนึ่งองค์ประกอบต่อบรรทัด โดยมีองค์ประกอบแรกอยู่ด้านบน อย่างไรก็ตาม นักวิทยาการคอมพิวเตอร์เขียนลิสต์ในแนวนอน โดยนำเสนอองค์ประกอบจากซ้ายไปขวา เชื่อมต่อด้วยลูกศรเพื่อบอกลำดับขององค์ประกอบ 2 ด้วยสัญกรณ์นี้ เชอร์ล็อก โฮล์มส์สามารถเขียนรายชื่อผู้ต้องสงสัยของเขาได้ดังนี้:
Mortimer → Jack → Beryl → Seiden → …
ลูกศรเรียกว่า พอยน์เตอร์ (pointer) และทำให้การเชื่อมต่อระหว่างองค์ประกอบในลิสต์ชัดเจน ซึ่งสิ่งนี้จะสำคัญเมื่อเราพิจารณาว่าลิสต์ถูกปรับปรุงอย่างไร สมมติว่ารายชื่อผู้ต้องสงสัยของเชอร์ล็อก โฮล์มส์คือ Mortimer → Beryl และเขาต้องการเพิ่ม Jack ระหว่างสองคนนี้

ถ้าองค์ประกอบถูกเขียนเป็นลิสต์แนวตั้งของรายการโดยไม่มีช่องว่างระหว่างกัน เขาจะต้องใช้สัญกรณ์พิเศษบางอย่างเพื่อทำให้ตำแหน่งขององค์ประกอบใหม่ชัดเจน ทางเลือกอื่นคือการเขียนลิสต์ใหม่ทั้งหมดอีกครั้ง แต่นั่นจะเป็นการสิ้นเปลืองเวลาและพื้นที่อย่างมหาศาล ซึ่งจะต้องใช้เวลาและพื้นที่ที่ในกรณีแย่ที่สุดเป็นแบบกำลังสอง (quadratic) เมื่อเทียบกับขนาดของลิสต์สุดท้าย
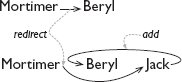
พอยน์เตอร์ให้ความยืดหยุ่นแก่เราในการเขียนองค์ประกอบใหม่ไม่ว่าจะหาที่ว่างได้ที่ไหน และยังคงวางมันไว้ในตำแหน่งที่เหมาะสมในลิสต์โดยการเชื่อมต่อมันกับองค์ประกอบข้างเคียงในลิสต์ ตัวอย่างเช่น เราสามารถวาง Jack ไว้ที่ปลายลิสต์ เปลี่ยนทิศทางพอยน์เตอร์ขาออกจาก Mortimer ไปยัง Jack และเพิ่มพอยน์เตอร์จาก Jack ไปยัง Beryl
ในบริบทของเรื่องราว ลำดับของผู้ต้องสงสัยในลิสต์นี้ไม่มีความหมายและไม่มีนัยสำคัญ แต่เราจะเห็นว่าการสร้างลิสต์บังคับให้เราเลือกลำดับบางอย่างสำหรับองค์ประกอบของมัน มันเป็นคุณลักษณะที่กำหนดของลิสต์ว่าองค์ประกอบของมันถูกเก็บไว้ในลำดับที่เฉพาะเจาะจง
การตรวจสอบองค์ประกอบในลิสต์เกิดขึ้นในลำดับเฉพาะตามที่ลิสต์กำหนด ดังนั้นเพื่อค้นหาว่า Selden เป็นผู้ต้องสงสัยหรือไม่ เราต้องเริ่มต้นที่จุดเริ่มต้นของลิสต์และตรวจสอบองค์ประกอบทีละตัวโดยการเดินตามพอยน์เตอร์ แม้ดูเหมือนว่าเราสามารถเห็นองค์ประกอบ Selden ได้โดยตรงในลิสต์ แต่วิธีนี้ใช้ได้กับลิสต์ขนาดเล็กเท่านั้น เนื่องจากขอบเขตการมองเห็นของเรามีจำกัด เราจึงไม่สามารถจำแนกองค์ประกอบเฉพาะในลิสต์ยาวๆ ได้ทันที และต้องอาศัยการการเดินทางผ่านลิสต์ทีละองค์ประกอบ

การเปรียบเทียบทางกายภาพสำหรับลิสต์คือสมุดห่วงที่บรรจุกระดาษหนึ่งแผ่นสำหรับแต่ละองค์ประกอบ ในการหาองค์ประกอบเฉพาะในสมุดห่วง เราต้องดูทีละหน้า และสามารถแทรกหน้าใหม่ระหว่างหน้าอื่นๆ ได้ทุกที่
คุณสมบัติเด่นของลิสต์คือเวลาที่ใช้ในการหาองค์ประกอบขึ้นอยู่กับว่าองค์ประกอบนั้นอยู่ที่ตำแหน่งใดในลิสต์ ในตัวอย่างนี้ Selden จะถูกพบในขั้นตอนที่สี่ โดยทั่วไปแล้ว การหาองค์ประกอบอาจต้องเดินทางผ่านทั้งลิสต์ เนื่องจากองค์ประกอบอาจอยู่ตำแหน่งสุดท้าย ในการอภิปรายเกี่ยวกับความซับซ้อนด้านเวลาการทำงานใน บทที่ 2 อัลกอริทึมดังกล่าวเรียกว่า เชิงเส้น (linear) เนื่องจากความซับซ้อนด้านเวลาเป็นสัดส่วนโดยตรงกับจำนวนองค์ประกอบในลิสต์
ดังที่กล่าวไว้ ยังไม่ชัดเจนว่ารายชื่อของเชอร์ล็อก โฮล์มส์มีผู้ต้องสงสัยในลำดับเฉพาะที่แสดงจริงหรือไม่ และความจริงที่ Selden อยู่ต่อจาก Beryl ก็ไม่ได้มีความหมายอะไร เนื่องจากจุดประสงค์ของลิสต์คือเพียงเพื่อจดจำว่าใครอยู่ในกลุ่มผู้ต้องสงสัยเท่านั้น 3 สิ่งที่สำคัญคือเพียงว่าบุคคลนั้นอยู่ในลิสต์หรือไม่ นั่นหมายความว่าลิสต์ไม่ใช่การแทนข้อมูลที่เหมาะสมสำหรับการจดจำผู้ต้องสงสัยใช่หรือไม่? ไม่ใช่เลย มันเพียงหมายความว่าลิสต์อาจมีข้อมูล (เช่น การเรียงลำดับองค์ประกอบ) ที่ไม่จำเป็นสำหรับงานหนึ่งๆ การสังเกตนี้ชี้ให้เห็นว่าลิสต์เป็นเพียงโครงสร้างข้อมูลหนึ่งในหลายๆ แบบสำหรับการแทนข้อมูลเกี่ยวกับผู้ต้องสงสัย และอาจมีการแทนข้อมูลอื่นๆ ที่สามารถใช้เพื่อจุดประสงค์เดียวกันได้—ตราบใดที่พวกมันสนับสนุนการดำเนินการเดียวกันในการเพิ่ม ลบ และค้นหาองค์ประกอบ การดำเนินการเหล่านี้แสดงถึงข้อกำหนดของสิ่งที่ต้องทำกับข้อมูล
ข้อกำหนดดังกล่าวสำหรับข้อมูล ซึ่งแสดงผ่านชุดของการดำเนินการ เรียกว่า ชนิดข้อมูล (data type) ในวิทยาการคอมพิวเตอร์ ข้อกำหนดสำหรับข้อมูลผู้ต้องสงสัยคือความสามารถในการเพิ่ม ลบ และค้นหาองค์ประกอบ ชนิดข้อมูลนี้เรียกว่า เซต (set)
เซตถูกนำไปใช้อย่างกว้างขวาง เนื่องจากมันสอดคล้องกับภาคแสดง (predicate) ที่เกี่ยวข้องกับปัญหาหรืออัลกอริทึม ตัวอย่างเช่น เซตของผู้ต้องสงสัยสอดคล้องกับภาคแสดง "เป็นผู้ต้องสงสัย" ซึ่งใช้กับบุคคล และสามารถใช้เพื่อยืนยันหรือปฏิเสธข้อความเช่น "Selden เป็นผู้ต้องสงสัย" ขึ้นอยู่กับว่าบุคคลที่ถูกใช้ภาคแสดงนั้นเป็นสมาชิกของเซตหรือไม่ อัลกอริทึมการติดตามก้อนกรวดที่ฮันเซลกับเกรเทลใช้ก็ใช้ภาคแสดงเมื่อมันสั่งว่า "หาก้อนกรวดที่ส่องแสงซึ่งยังไม่เคยถูกเยี่ยมชมมาก่อน" ภาคแสดงในที่นี้คือ "ไม่เคยถูกเยี่ยมชมมาก่อน" มันใช้กับก้อนกรวดและสามารถแทนได้ด้วยเซตที่เริ่มต้นว่างเปล่าและเพิ่มก้อนกรวดลงไปหลังจากที่พวกมันถูกเยี่ยมชมแล้ว
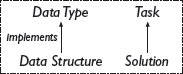
ในขณะที่ชนิดข้อมูลอธิบายข้อกำหนดของสิ่งที่ต้องทำกับข้อมูล โครงสร้างข้อมูลเป็นการนำเสนอที่เป็นรูปธรรมเพื่อสนับสนุนข้อกำหนดเหล่านี้ คุณสามารถคิดว่าชนิดข้อมูลเป็นคำอธิบายของงานจัดการข้อมูล และโครงสร้างข้อมูลเป็นวิธีแก้ปัญหาสำหรับงานนั้น (อุปกรณ์ช่วยจำต่อไปนี้อาจช่วยให้จำความหมายของสองคำนี้ได้: ชนิดข้อมูล (data t ype) อธิบาย ง าน (task); โครงสร้างข้อมูล (data s tructure) อธิบาย ว ิธีแก้ (solution)) ชนิดข้อมูลเป็นคำอธิบายการจัดการข้อมูลที่เป็นนามธรรมกว่าโครงสร้างข้อมูล และมีข้อดีที่รายละเอียดบางอย่างสามารถละไว้ได้ ซึ่งนำไปสู่คำอธิบายที่สั้นกะทัดรัดและทั่วไป ใน The Hound of the Baskervilles ชนิดข้อมูลเซตสะท้อนถึงงานในการดูแลรักษากลุ่มผู้ต้องสงสัยโดยไม่ต้องบอกอย่างละเอียดว่าจะนำไปใช้งานอย่างไร ในเรื่องราวของฮันเซลกับเกรเทล ชนิดข้อมูลเซตเพื่อจดจำก้อนกรวดที่เยี่ยมชมแล้วก็เพียงพอที่จะอธิบายอัลกอริทึม อย่างไรก็ตาม ในการดำเนินการตามที่ชนิดข้อมูลกำหนดไว้จริงๆ คอมพิวเตอร์จำเป็นต้องใช้โครงสร้างข้อมูลที่เป็นรูปธรรมซึ่งกำหนดว่าการดำเนินการต่างๆ ทำงานอย่างไรบนการนำเสนอที่โครงสร้างข้อมูลจัดให้ นอกจากนี้ เฉพาะเมื่อเลือกโครงสร้างข้อมูลที่เป็นรูปธรรมสำหรับอัลกอริทึมแล้วเท่านั้น เราจึงจะสามารถระบุความซับซ้อนด้านเวลาการทำงานของอัลกอริทึมได้
เนื่องจากชนิดข้อมูลหนึ่งชนิดสามารถนำไปใช้งานได้ด้วยโครงสร้างข้อมูลที่แตกต่างกัน คำถามคือควรเลือกโครงสร้างข้อมูลใด เราต้องการโครงสร้างข้อมูลที่ดำเนินการตามชนิดข้อมูลด้วยเวลาการทำงานที่ดีที่สุดเท่าที่จะเป็นไปได้ เพื่อให้อัลกอริทึมที่ใช้โครงสร้างข้อมูลนั้นทำงานได้เร็วที่สุด อย่างไรก็ตาม นี่ไม่ใช่การตัดสินใจที่ง่ายเสมอไป เพราะโครงสร้างข้อมูลอาจสนับสนุนบางการดำเนินการได้ดีแต่ไม่ดีสำหรับการดำเนินการอื่นๆ นอกจากนี้ โครงสร้างข้อมูลยังมีข้อกำหนดด้านพื้นที่ที่แตกต่างกันอีกด้วย สถานการณ์คล้ายกับการเลือกยานพาหนะสำหรับงานขนส่งโดยเฉพาะ จักรยานเป็นมิตรต่อสิ่งแวดล้อม และคุณไม่สามารถเอาชนะอัตราสิ้นเปลืองเชื้อเพลิงที่มันทำได้ต่อแกลลอน แต่มันค่อนข้างช้า สามารถขนส่งได้แค่หนึ่งหรือสองคน และมีระยะทางจำกัด คุณอาจต้องการรถตู้หรือแม้แต่รถบัสสำหรับเดินทางกับคนจำนวนมากในระยะทางไกล คุณเลือกรถกระบะเพื่อขนส่งของชิ้นใหญ่ รถซีดานเพื่อเดินทางอย่างสะดวกสบาย และอาจจะเป็นรถสปอร์ตเมื่อคุณเป็นผู้ชายวัยห้าสิบกว่า
กลับมาที่คำถามว่าจะนำชนิดข้อมูลเซตไปใช้งานอย่างไร ทางเลือกยอดนิยมสองทางแทนการใช้ลิสต์คือโครงสร้างข้อมูล อาร์เรย์ (array) และ ต้นไม้ค้นหาแบบทวิภาค (binary search tree) ต้นไม้ค้นหาแบบทวิภาคจะกล่าวถึงโดยละเอียดใน บทที่ 5 ; ในที่นี้ผมจะเน้นที่อาร์เรย์
ถ้าลิสต์เปรียบเสมือนสมุดห่วง อาร์เรย์ก็เปรียบเสมือนสมุดโน้ตซึ่งมีจำนวนหน้าที่ตายตัวและแต่ละหน้ามีตัวระบุเฉพาะ ช่องแต่ละช่องในโครงสร้างข้อมูลอาร์เรย์เรียกว่า เซลล์ (cell) และตัวระบุของเซลล์ก็เรียกว่า ดัชนี (index) การระบุ (หรือการทำดัชนี) เซลล์มักทำโดยใช้ตัวเลข แต่เราก็สามารถใช้ตัวอักษรหรือชื่อเป็นตัวระบุได้ตราบใดที่เราสามารถเปิดหน้าเฉพาะนั้นได้โดยตรงโดยใช้ตัวระบุ 4 ความสำคัญของโครงสร้างข้อมูลอาร์เรย์อยู่ที่การเข้าถึงเซลล์แต่ละเซลล์ได้อย่างรวดเร็ว ไม่ว่าอาร์เรย์จะมีกี่เซลล์ ก็ใช้เพียงขั้นตอนเดียวในการเข้าถึงเซลล์ การดำเนินการใดๆ ที่ต้องใช้เพียงหนึ่งหรือไม่กี่ขั้นตอน โดยไม่ขึ้นกับขนาดของโครงสร้างข้อมูล เรียกว่าทำงานใน เวลาคงที่ (constant time)

ในการแทนเซตด้วยสมุดโน้ต เราสมมติว่าแต่ละหน้ามีแท็บที่ติดป้ายกำกับด้วยชื่อของสมาชิกที่เป็นไปได้ของเซต ดังนั้นเพื่อแทนผู้ต้องสงสัยใน The Hound of the Baskervilles เราติดป้ายกำกับหน้าต่างๆ ด้วยชื่อของ ผู้ที่อาจเป็น ผู้ต้องสงสัยทั้งหมด นั่นคือ Mortimer, Jack และอื่นๆ สมุดโน้ตยังมีหน้าสำหรับ Desmond และบุคคลอื่นๆ ที่โดยหลักการแล้วสามารถเป็นผู้ต้องสงสัยได้ ซึ่งแตกต่างจากสมุดห่วงที่มีเฉพาะผู้ต้องสงสัยจริงเท่านั้น จากนั้นในการเพิ่ม Selden เป็นผู้ต้องสงสัย เราก็เปิดหน้าที่ติดป้ายว่า "Selden" และทำเครื่องหมายบางอย่างบนนั้น (เช่น เขียน + หรือ "ใช่" ลงไป) ในการลบผู้ต้องสงสัย เราก็เปิดหน้าของบุคคลนั้นเช่นกัน แต่ลบเครื่องหมายทิ้ง (หรือเขียน – หรือ "ไม่" ลงไป) ในการตรวจสอบว่าใครบางคนเป็นผู้ต้องสงสัยหรือไม่ เราไปที่หน้าของพวกเขาและดูเครื่องหมาย อาร์เรย์ทำงานในลักษณะเดียวกัน เราสามารถเข้าถึงเซลล์โดยตรงโดยใช้ดัชนีและอ่านหรือแก้ไขข้อมูลที่เก็บไว้ในนั้น

ความแตกต่างสำคัญระหว่างอาร์เรย์และลิสต์คือ เราสามารถระบุตำแหน่งของเซลล์แต่ละเซลล์ในอาร์เรย์ได้ทันที ในขณะที่เราต้องสแกนองค์ประกอบของลิสต์ตั้งแต่ต้นเพื่อหาองค์ประกอบนั้น (หรือไปจนถึงปลายลิสต์ในกรณีที่องค์ประกอบไม่อยู่ในลิสต์)
เนื่องจากเราสามารถเปิดหน้าเฉพาะในสมุดโน้ตได้โดยตรง (หรือเข้าถึงเซลล์ในอาร์เรย์) การดำเนินการทั้งสามอย่าง—การเพิ่ม ลบ และค้นหาผู้ต้องสงสัย—สามารถทำได้ในเวลาคงที่ ซึ่งเป็นค่าที่เหมาะสมที่สุด: เราไม่สามารถทำสิ่งเหล่านี้ให้เร็วไปกว่านี้ได้อีกแล้ว เนื่องจากโครงสร้างข้อมูลลิสต์ต้องใช้เวลาเชิงเส้นสำหรับการตรวจสอบและการลบผู้ต้องสงสัย โครงสร้างข้อมูลอาร์เรย์จึงดูเหมือนเป็นผู้ชนะอย่างชัดเจน แล้วทำไมเรายังพูดถึงลิสต์กันอยู่ล่ะ?
ปัญหาของอาร์เรย์คือขนาดที่ตายตัว นั่นคือสมุดโน้ตมีจำนวนหน้าที่แน่นอนและไม่สามารถเพิ่มขึ้นได้ตามเวลา สิ่งนี้มีนัยสำคัญสองประการ ประการแรก ต้องเลือกสมุดโน้ตให้ใหญ่พอที่จะบรรจุผู้ต้องสงสัยที่เป็นไปได้ทั้งหมดตั้งแต่เริ่มต้น แม้ว่าหลายคนจะไม่เคยกลายเป็นผู้ต้องสงสัยเลยก็ตาม ดังนั้นเราอาจสิ้นเปลืองพื้นที่เป็นอย่างมาก และอาจพกพาสมุดเล่มใหญ่ที่มีหน้าสำหรับผู้ต้องสงสัยที่มีศักยภาพนับร้อยหรือนับพันหน้า ในขณะที่ในความเป็นจริงเซตของผู้ต้องสงสัยอาจมีขนาดเล็กมาก อาจมีน้อยกว่าสิบคนในเวลาใดเวลาหนึ่ง ซึ่งหมายความว่าการเตรียมดัชนีนิ้วหัวแม่มือของสมุดโน้ตตั้งแต่เริ่มต้นอาจใช้เวลานาน เพราะต้องเขียนชื่อของผู้ต้องสงสัยที่มีศักยภาพแต่ละคนบนหน้าต่างๆ ประการที่สอง—และนี่เป็นปัญหาที่ร้ายแรงยิ่งกว่า—อาจไม่ชัดเจนตั้งแต่ต้นของคดีว่าใครคือผู้ต้องสงสัยที่มีศักยภาพทั้งหมด โดยเฉพาะอย่างยิ่ง ผู้ต้องสงสัยที่มีศักยภาพใหม่อาจเป็นที่รู้จักเมื่อเรื่องราวดำเนินไป ซึ่งเป็นกรณีใน The Hound of the Baskervilles อย่างแน่นอน การขาดข้อมูลนี้ทำให้ไม่สามารถใช้สมุดโน้ตได้ เนื่องจากการเริ่มต้นใช้งานมันเป็นไปไม่ได้
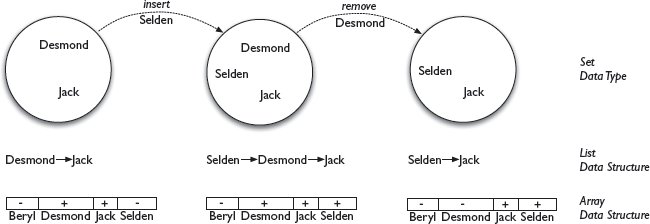
รูปที่ 4.1 ชนิดข้อมูลหนึ่งชนิดสามารถนำไปใช้งานได้ด้วยโครงสร้างข้อมูลที่แตกต่างกัน การแทรกองค์ประกอบลงในลิสต์สามารถทำได้โดยเพียงแค่เพิ่มมันที่ด้านหน้าของลิสต์ แต่การลบต้องเดินทางผ่านลิสต์เพื่อหามัน สำหรับอาร์เรย์ การแทรกและการลบทำได้โดยการเข้าถึงเซลล์อาร์เรย์โดยตรงด้วยดัชนีขององค์ประกอบและเปลี่ยนเครื่องหมายตามนั้น อาร์เรย์ช่วยให้การนำไปใช้งานเร็วกว่า แต่ลิสต์ประหยัดพื้นที่มากกว่า
จุดอ่อนของอาร์เรย์ที่เทอะทะนี้คือจุดแข็งของลิสต์ที่คล่องแคล่ว ซึ่งสามารถเติบโตและหดตัวตามเวลาที่ต้องการ และไม่เคยเก็บองค์ประกอบเกินความจำเป็น ในการเลือกโครงสร้างข้อมูลสำหรับนำชนิดข้อมูลเซตไปใช้งาน เราต้องตระหนักถึงข้อแลกเปลี่ยนต่อไปนี้ อาร์เรย์ให้การนำเซตไปใช้งานที่รวดเร็วมาก แต่สิ้นเปลืองพื้นที่และอาจใช้ไม่ได้ในทุกสถานการณ์ ลิสต์ประหยัดพื้นที่กว่าอาร์เรย์และทำงานได้ในทุกสถานการณ์ แต่นำบางการดำเนินการไปใช้ได้มีประสิทธิภาพน้อยกว่า สถานการณ์สรุปได้ใน รูปที่ 4.1 .
Information Gathering (การรวบรวมข้อมูล)
การระบุผู้ต้องสงสัยเป็นเพียงขั้นตอนหนึ่งในการไขปริศนาฆาตกรรม เพื่อจำกัดเซตของผู้ต้องสงสัยให้แคบลง เชอร์ล็อก โฮล์มส์และดร. วัตสันจำเป็นต้องรวบรวมข้อมูลเฉพาะเกี่ยวกับพวกเขา เช่น แรงจูงใจหรือข้อแก้ตัวที่เป็นไปได้ ในกรณีของ Selden ตัวอย่างเช่น ข้อมูลนี้รวมถึงความจริงที่ว่าเขาเป็นนักโทษที่หลบหนี ข้อมูลเพิ่มเติมทั้งหมดนี้ควรถูกจัดเก็บร่วมกับผู้ต้องสงสัยแต่ละคนที่เกี่ยวข้อง เมื่อใช้สมุดโน้ต เชอร์ล็อก โฮล์มส์จะเพิ่มข้อมูลเกี่ยวกับบุคคลบนหน้าที่สงวนไว้สำหรับบุคคลนั้น
การดำเนินการของชนิดข้อมูลเซตไม่สามารถทำเช่นนั้นได้ แต่การเปลี่ยนแปลงเล็กน้อยในการดำเนินการสำหรับการเพิ่มและการค้นหาองค์ประกอบก็เพียงพอที่จะทำให้มันเกิดขึ้นได้ ประการแรก การดำเนินการสำหรับการแทรกองค์ประกอบใช้ข้อมูลสองส่วน: คีย์ (key) สำหรับระบุข้อมูล และข้อมูลเพิ่มเติมที่เกี่ยวข้องกับคีย์ คีย์สำหรับข้อมูลเกี่ยวกับผู้ต้องสงสัยคือชื่อของเขาหรือเธอ ประการที่สอง การดำเนินการสำหรับการค้นหาและลบผู้ต้องสงสัยจะใช้เพียงคีย์เป็นอินพุต ในกรณีของการลบ ชื่อบุคคลและข้อมูลเพิ่มเติมทั้งหมดที่จัดเก็บร่วมกับชื่อนั้นจะถูกลบออก ในกรณีของการค้นหาบุคคล ข้อมูลที่จัดเก็บสำหรับชื่อนั้นจะถูกส่งกลับเป็นผลลัพธ์
การขยายชนิดข้อมูลเซตที่เล็กน้อยแต่สำคัญนี้เรียกว่า ดิกชันนารี (dictionary) เพราะเหมือนกับดิกชันนารีจริงๆ มันช่วยให้เราค้นหาข้อมูลตามคำสำคัญได้ เช่นเดียวกับที่เชอร์ล็อก โฮล์มส์ใช้สมุดรายชื่อแพทย์เพื่อค้นหาประวัติการทำงานของดร. มอร์ติเมอร์ในตอนต้นของ The Hound of the Baskervilles ดิกชันนารีสามารถมองได้ว่าเป็นกลุ่มของสัญญาณ และแต่ละคีย์เป็นตัวชี้บอก (signifier) สำหรับข้อมูลที่จัดเก็บร่วมกับมัน ชนิดข้อมูลดิกชันนารีแตกต่างจากดิกชันนารีที่พิมพ์ออกมาแบบดั้งเดิมในสองด้าน ประการแรก เนื้อหาของดิกชันนารีที่พิมพ์แล้วจะตายตัว ในขณะที่ชนิดข้อมูลดิกชันนารีสามารถเปลี่ยนแปลงได้—สามารถเพิ่มคำนิยามใหม่ ลบคำนิยามที่ล้าสมัย และปรับปรุงคำนิยามที่มีอยู่ได้ ประการที่สอง รายการในดิกชันนารีที่พิมพ์แล้วจะเรียงตามตัวอักษรตามคีย์ ในขณะที่ไม่จำเป็นต้องเรียงสำหรับชนิดข้อมูลดิกชันนารี การเรียงลำดับรายการในดิกชันนารีที่พิมพ์แล้วเป็นสิ่งจำเป็นเนื่องจากจำนวนรายการจำนวนมากทำให้ไม่สามารถเข้าถึงหน้าเฉพาะโดยตรงได้ เนื่องจากดัชนีนิ้วหัวแม่มือที่เข้าถึงแต่ละหน้าจะมีรายการมากเกินไปและต้องเล็กเกินไปจนไม่สามารถใช้งานได้จริง คีย์ที่เรียงลำดับแล้วช่วยให้ผู้ใช้ดิกชันนารีค้นหารายการโดยใช้อัลกอริทึมการค้นหา (ดู บทที่ 5 )
ข้อจำกัดทั้งสองของดิกชันนารีทางกายภาพ ทั้งความจำเป็นในการมีคีย์ที่เรียงลำดับและขนาดและเนื้อหาที่ตายตัว ไม่มีผลกับดิกชันนารีอิเล็กทรอนิกส์ ดิกชันนารีแบบพลวัตที่ใช้กันอย่างแพร่หลายคือวิกิพีเดีย 5 ซึ่งไม่เพียงให้คุณใช้งานมันเท่านั้น แต่ยังขยายและปรับปรุงข้อมูลในนั้นด้วย ที่จริงแล้ว เนื้อหาของวิกิพีเดียถูกรวบรวมโดยผู้ใช้ของมัน ซึ่งเป็นความสำเร็จที่โดดเด่นของ crowdsourcing และเป็นข้อพิสูจน์ถึงพลังของความร่วมมือ ถ้าเชอร์ล็อก โฮล์มส์และวัตสันทำงานในคดี The Hound of the Baskervilles ในทุกวันนี้ พวกเขาอาจจะใช้ wiki 6 สำหรับการดูแลรักษาข้อมูลเกี่ยวกับผู้ต้องสงสัยและคดีแทนการส่งจดหมายไปมา
ลักษณะพลวัตของดิกชันนารีไม่ได้จำกัดเพียงการแทรกและลบข้อมูลเกี่ยวกับผู้ต้องสงสัยเท่านั้น มันยังอนุญาตให้ปรับปรุงข้อมูลนั้นได้อีกด้วย ตัวอย่างเช่น ความจริงที่ว่านักโทษที่หลบหนี Selden เป็นพี่ชายของ Eliza Barrymore ไม่เป็นที่ทราบเมื่อ Selden กลายเป็นผู้ต้องสงสัยและต้องถูกเพิ่มเข้าไปในรายการดิกชันนารีที่มีอยู่ของเขาในภายหลัง แต่จะทำเช่นนี้ได้อย่างไร? เนื่องจากเรามีเพียงสามการดำเนินการสำหรับการเพิ่ม ลบ และค้นหารายการในดิกชันนารี เราจะปรับปรุงข้อมูลเมื่อมันถูกจัดเก็บกับคีย์ในดิกชันนารีแล้วได้อย่างไร? เราสามารถบรรลุสิ่งนี้ได้โดยการรวมการดำเนินการ: ค้นหารายการโดยใช้คีย์ นำข้อมูลที่ส่งกลับมา แก้ไขตามต้องการ ลบรายการออกจากดิกชันนารี และสุดท้ายเพิ่มกลับเข้ามาพร้อมข้อมูลที่ปรับปรุงแล้ว
เราสามารถเพิ่มการดำเนินการใหม่ให้กับชนิดข้อมูลเซตได้ในลักษณะเดียวกัน ตัวอย่างเช่น ถ้าเชอร์ล็อก โฮล์มส์ดูแลเซตของบุคคลที่ได้รับประโยชน์จากการตายของเซอร์ชาร์ลส์ เขาอาจต้องการเพิ่มแรงจูงใจให้กับผู้ต้องสงสัยบางคน ในการทำเช่นนั้นเขาสามารถคำนวณตัวร่วม (intersection) ของเซตผู้รับประโยชน์กับเซตผู้ต้องสงสัย หรือบางทีเขาอาจต้องการระบุผู้ต้องสงสัยใหม่โดยการหาผู้รับประโยชน์ที่ไม่อยู่ในเซตผู้ต้องสงสัย ในการทำเช่นนั้นเขาสามารถคำนวณผลต่างเซต (set difference) ระหว่างสองเซต สมมติว่าชนิดข้อมูลเซตมีการดำเนินการสำหรับรายงานองค์ประกอบทั้งหมดในเซต อัลกอริทึมสำหรับการคำนวณตัวร่วมหรือผลต่างเซตของสองเซตก็แค่เดินทางผ่านองค์ประกอบทั้งหมดของเซตหนึ่ง และสำหรับแต่ละองค์ประกอบตรวจสอบว่ามันอยู่ในเซตที่สองหรือไม่ ถ้าอยู่ ก็รายงานองค์ประกอบนั้นเป็นผลลัพธ์ของตัวร่วมเซต ถ้าไม่อยู่ ก็รายงานองค์ประกอบนั้นเป็นผลลัพธ์ของผลต่างเซต การคำนวณเช่นนี้พบได้บ่อย เนื่องจากมันสอดคล้องกับการรวมกันของภาคแสดง ตัวอย่างเช่น ตัวร่วมของเซตผู้ต้องสงสัยและเซตผู้รับประโยชน์สอดคล้องกับภาคแสดง "เป็นผู้ต้องสงสัย และ เป็นผู้รับประโยชน์" และผลต่างระหว่างผู้รับประโยชน์และผู้ต้องสงสัยสอดคล้องกับภาคแสดง "เป็นผู้รับประโยชน์ และไม่ใช่ ผู้ต้องสงสัย"
สุดท้าย เราต้องการโครงสร้างข้อมูลเพื่อนำดิกชันนารีไปใช้เพื่อให้เราสามารถคำนวณกับมันได้จริง เนื่องจากชนิดข้อมูลดิกชันนารีแตกต่างจากชนิดข้อมูลเซตเพียงแค่การเชื่อมโยงข้อมูลเพิ่มเติมกับองค์ประกอบ โครงสร้างข้อมูลส่วนใหญ่สำหรับเซต รวมถึงอาร์เรย์และลิสต์ สามารถขยายเพื่อนำดิกชันนารีไปใช้ได้เช่นกัน นี่เป็นจริงสำหรับโครงสร้างข้อมูลทั้งหมดที่แทนองค์ประกอบแต่ละตัวของเซตอย่างชัดเจน เพราะในกรณีนั้นเราสามารถเพิ่มข้อมูลเพิ่มเติมเข้าไปกับคีย์ได้ นอกจากนี้ยังหมายความว่าโครงสร้างข้อมูลใดๆ สำหรับการนำดิกชันนารีไปใช้สามารถใช้เพื่อนำเซตไปใช้ได้ เราสามารถเก็บข้อมูลว่างเปล่าหรือข้อมูลที่ไม่มีความหมายร่วมกับคีย์ได้
When Order Matters (เมื่อลำดับมีความสำคัญ)
ดังที่กล่าวใน บทที่ 3 การคำนวณจะดีได้เท่ากับการแทนข้อมูลที่มันทำงานด้วยเท่านั้น ดังนั้นเชอร์ล็อก โฮล์มส์และวัตสันต้องการให้เซตผู้ต้องสงสัยสะท้อนสถานะการสืบสวนของพวกเขาอย่างแม่นยำ โดยเฉพาะ พวกเขาต้องการให้เซตเล็กที่สุดเท่าที่จะเป็นไปได้ (เพื่อหลีกเลี่ยงการเสียเวลากับเบาะแสเท็จ) 7 แต่ก็ใหญ่เท่าที่จำเป็น (เพื่อไม่ให้ฆาตกรหลุดรอดไปได้) แต่นอกเหนือจากนั้น ลำดับที่ผู้ต้องสงสัยถูกเพิ่มหรือลบออกจากเซตนั้นไม่สำคัญสำหรับพวกเขาเลย
สำหรับงานอื่นๆ ลำดับของรายการในการแทนข้อมูลนั้นสำคัญจริงๆ ตัวอย่างเช่น ทายาทของเซอร์ชาร์ลส์ผู้ล่วงลับ ความแตกต่างระหว่างคนแรกและคนที่สองในลำดับการรับมรดกคือสิทธิในมรดกมูลค่าหนึ่งล้านปอนด์ ข้อมูลนี้ไม่เพียงสำคัญสำหรับการตัดสินว่าใครรวยและใครไม่รวยเท่านั้น แต่ยังให้เบาะแสแก่โฮล์มส์และวัตสันเกี่ยวกับแรงจูงใจที่เป็นไปได้ของผู้ต้องสงสัยอีกด้วย ที่จริงแล้ว ฆาตกรสเตเปิลตันเป็นทายาทลำดับที่สองและพยายามฆ่าทายาทคนแรกคือเซอร์เฮนรี แม้ว่าลำดับของทายาทจะมีความสำคัญ แต่การเรียงลำดับทายาทไม่ได้ถูกกำหนดโดยเวลาที่คนเข้าสู่กลุ่มทายาท ตัวอย่างเช่น เมื่อเด็กเกิดมาแก่ผู้ทำพินัยกรรม เด็กคนนั้นจะไม่กลายเป็นคนสุดท้ายในลำดับ แต่กลับได้ลำดับก่อนหน้า เช่น หลานชาย ชนิดข้อมูลที่การเรียงลำดับองค์ประกอบไม่ได้ถูกกำหนดโดยเวลาในการเข้าแต่โดยเกณฑ์อื่นเรียกว่า คิวลำดับความสำคัญ (priority queue) ชื่อบ่งบอกว่าตำแหน่งขององค์ประกอบในคิวถูกกำหนดโดยลำดับความสำคัญบางอย่าง เช่น ความสัมพันธ์กับผู้ทำพินัยกรรมในกรณีของทายาท หรือความรุนแรงของการบาดเจ็บของผู้ป่วยในห้องฉุกเฉิน
ในทางตรงกันข้าม ถ้าเวลาในการเข้าเป็นตัวกำหนดตำแหน่งในกลุ่ม ชนิดข้อมูลนั้นเรียกว่า คิว (queue) ถ้าองค์ประกอบถูกลบในลำดับที่ถูกเพิ่ม หรือ สแต็ก (stack) ถ้าถูกลบในลำดับตรงกันข้าม คิวคือสิ่งที่คุณพบในซูเปอร์มาร์เก็ต ร้านกาแฟ หรือจุดตรวจความปลอดภัยที่สนามบิน คุณเข้าที่ปลายด้านหนึ่งและออกที่อีกด้านหนึ่ง ผู้คนจะได้รับบริการ (แล้วออกจากคิว) ตามลำดับที่พวกเขาเข้าไป ดังนั้นชนิดข้อมูลคิวจึงกำหนดนโยบายมาก่อนได้บริการก่อน ลำดับที่องค์ประกอบเข้าและออกจากคิวเรียกอีกอย่างว่า FIFO หรือ first in, first out (เข้าครั้งแรกออกครั้งแรก)
ในสแต็ก องค์ประกอบจะออกในลำดับตรงกันข้ามกับที่ถูกเพิ่ม ตัวอย่างที่ดีคือกองหนังสือบนโต๊ะของคุณ หนังสือที่อยู่บนสุด ซึ่งถูกวางบนกองเป็นเล่มสุดท้าย จะต้องถูกหยิบออกก่อนที่จะเข้าถึงหนังสือเล่มอื่นๆ เมื่อคุณมีที่นั่งติดหน้าต่างในเครื่องบิน คุณจะอยู่ที่ด้านล่างของสแต็กในเรื่องของการเข้าห้องน้ำ คนที่นั่งกลางซึ่งนั่งลงทีหลังคุณต้องออกจากแถวก่อนคุณถึงจะออกได้ และพวกเขาต้องรอให้คนที่นั่งริมทางเดินซึ่งนั่งลงทีหลังและอยู่บนสุดของสแต็กออกก่อน ตัวอย่างอื่นคือลำดับที่ฮันเซลและเกรเทลวางและเยี่ยมชมก้อนกรวด ก้อนกรวดที่วางทีหลังคือก้อนที่พวกเขาเยี่ยมชมก่อน และถ้าพวกเขาใช้อัลกอริทึมที่ปรับปรุงแล้วเพื่อหลีกเลี่ยงการวนซ้ำ ก้อนกรวดที่วางทีหลังคือก้อนแรกที่พวกเขาหยิบขึ้นมา
เมื่อแรกเห็น การใช้ชนิดข้อมูลสแต็กดูเหมือนเป็นวิธีที่แปลกในการประมวลผลข้อมูล แต่สแต็กนั้นดีมากสำหรับการรักษาความเป็นระเบียบ สำหรับฮันเซลและเกรเทล กองก้อนกรวดช่วยให้พวกเขาสามารถไปยังสถานที่ที่พวกเขาเคยอยู่ก่อนหน้านี้ได้อย่างเป็นระบบ ซึ่งในที่สุดก็นำพวกเขากลับไปยังบ้านของพวกเขา ในทำนองเดียวกัน ธีซีอัสหนีออกจากเขาวงกตของมิโนทอร์ด้วยความช่วยเหลือของด้ายที่อาเรียดน์ให้ไว้: การคลี่ด้ายออกเปรียบเสมือนการเพิ่มด้ายทีละนิ้วลงในสแต็ก และการออกจากเขาวงกตโดยการพันด้ายกลับเปรียบเสมือนการเอาด้ายออกจากสแต็ก ถ้าในชีวิตประจำวันเราถูกขัดจังหวะในงานหนึ่งโดย เช่น สายโทรศัพท์ ซึ่งถูกขัดจังหวะอีกครั้งโดย เช่น มีคนมาเคาะประตู เราจะเก็บงานเหล่านั้นไว้ในสแต็กในใจ และเราจะทำงานสุดท้ายให้เสร็จก่อนแล้วค่อยกลับไปทำงานก่อนหน้า ลำดับที่องค์ประกอบเข้าและออกจากสแต็กจึงเรียกว่า LIFO หรือ last in, first out (เข้าหลังออกก่อน) และเพื่อให้ครบชุด เราอาจเรียกลำดับที่องค์ประกอบเข้าและออกจากคิวลำดับความสำคัญว่า HIFO หรือ highest (priority) in, first out (ลำดับความสำคัญสูงสุดเข้า, ออกก่อน)
เช่นเดียวกับชนิดข้อมูลเซตและดิกชันนารี เราอยากรู้ว่าโครงสร้างข้อมูลใดบ้างที่สามารถใช้ในการนำชนิดข้อมูลคิว (ลำดับความสำคัญ) และสแต็กไปใช้ มันง่ายที่จะเห็นว่าสแต็กสามารถนำไปใช้ได้ดีด้วยลิสต์: โดยการเพิ่มและลบองค์ประกอบที่ด้านหน้าของลิสต์เสมอ เราก็จะได้ลำดับ LIFO และการดำเนินการนี้ใช้เวลาเพียงค่าคงที่ ในทำนองเดียวกัน โดยการเพิ่มองค์ประกอบที่ปลายลิสต์และลบที่ด้านหน้า เราก็จะได้พฤติกรรม FIFO ของคิว นอกจากนี้ยังสามารถนำคิวและสแต็กไปใช้ด้วยอาร์เรย์ได้อีกด้วย
คิวและสแต็กรักษาลำดับขององค์ประกอบระหว่างที่พวกมันอยู่ในโครงสร้างข้อมูล และดังนั้นจึงแสดงรูปแบบการออกจากโครงสร้างข้อมูลที่คาดเดาได้ การต่อแถวรอตรวจความปลอดภัยที่สนามบินมักจะค่อนข้างน่าเบื่อ สิ่งต่างๆ จะน่าตื่นเต้นมากขึ้นเมื่อมีคนแทรกแถวหรือเมื่อมีช่องพิเศษสำหรับลูกค้าสำคัญ พฤติกรรมนี้สะท้อนให้เห็นในชนิดข้อมูลคิวลำดับความสำคัญ
It Runs in the Family (มันสืบทอดในครอบครัว)
ทายาทของเซอร์ชาร์ลส์ แบสเกอร์วิลล์เป็นตัวอย่างที่ดีของคิวลำดับความสำคัญ เกณฑ์ลำดับความสำคัญที่กำหนดตำแหน่งของทายาทแต่ละคนในคิวคือระยะห่างจากเซอร์ชาร์ลส์ผู้ล่วงลับ แต่จะกำหนดระยะห่างนี้ได้อย่างไร? กฎการสืบทอดแบบง่ายทั่วไปกล่าวว่าบุตรหลานของผู้ตายเป็นลำดับแรกในการรับมรดกตามลำดับอายุของพวกเขา สมมติว่าความมั่งคั่งของผู้ตายถูกสืบทอดต่อไป กฎนี้หมายความว่าถ้าผู้ตายไม่มีบุตร พี่น้องคนโตจะสืบทอดต่อไป ตามด้วยบุตรของพวกเขา และถ้าไม่มีพี่น้อง การสืบทอดจะดำเนินต่อไปด้วยป้าและลุงคนโตและบุตรของพวกเขา และอื่นๆ
กฎนี้สามารถอธิบายในเชิงอัลกอริทึมได้: สมาชิกทุกคนในครอบครัวถูกแทนใน ต้นไม้ (tree) โครงสร้างข้อมูลที่สะท้อนความสัมพันธ์บรรพบุรุษ/ลูกหลานของพวกเขา จากนั้นอัลกอริทึมสำหรับการเดินทางผ่านต้นไม้จะสร้างลิสต์ของสมาชิกครอบครัวซึ่งตำแหน่งของบุคคลกำหนดลำดับความสำคัญในการรับมรดกของพวกเขา ลำดับความสำคัญนี้จะเป็นเกณฑ์ที่ใช้ในคิวลำดับความสำคัญของทายาท แต่ถ้าเรามีลิสต์ทายาทที่สมบูรณ์และเรียงลำดับอย่างถูกต้องแล้ว ทำไมเราต้องใช้คิวลำดับความสำคัญ? คำตอบคือเราไม่จำเป็นต้องใช้ เราต้องการคิวลำดับความสำคัญก็ต่อเมื่อต้นไม้ครอบครัวทั้งหมดไม่เป็นที่รู้จักตั้งแต่แรก หรือเมื่อมันเปลี่ยนแปลง เช่น เมื่อมีเด็กเกิด ในกรณีนั้นต้นไม้ครอบครัวจะเปลี่ยนไป และลิสต์ที่คำนวณจากต้นไม้เก่าจะไม่สะท้อนลำดับการสืบทอดที่ถูกต้อง
ข้อมูลที่ให้ใน The Hound of the Baskervilles บ่งชี้ว่า Hugo Baskerville คนเก่ามีบุตรสี่คน Charles เป็นบุตรคนโตและสืบทอดจาก Hugo John พี่ชายคนรองลงมามีบุตรชายหนึ่งคนชื่อ Henry และ Rodger น้องชายคนเล็กมีบุตรชายหนึ่งคนคือ Stapleton เรื่องราวกล่าวถึงว่า Hugo Baskerville มีบุตรสาวชื่อ Elizabeth ซึ่งผมขอสมมติว่าเป็นบุตรคนเล็ก ชื่อในต้นไม้เรียกว่า โหนด (node) และเช่นเดียวกับในต้นไม้ครอบครัว เมื่อโหนด B (เช่น John) เชื่อมต่อกับโหนด A ที่อยู่เหนือขึ้นไป (เช่น Hugo) B เรียกว่า โหนดลูก (child) ของ A และ A เรียกว่า โหนดแม่ (parent) ของ B โหนดบนสุดของต้นไม้ซึ่งไม่มีบิดามารดาเรียกว่า ราก (root) และโหนดที่ไม่มีบุตรเรียกว่า ใบ (leaf)
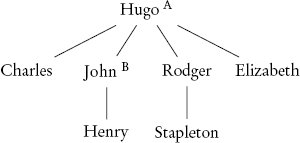
กฎการสืบทอดที่ใช้กับต้นไม้ครอบครัวแบสเกอร์วิลล์กล่าวว่า Charles, John, Rodger และ Elizabeth ควรสืบทอดจาก Hugo ตามลำดับดังกล่าว เนื่องจากกฎยังบอกว่าบุตรควรสืบทอดก่อนพี่น้อง ดังนั้น Henry อยู่ในลำดับก่อน Rodger และ Stapleton มาก่อน Elizabeth กล่าวอีกนัยหนึ่ง ลิสต์ลำดับทายาทควรเป็นดังนี้:
Hugo → Charles → John → Henry → Rodger → Stapleton → Elizabeth
ลิสต์การสืบทอดนี้สามารถคำนวณได้โดยการเดินทางผ่านต้นไม้ในลำดับเฉพาะ ซึ่งจะเยี่ยมชมแต่ละโหนดก่อนโหนดลูกของมัน การเดินทางผ่านนี้ยังเยี่ยมชมหลานของบุตรคนโตก่อนที่จะเยี่ยมชมบุตรคนเล็ก (และหลานของพวกเขา) อัลกอริทึมสำหรับการคำนวณลิสต์การสืบทอดสำหรับโหนดในต้นไม้สามารถอธิบายได้ดังนี้:
ในการคำนวณลิสต์การสืบทอดสำหรับโหนด N ให้คำนวณและต่อท้ายลิสต์การสืบทอดของโหนดลูกทั้งหมด (จากคนโตไปคนสุดท้อง) และวางโหนด N ไว้ที่จุดเริ่มต้นของผลลัพธ์
คำอธิบายนี้หมายความว่าลิสต์การสืบทอดสำหรับโหนดที่ไม่มีบุตรประกอบด้วยโหนดนั้นเพียงอย่างเดียว ดังนั้นลิสต์การสืบทอดสำหรับต้นไม้นั้นจึงได้มาจากการคำนวณลิสต์การสืบทอดสำหรับโหนดรากของมัน อาจดูแปลกที่อัลกอริทึมอ้างถึงตัวเองในคำอธิบายของมันเอง คำอธิบายเช่นนี้เรียกว่า เวียนเกิด (recursive) (ดู บทที่ 12 และ 13 )
ต่อไปนี้แสดงให้เห็นว่าอัลกอริทึมทำงานอย่างไรโดยการจำลองการทำงานบนตัวอย่างต้นไม้ที่มีสมาชิกเพิ่มขึ้นอีกเล็กน้อย สมมติว่า Henry มีบุตรสองคนคือ Jack และ Jill และมีน้องสาวคนเล็กชื่อ Mary:
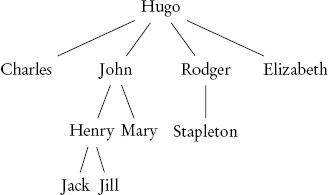
ถ้าเรารันอัลกอริทึมบนต้นไม้นี้ โดยเริ่มจาก Hugo เราต้องคำนวณลิสต์การสืบทอดสำหรับบุตรแต่ละคนของ Hugo เริ่มจากบุตรคนโต ลิสต์การสืบทอดสำหรับ Charles ประกอบด้วยแค่ตัวเขาเองเท่านั้น เนื่องจากเขาไม่มีบุตร สถานการณ์น่าสนใจกว่าสำหรับ John ในการคำนวณลิสต์การสืบทอดของเขา เราต้องคำนวณลิสต์การสืบทอดของ Henry และ Mary และต่อท้ายพวกมันเข้าด้วยกัน ลิสต์การสืบทอดของ Henry ประกอบด้วยบุตรของเขาบวกด้วยตัวเขาเอง และเนื่องจาก Mary ไม่มีบุตร ลิสต์การสืบทอดของเธอจึงมีแค่ตัวเธอเองเท่านั้น จนถึงตอนนี้เราได้คำนวณลิสต์การสืบทอดดังต่อไปนี้:
| โหนด | ลิสต์การสืบทอด |
| Charles | Charles |
| John | John → Henry → Jack → Jill → Mary |
| Henry | Henry → Jack → Jill |
| Mary | Mary |
| Jack | Jack |
| Jill | Jill |
ลิสต์การสืบทอดสำหรับโหนดจะเริ่มต้นด้วยโหนดนั้นเองเสมอ และลิสต์การสืบทอดสำหรับโหนดที่ไม่มีบุตรคือลิสต์ที่มีเพียงโหนดนั้นเท่านั้น นอกจากนี้ ลิสต์การสืบทอดของ Henry และ John แสดงให้เห็นว่าลิสต์การสืบทอดสำหรับโหนดที่มีบุตรได้มาจากการต่อท้ายลิสต์การสืบทอดของบุตรของพวกเขา ลิสต์การสืบทอดสำหรับ Rodger และ Elizabeth คำนวณในลักษณะเดียวกัน และถ้าเราต่อท้ายลิสต์การสืบทอดของบุตรทั้งสี่ของ Hugo โดยเพิ่มเขาที่ด้านหน้า เราจะได้ลิสต์ลำดับทายาทดังต่อไปนี้:
Hugo → Charles → John → Henry → Jack → Jill → Mary → Rodger → Stapleton → Elizabeth
อัลกอริทึมการสืบทอดเป็นตัวอย่างของ การเดินทางผ่านต้นไม้ (tree traversal) ซึ่งเป็นอัลกอริทึมที่เยี่ยมชมโหนดทั้งหมดของต้นไม้อย่างเป็นระบบ เนื่องจากมันดำเนินจากบนลงล่าง จากรากไปยังใบ และเยี่ยมชมโหนดก่อนโหนดลูกของมัน จึงเรียกว่า การเดินทางแบบพรีออร์เดอร์ (preorder traversal) นึกถึงกระรอกที่ค้นหาต้นไม้เพื่อหาผลไม้ เพื่อไม่ให้พลาดผลไม้ใดๆ กระรอกต้องเยี่ยมชมทุกกิ่งของต้นไม้ มันสามารถทำได้โดยใช้กลยุทธ์ที่แตกต่างกัน วิธีหนึ่งคือการปีนต้นไม้เป็นระดับ (ตามความสูง) และเยี่ยมชมทุกกิ่งในระดับหนึ่งก่อนที่จะเยี่ยมชมกิ่งในระดับถัดไป อีกวิธีหนึ่งคือการเดินตามแต่ละกิ่งไปจนสุด ไม่ว่าจะสูงแค่ไหน ก่อนที่จะเปลี่ยนไปยังกิ่งอื่น ทั้งสองกลยุทธ์รับประกันว่าทุกกิ่งจะถูกเยี่ยมชมและทุกผลไม้จะถูกพบ ความแตกต่างคือลำดับที่กิ่งถูกเยี่ยมชม ความแตกต่างนี้ไม่สำคัญสำหรับกระรอก เพราะมันจะเก็บผลไม้ทั้งหมดไม่ว่าจะด้วยวิธีใด แต่ลำดับของการเยี่ยมชมโหนดในต้นไม้ครอบครัวนั้นสำคัญสำหรับเรื่องการสืบทอด เนื่องจากบุคคลแรกที่พบจะได้รับทุกอย่าง การเดินทางแบบพรีออร์เดอร์ของอัลกอริทึมการสืบทอดคือการเดินทางผ่านต้นไม้แบบที่สอง นั่นคือการเดินตามกิ่งจนสุดก่อนแล้วจึงเปลี่ยนไปกิ่งอื่น
การใช้งานหลักของชนิดข้อมูลและการนำไปใช้งานผ่านโครงสร้างข้อมูลคือการรวบรวมข้อมูล ณ จุดหนึ่งในการคำนวณและนำไปใช้ในภายหลัง เนื่องจากการค้นหารายการแต่ละรายการในกลุ่มข้อมูลเป็นการดำเนินการที่สำคัญและใช้บ่อย นักวิทยาการคอมพิวเตอร์จึงทุ่มเทความพยายามอย่างมากในการศึกษาโครงสร้างข้อมูลที่สนับสนุนการดำเนินการนี้อย่างมีประสิทธิภาพ หัวข้อนี้จะถูกสำรวจในเชิงลึกใน บทที่ 5 .